INVITE-ONLY SCRIPT
Edge AI Forecast [Edge Terminal]
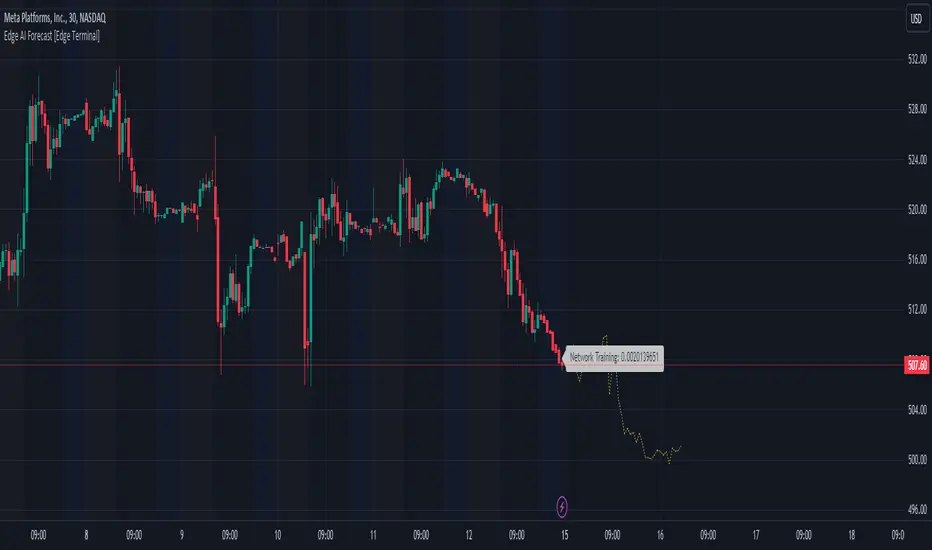
This indicator inputs the previous 150 closing prices in a simple two-layer neural network, normalizes the network inputs using a sigmoid function, uses a feedforward calculation to send it to the second layer, shows the MSE loss curve and uses both automatic and manual backpropagation (user input) to find the most likely forecast values and uses the analog forecasting algorithm to adjust and optimize the data furthermore to display potential prices on the chart.
Here's how it works:
The idea behind this script is to train a simple neural network to predict the future x values based on the sample data. For this, we use 2 types of data, Price and Volume.
The thinking behind this is that price alone can’t be used in this case because it doesn’t provide enough meaningful pattern data for the network but price and volume together can change the game. We’re planning to use more different data sets and expand on this in the future.
To avoid a bad mix of results, we technically have two neural networks, each processing a different data type, one for volume data and one for price data.
The actual prediction is decided by the way price and volume of the closing price relate to each other. Basically, the network passes the price and volume and finds the best relation between the two data set outputs and predicts where the price could be based on the upcoming volume of the latest candle.
The network adjusts the weights and biases using optimization algorithms like gradient descent to minimize the difference between the predicted and actual stock prices, typically measured by a loss function, (in this case, mean squared error) which you can see using the error rate bubble.
This is a good measure to see how well the network is performing and the idea is to adjust the settings inputs such as learning rate, epochs and data source to get the lowest possible error rate. That’s when you’re getting the most accurate prediction results.
For each data set, we use a multi-layer network. In a multi-layer neural network, the outputs of neurons in one layer serve as inputs to neurons in the next layer. Initially, the input layer of the neural network receives the historical data. Each input neuron represents a feature, such as previous stock prices and trading volumes over a specific period.
The hidden layers perform feature extraction and transformation through a series of weighted connections and activation functions. Each neuron in a hidden layer computes a weighted sum of the inputs from the previous layer, applies an activation function to the sum, and passes the result to the next layer using the feedforward (activation) function.
For extraction, we use a normalization function. This function takes a value or data (such as bar price) and divides it up by max scale which is the highest possible value of the bar. The idea is to take a normalized number, which is either below 1 or under 2 for simple use in the neural network layers.
For the activation, after computing the weighted sum, the neuron applies an activation function a(x). To introduce non-linearity into the model to pass it to the next layer. We use sigmoid activation functions in this case. The main reason we use sigmoid function is because the resulting number is between 0 to 1 and is better for models where we have to predict the probability as an output.
The final output of the network is passed as an input to the analog forecasting function. This is an algorithm commonly used in weather prediction systems. In this case, this is used to make predictions by comparing current values and assuming the patterns might repeat in the future.
There are many different ways to build an analog forecasting function but in our case, we’re used similarity measurement model:
X, as the current situation or set of current variables.
Y, as the outcome or variable of interest.
Si as the historical situations or patterns, where i ranges from 1 to n.
