OPEN-SOURCE SCRIPT
Machine Learning: Trend Pulse
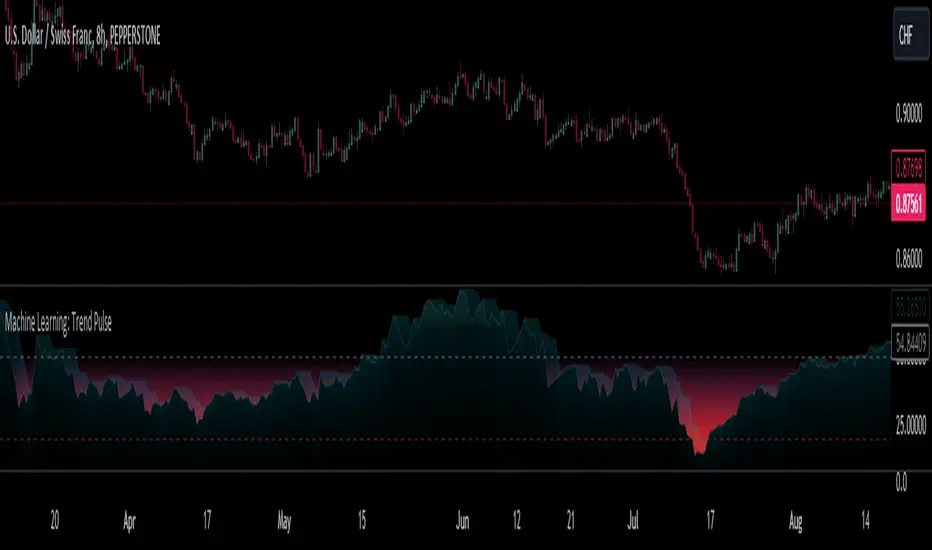
⚠️❗ Important Limitations: Due to the way this script is designed, it operates specifically under certain conditions:
Stocks & Forex: Only compatible with timeframes of 8 hours and above ⏰
Crypto: Only works with timeframes starting from 4 hours and higher ⏰
❗Please note that the script will not work on lower timeframes.❗
Feature Extraction: It begins by identifying a window of past price changes. Think of this as capturing the "mood" of the market over a certain period.
Distance Calculation: For each historical data point, it computes a distance to the current window. This distance measures how similar past and present market conditions are. The smaller the distance, the more similar they are.
Neighbor Selection: From these, it selects 'k' closest neighbors. The variable 'k' is a user-defined parameter indicating how many of the closest historical points to consider.
Price Estimation: It then takes the average price of these 'k' neighbors to generate a forecast for the next stock price.
Z-Score Scaling: Lastly, this forecast is normalized using the Z-score to make it more robust and comparable over time.
Inputs:
histCap (Historical Cap): histCap limits the number of past bars the script will consider. Think of it as setting the "memory" of model—how far back in time it should look.
sampleSpeed (Sampling Rate): sampleSpeed is like a time-saving shortcut, allowing the script to skip bars and only sample data points at certain intervals. This makes the process faster but could potentially miss some nuances in the data.
winSpan (Window Size): This is the size of the "snapshot" of market data the script will look at each time. The window size sets how many bars the algorithm will include when it's measuring how "similar" the current market conditions are to past conditions.
All these variables help to simplify and streamline the k-NN model, making it workable within limitations. You could see them as tuning knobs, letting you balance between computational efficiency and predictive accuracy.
Stocks & Forex: Only compatible with timeframes of 8 hours and above ⏰
Crypto: Only works with timeframes starting from 4 hours and higher ⏰
❗Please note that the script will not work on lower timeframes.❗
Feature Extraction: It begins by identifying a window of past price changes. Think of this as capturing the "mood" of the market over a certain period.
Distance Calculation: For each historical data point, it computes a distance to the current window. This distance measures how similar past and present market conditions are. The smaller the distance, the more similar they are.
Neighbor Selection: From these, it selects 'k' closest neighbors. The variable 'k' is a user-defined parameter indicating how many of the closest historical points to consider.
Price Estimation: It then takes the average price of these 'k' neighbors to generate a forecast for the next stock price.
Z-Score Scaling: Lastly, this forecast is normalized using the Z-score to make it more robust and comparable over time.
Inputs:
histCap (Historical Cap): histCap limits the number of past bars the script will consider. Think of it as setting the "memory" of model—how far back in time it should look.
sampleSpeed (Sampling Rate): sampleSpeed is like a time-saving shortcut, allowing the script to skip bars and only sample data points at certain intervals. This makes the process faster but could potentially miss some nuances in the data.
winSpan (Window Size): This is the size of the "snapshot" of market data the script will look at each time. The window size sets how many bars the algorithm will include when it's measuring how "similar" the current market conditions are to past conditions.
All these variables help to simplify and streamline the k-NN model, making it workable within limitations. You could see them as tuning knobs, letting you balance between computational efficiency and predictive accuracy.
开源脚本
秉承TradingView的精神,该脚本的作者将其开源,以便交易者可以查看和验证其功能。向作者致敬!您可以免费使用该脚本,但请记住,重新发布代码须遵守我们的网站规则。
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。
开源脚本
秉承TradingView的精神,该脚本的作者将其开源,以便交易者可以查看和验证其功能。向作者致敬!您可以免费使用该脚本,但请记住,重新发布代码须遵守我们的网站规则。
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。