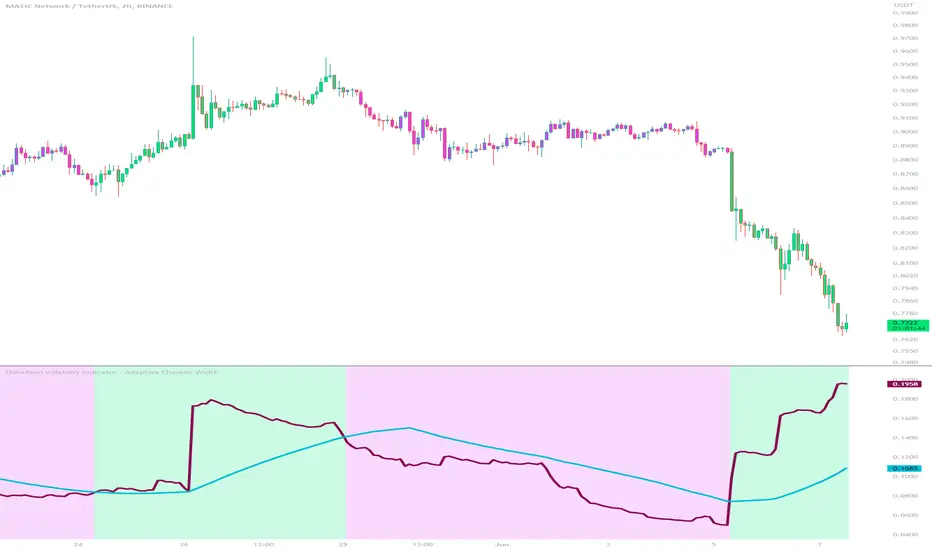
Donchian Volatility Indicator - Adaptive Channel WidthThis indicator is designed to help traders assess and analyze market volatility. By calculating the width of the Donchian channels, it provides valuable insights into the range of price movements over a specified period. This indicator helps traders identify periods of high and low volatility, enabling them to make more informed trading decisions.
The indicator is based on the concept of Donchian channels, which consist of the highest high and lowest low over a specified lookback period. The channel width is calculated as the difference between the upper and lower channels. A wider channel indicates higher volatility, suggesting potentially larger price movements and increased trading opportunities. On the other hand, a narrower channel suggests lower volatility, indicating a relatively calmer market environment with potentially fewer trading opportunities.
The adaptive aspect of the indicator refers to its ability to adjust the width of the channels dynamically based on market conditions. The indicator calculates the width of the channels using the Average True Range (ATR) indicator, which measures the average range of price movements over a specified period. By multiplying the ATR value with the user-defined ATR multiplier, the indicator adapts the width of the channels to reflect the current level of volatility. During periods of higher volatility, the channels expand to accommodate larger price movements, providing a broader range for assessing volatility. Conversely, during periods of lower volatility, the channels contract, reflecting the narrower price ranges and signaling a decrease in volatility. This adaptive nature allows traders to have a flexible and responsive measure of volatility, ensuring that the indicator reflects the current market conditions accurately.
To provide further insights, the indicator includes a signal line. The signal line is derived from the channel width and is calculated as a simple moving average over a specified signal period. This signal line acts as a reference level, allowing traders to compare the current channel width with the average width over a given time frame. By assessing whether the current channel width is above or below the signal line, traders can gain additional context on the volatility level in the market.
The colors used in the Donchian Volatility Indicator - Adaptive Channel Width play a vital role in visualizing the volatility levels:
-- Lime Color : When the channel width is above the signal line, it is colored lime. This color signifies that volatility has entered the market, indicating potentially higher price movements and increased trading opportunities. Traders can pay closer attention to the lime-colored channel width as it may suggest favorable conditions for trend-following or breakout trading strategies.
-- Fuchsia Color : When the channel width is below the signal line, it is colored fuchsia. This color represents relatively low volatility, suggesting a calmer market environment with potentially fewer trading opportunities. Traders may consider adjusting their strategies during periods of low volatility, such as employing range-bound or mean-reversion strategies.
-- Aqua Color : The signal line is represented by the aqua color. This color allows traders to easily identify the signal line amidst the channel width. The aqua color provides a visual reference for the average channel width and helps traders assess whether the current width is above or below this average.
The Donchian Volatility Indicator - Adaptive Channel Width has several practical applications for traders:
-- Volatility Assessment : Traders can use this indicator to assess the level of volatility in the market. By observing the width of the Donchian channels and comparing it to the signal line, they can determine whether the current volatility is relatively high or low. This information helps traders set appropriate expectations and adjust their trading strategies accordingly.