Vi as the vector of variables describing historical situation Si.
Oi as the outcome associated with historical situation Si.
First, we define a similarity measure sim(X,Vi) that quantifies the similarity between the current situation X and historical situation Si based on their respective variables Vi.
Then we select the K most similar historical situations (KNN Machine learning) based on the similarity measure sim(X,Vi). We denote the rest of the selected historical situations as {Si1, Si2,...Sik).
Then we examine the outcomes associated with the selected historical situations {Oi1, Oi2,...,Oik}.
Then we use the outcomes of the selected historical situations to forecast the future outcome Y^ using weighted averaging.
Finally, the output value of the analog forecasting is standardized using a standardization function which is the opposite of the normalization function. This function takes a normalized number and turns it back to its original value by multiplying it by the max scale (highest value of the bar). This function is used when the final number is produced by the network output at the end of the analog forecasting to turn the final value back into a price so it can be displayed on the chart with PineScript.
Settings:
Data source: Source of the neural network's input data.
Sample Bars: How many historical bars do you want to input into the neural network
Prediction Bars: How many bars you want the script to forecast
Show Training Rate: This shows the neural network's error rate for the optimization phase
Learning Rate: how many times you want the script to change the model in response to the estimated error (automatic)
Epochs: the network cycle or how many times you want to run the data through the network from the first layer to the last one.
Usage:
The sample bars input determines the number of historical bars to be used as a reference for the network. You need to change the Epochs and Learning Rate inputs for each asset and chart timeframe to get the lowest error rate.
On the surface, the highest possible epoch and learning rate should produce the most effective results but that's not always the case.
If the epochs rate is too high, there is a chance we face overfitting. Essentially, you might be over processing good data which can make it useless.
On the other hand, if the learning rate is too high, the network may overshoot the optimal solution and diverge. This is almost like the same issue I mentioned above with a high epoch rate.
Access:
It took over 4 months to develop this script and we’re constantly improving it so it took a lot of manpower to develop this script. Also when it comes to neural networks, Pine Script isn’t the most optimal language to build a neural network in, so we had to resort to a few proprietary mathematical formulas to ensure this runs smoothly without giving out an error for overprocessing, specially when you have multiple neural networks with many layers.
The optimization done to make this script run on Pine Script is basically state of the art and because of this, we would like to keep the code closed source at the moment.
On the other hand we don’t want to publish the code publicly as we want to keep the trading edge this script gives us in a closed loop, for our own small group of members so we have to keep the code closed. We only accept invites from expert traders who understand how this script and algo trading works and the type of edge it provides.
Additionally, at the moment we don’t want to share the code as some of the parts of this network, specifically the way we hand the data from neural network output into the analog method formula are proprietary code and we’d like to keep it that way.
You can contact us for access and if we believe this works for your trading case, we will provide you with access.
Here's how it works:
The idea behind this script is to train a simple neural network to predict the future x values based on the sample data. For this, we use 2 types of data, Price and Volume.
The thinking behind this is that price alone can’t be used in this case because it doesn’t provide enough meaningful pattern data for the network but price and volume together can change the game. We’re planning to use more different data sets and expand on this in the future.
To avoid a bad mix of results, we technically have two neural networks, each processing a different data type, one for volume data and one for price data.
The actual prediction is decided by the way price and volume of the closing price relate to each other. Basically, the network passes the price and volume and finds the best relation between the two data set outputs and predicts where the price could be based on the upcoming volume of the latest candle.
The network adjusts the weights and biases using optimization algorithms like gradient descent to minimize the difference between the predicted and actual stock prices, typically measured by a loss function, (in this case, mean squared error) which you can see using the error rate bubble.
This is a good measure to see how well the network is performing and the idea is to adjust the settings inputs such as learning rate, epochs and data source to get the lowest possible error rate. That’s when you’re getting the most accurate prediction results.
For each data set, we use a multi-layer network. In a multi-layer neural network, the outputs of neurons in one layer serve as inputs to neurons in the next layer. Initially, the input layer of the neural network receives the historical data. Each input neuron represents a feature, such as previous stock prices and trading volumes over a specific period.
The hidden layers perform feature extraction and transformation through a series of weighted connections and activation functions. Each neuron in a hidden layer computes a weighted sum of the inputs from the previous layer, applies an activation function to the sum, and passes the result to the next layer using the feedforward (activation) function.
For extraction, we use a normalization function. This function takes a value or data (such as bar price) and divides it up by max scale which is the highest possible value of the bar. The idea is to take a normalized number, which is either below 1 or under 2 for simple use in the neural network layers.