-- Breakout Trading : Wide channel widths may indicate an increased likelihood of price breakouts. Traders can use the Donchian Volatility Indicator - Adaptive Channel Width to identify potential breakout opportunities. When the channel width exceeds the signal line, it suggests a higher probability of significant price movements, potentially signaling a breakout. Traders may consider entering trades in the direction of the breakout.
-- Risk Management : The indicator can assist in setting appropriate stop-loss levels based on the current volatility. During periods of high volatility (lime-colored channel width), wider stop-loss orders may be warranted to account for larger price swings. Conversely, during periods of low volatility (fuchsia-colored channel width), narrower stop-loss orders may be appropriate to limit risk in a more range-bound market.
While the Donchian Volatility Indicator - Adaptive Channel Width is a valuable tool, it is important to consider its limitations:
-- Lagging Indicator : The indicator relies on historical price data, making it a lagging indicator. It provides insights based on past price movements and may not capture sudden changes or shifts in volatility. Traders should be aware that the indicator may not generate real-time signals and should be used in conjunction with other indicators and analysis tools.
-- False Signals : Like any technical indicator, the Donchian Volatility Indicator - Adaptive Channel Width is not immune to generating false signals. Traders should exercise caution and use additional analysis to confirm the signals generated by the indicator. Considering the broader market context and employing risk management techniques can help mitigate the impact of false signals.
-- Market Conditions : Market conditions can vary, and volatility levels can differ across different assets and timeframes. Traders should adapt their strategies and consider other market factors when interpreting the signals provided by the indicator. It is crucial to avoid relying solely on the indicator and to incorporate a comprehensive analysis of the market environment.
In conclusion, this indicator is a powerful tool for assessing market volatility. By examining the width of the Donchian channels and comparing it to the signal line, traders can gain insights into the level of volatility and adjust their trading strategies accordingly. The color-coded representation of the channel width and signal line allows for easy visualization and interpretation of the volatility dynamics. Traders should utilize this indicator as part of a broader trading approach, incorporating other technical analysis tools and considering market conditions for a comprehensive assessment of market volatility.
Adaptive
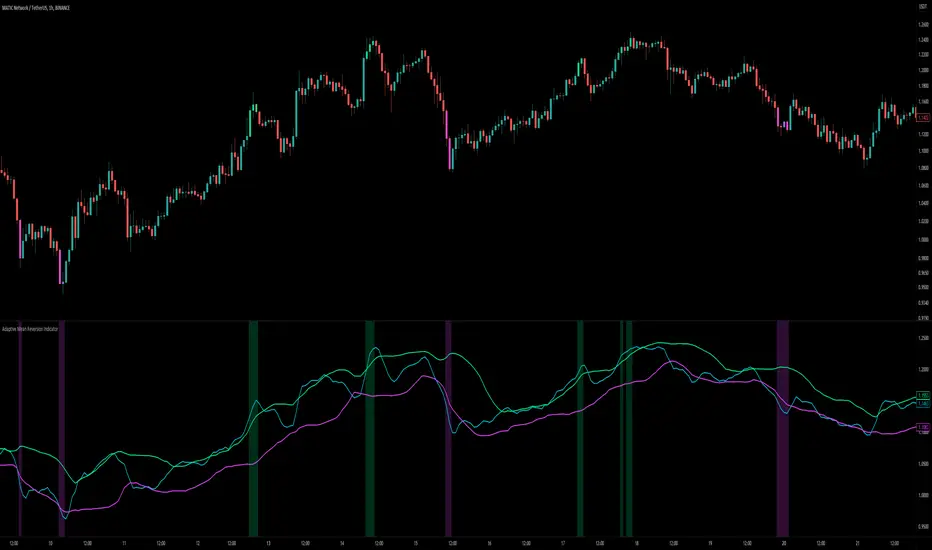
Adaptive Mean Reversion IndicatorThe Adaptive Mean Reversion Indicator is a tool for identifying mean reversion trading opportunities in the market. The indicator employs a dynamic approach by adapting its parameters based on the detected market regime, ensuring optimal performance in different market conditions.
To determine the market regime, the indicator utilizes a volatility threshold. By comparing the average true range (ATR) over a 14-period to the specified threshold, it determines whether the market is trending or ranging. This information is crucial as it sets the foundation for parameter optimization.
The parameter optimization process is an essential step in the indicator's calculation. It dynamically adjusts the lookback period and threshold level based on the identified market regime. In trending markets, a longer lookback period and higher threshold level are chosen to capture extended trends. In ranging markets, a shorter lookback period and lower threshold level are used to identify mean reversion opportunities within a narrower price range.
The mean reversion calculation lies at the core of this indicator. It starts with computing the mean value using the simple moving average (SMA) over the selected lookback period. This represents the average price level. The deviation is then determined by calculating the standard deviation of the closing prices over the same lookback period. The upper and lower bands are derived by adding and subtracting the threshold level multiplied by the deviation from the mean, respectively. These bands serve as dynamic levels that define potential overbought and oversold areas.
In real-time, the indicator's adaptability shines through. If the market is trending, the adaptive mean is set to the calculated mean value. The adaptive upper and lower bands are adjusted by scaling the threshold level with a factor of 0.75. This adjustment allows the indicator to be less sensitive to minor price fluctuations during trending periods, providing more robust mean reversion signals. In ranging market conditions, the regular mean, upper band, and lower band are used as they are more suited to capture mean reversion within a confined price range.
The signal generation component of the indicator identifies potential trading opportunities based on the relationship between the current close price and the adaptive upper and lower bands. If the close price is above the adaptive upper band, it suggests a potential short entry opportunity (-1). Conversely, if the close price is below the adaptive lower band, it indicates a potential long entry opportunity (1). When the close price is within the range defined by the adaptive upper and lower bands, no clear trading signal is generated (0).
To further strengthen the quality of signals, the indicator introduces a confluence condition based on the RSI. When the RSI exceeds the threshold levels of 70 or falls below the threshold level of 30, it indicates a strong momentum condition. By incorporating this confluence condition, the indicator ensures that mean reversion signals align with the prevailing market momentum. It reduces the likelihood of false signals and provides traders with added confidence when entering trades.
The indicator offers alert conditions to notify traders of potential trading opportunities. Alert conditions are set to trigger when a potential long entry signal (1) or a potential short entry signal (-1) aligns with the confluence condition. These alerts allow traders to stay informed about favorable mean reversion setups, even when they are not actively monitoring the charts. By leveraging alerts, traders can efficiently manage their time and take advantage of market opportunities.
To enhance visual interpretation, the indicator incorporates background coloration that provides valuable insights into the prevailing market conditions. When the indicator generates a potential short entry signal (-1) that aligns with the confluence condition, the background color is set to lime. This color suggests a bullish trend that is potentially reaching an exhaustion point and about to revert downwards. Similarly, when the indicator generates a potential long entry signal (1) that aligns with the confluence condition, the background color is set to fuchsia. This color represents a bearish trend that is potentially reaching an exhaustion point and about to revert upwards. By employing background coloration, the indicator enables traders to quickly identify market conditions that may offer mean reversion opportunities with a directional bias.
The indicator further enhances visual clarity by incorporating bar coloring that aligns with the prevailing market conditions and signals. When the indicator generates a potential short entry signal (-1) that aligns with the confluence condition, the bar color is set to lime. This color signifies a bullish trend that is potentially reaching an exhaustion point, indicating a high probability of a downward reversion. Conversely, when the indicator generates a potential long entry signal (1) that aligns with the confluence condition, the bar color is set to fuchsia. This color represents a bearish trend that is potentially reaching an exhaustion point, indicating a high probability of an upward reversion. By using distinct bar colors, the indicator provides traders with a clear visual distinction between bullish and bearish trends, facilitating easier identification of mean reversion opportunities within the context of the broader trend.
While the "Adaptive Mean Reversion Indicator" offers a robust framework for identifying mean reversion opportunities, it's important to remember that no indicator is foolproof. Traders should exercise caution and employ risk management strategies. Additionally, it is recommended to use this indicator in conjunction with other technical analysis tools and fundamental factors to make well-informed trading decisions. Regular backtesting and refinement of the indicator's parameters are crucial to ensure its effectiveness in different market conditions.
Volume-Weighted RSI with Adaptive SmoothingThis indicator is designed to provide traders with insights into the relative strength of a security by incorporating volume-weighted elements, effectively combining the concepts of Relative Strength Index (RSI) and volume-weighted averages to generate meaningful trading signals.
The indicator calculates the traditional RSI, which measures the speed and change of price movements, as well as the volume-weighted RSI, which considers the influence of trading volume on price action. It then applies adaptive smoothing to the volume-weighted RSI, allowing for customization of the smoothing process. The resulting smoothed volume-weighted RSI is plotted alongside the original RSI, providing traders with a comprehensive view of the price strength dynamics.
The line coloration in this indicator is designed to provide visual cues about the relationship between the RSI and the volume-weighted RSI. When the RSI line is above or equal to the volume-weighted RSI line, it suggests a potentially bullish condition with positive market momentum. In such cases, the line is colored lime. Conversely, when the RSI line (fuchsia) is below the volume-weighted RSI line, it indicates a potentially bearish condition with negative market momentum. The line color is set to fuchsia. By observing the line color, traders can quickly assess the relative strength between the RSI and the volume-weighted RSI, aiding their decision-making process.