For the activation, after computing the weighted sum, the neuron applies an activation function a(x). To introduce non-linearity into the model to pass it to the next layer. We use sigmoid activation functions in this case. The main reason we use sigmoid function is because the resulting number is between 0 to 1 and is better for models where we have to predict the probability as an output.
The final output of the network is passed as an input to the analog forecasting function. This is an algorithm commonly used in weather prediction systems. In this case, this is used to make predictions by comparing current values and assuming the patterns might repeat in the future.
There are many different ways to build an analog forecasting function but in our case, we’re used similarity measurement model:
X, as the current situation or set of current variables.
Y, as the outcome or variable of interest.
Si as the historical situations or patterns, where i ranges from 1 to n.
Vi as the vector of variables describing historical situation Si.
Oi as the outcome associated with historical situation Si.
First, we define a similarity measure sim(X,Vi) that quantifies the similarity between the current situation X and historical situation Si based on their respective variables Vi.
Then we select the K most similar historical situations (KNN Machine learning) based on the similarity measure sim(X,Vi). We denote the rest of the selected historical situations as {Si1, Si2,...Sik).
Then we examine the outcomes associated with the selected historical situations {Oi1, Oi2,...,Oik}.
Then we use the outcomes of the selected historical situations to forecast the future outcome Y^ using weighted averaging.
Finally, the output value of the analog forecasting is standardized using a standardization function which is the opposite of the normalization function. This function takes a normalized number and turns it back to its original value by multiplying it by the max scale (highest value of the bar). This function is used when the final number is produced by the network output at the end of the analog forecasting to turn the final value back into a price so it can be displayed on the chart with PineScript.
Settings:
Data source: Source of the neural network's input data.
Sample Bars: How many historical bars do you want to input into the neural network
Prediction Bars: How many bars you want the script to forecast
Show Training Rate: This shows the neural network's error rate for the optimization phase
Learning Rate: how many times you want the script to change the model in response to the estimated error (automatic)
Epochs: the network cycle or how many times you want to run the data through the network from the first layer to the last one.
Usage:
The sample bars input determines the number of historical bars to be used as a reference for the network. You need to change the Epochs and Learning Rate inputs for each asset and chart timeframe to get the lowest error rate.
On the surface, the highest possible epoch and learning rate should produce the most effective results but that's not always the case.
If the epochs rate is too high, there is a chance we face overfitting. Essentially, you might be over processing good data which can make it useless.
On the other hand, if the learning rate is too high, the network may overshoot the optimal solution and diverge. This is almost like the same issue I mentioned above with a high epoch rate.
Access:
It took over 4 months to develop this script and we’re constantly improving it so it took a lot of manpower to develop this script. Also when it comes to neural networks, Pine Script isn’t the most optimal language to build a neural network in, so we had to resort to a few proprietary mathematical formulas to ensure this runs smoothly without giving out an error for overprocessing, specially when you have multiple neural networks with many layers.
The optimization done to make this script run on Pine Script is basically state of the art and because of this, we would like to keep the code closed source at the moment.
On the other hand we don’t want to publish the code publicly as we want to keep the trading edge this script gives us in a closed loop, for our own small group of members so we have to keep the code closed. We only accept invites from expert traders who understand how this script and algo trading works and the type of edge it provides.
Additionally, at the moment we don’t want to share the code as some of the parts of this network, specifically the way we hand the data from neural network output into the analog method formula are proprietary code and we’d like to keep it that way.
You can contact us for access and if we believe this works for your trading case, we will provide you with access.
仅限邀请脚本
只有作者授权的用户才能访问此脚本。您需要申请并获得使用许可。通常情况下,付款后即可获得许可。更多详情,请按照下方作者的说明操作,或直接联系EdgeTerminal。
TradingView不建议您付费购买或使用任何脚本,除非您完全信任其作者并了解其工作原理。您也可以在我们的社区脚本找到免费的开源替代方案。
作者的说明
Please contact us for access.
Indicators: etlnk.co/indicators
YouTube: youtube.com/@edgeterminal/
YouTube: youtube.com/@edgeterminal/
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。
仅限邀请脚本
只有作者授权的用户才能访问此脚本。您需要申请并获得使用许可。通常情况下,付款后即可获得许可。更多详情,请按照下方作者的说明操作,或直接联系EdgeTerminal。
TradingView不建议您付费购买或使用任何脚本,除非您完全信任其作者并了解其工作原理。您也可以在我们的社区脚本找到免费的开源替代方案。
作者的说明
Please contact us for access.
Indicators: etlnk.co/indicators
YouTube: youtube.com/@edgeterminal/
YouTube: youtube.com/@edgeterminal/
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。