The bar color and background color further enhance the visual interpretation of the indicator. The bar color reflects the RSI's relationship with the volume-weighted RSI and the predefined thresholds. If the RSI line is above both the volume-weighted RSI line and the overbought threshold (70), the bar color is set to lime, indicating a potentially overbought condition. Conversely, if the RSI line is below both the volume-weighted RSI line and the oversold threshold (30), the bar color is set to fuchsia, suggesting a potentially oversold condition. When the RSI line is between these two thresholds, the bar color is set to yellow, indicating a neutral or intermediate state. The background color, displayed with a semi-transparent shade, provides additional context by reflecting the prevailing market conditions. It turns lime if the volume-weighted RSI is above the overbought threshold, fuchsia if below the oversold threshold, and yellow if it falls between these two thresholds. This coloration scheme aids traders in quickly assessing market conditions and potential trading opportunities.
Calculations:
-- RSI Calculation : The traditional RSI is calculated based on the price movements of the asset. The up and down movements are determined, and exponential moving averages are used to smooth the values. The RSI value ranges from 0 to 100, with levels above 70 indicating overbought conditions and levels below 30 indicating oversold conditions.
-- Volume-Weighted RSI Calculation : The volume-weighted RSI incorporates the trading volume of the asset into the calculations. The closing price is multiplied by the corresponding volume, and the average is taken over a specific length. The up and down movements are smoothed using exponential moving averages to generate the volume-weighted RSI value.
-- Adaptive Smoothing : The indicator offers an adaptive smoothing option, allowing traders to customize the smoothing process of the volume-weighted RSI. By adjusting the smoothing length, traders can fine-tune the responsiveness of the indicator to changes in market conditions. Smoothing helps reduce noise and enhances the clarity of the signals.
Interpretation:
The indicator provides two main components for interpretation:
-- RSI : The traditional RSI reflects the price momentum and potential overbought or oversold conditions. Traders can look for RSI values above 70 as potential overbought signals, suggesting a possible price reversal or correction. Conversely, RSI values below 30 indicate potential oversold signals, indicating a potential price rebound or rally.
-- Volume-Weighted RSI : The volume-weighted RSI incorporates trading volume, which provides insights into the strength of price movements. When the volume-weighted RSI is above the traditional RSI, it suggests that the buying pressure supported by higher volume is stronger, potentially indicating a more reliable trend. Conversely, when the volume-weighted RSI is below the traditional RSI, it suggests that the selling pressure supported by higher volume is stronger, potentially indicating a more significant price reversal.
Potential Strategies:
-- Overbought and Oversold Signals : Traders can utilize the RSI component of the indicator to identify overbought and oversold conditions. A potential strategy is to consider taking short positions when the RSI is above 70 and long positions when the RSI is below 30. These levels can act as dynamic support and resistance areas, indicating possible price reversals.
-- Confirmation with Volume : Traders can use the volume-weighted RSI as a confirmation tool to validate price movements. When the volume-weighted RSI is above the traditional RSI, it may provide additional confirmation for long positions, suggesting stronger buying pressure. Conversely, when the volume-weighted RSI is below the traditional RSI, it may provide confirmation for short positions, indicating stronger selling pressure.
-- Trend Reversal Strategy : Watch for the volume-weighted RSI to reach extreme levels above 70 (overbought) or below 30 (oversold). Look for a reversal signal where the RSI line (green or fuchsia) crosses below or above the volume-weighted RSI line. Enter a trade when the reversal signal occurs, and the RSI line changes color. Exit the trade when the RSI line crosses back in the opposite direction or reaches the opposite extreme level.
-- Divergence Strategy : Compare the direction of the RSI line (green or fuchsia) with the volume-weighted RSI line. A bullish divergence occurs when the RSI line makes higher lows while the volume-weighted RSI line makes lower lows. A bearish divergence occurs when the RSI line makes lower highs while the volume-weighted RSI line makes higher highs. Once a divergence is identified, wait for the RSI line to cross above or below the volume-weighted RSI line as confirmation of a potential trend reversal. Consider using additional indicators or price action analysis to time the entry more accurately. Use stop-loss orders and profit targets to manage risk and secure profits.
-- Trend Continuation Strategy : Assess the overall trend direction by observing the RSI line's position relative to the volume-weighted RSI line. When the RSI line consistently stays above the volume-weighted RSI line, it indicates a bullish trend, while the opposite suggests a bearish trend. Look for temporary pullbacks within the ongoing trend where the RSI line (green or fuchsia) touches or crosses the volume-weighted RSI line. Enter trades in the direction of the dominant trend when the RSI line crosses back in the trend direction. Exit the trade when the RSI line starts to deviate significantly from the volume-weighted RSI line or when the trend shows signs of weakening through other technical or fundamental factors.
Limitations:
-- False Signals : Like any indicator, the "Volume-Weighted RSI with Adaptive Smoothing" may produce false signals, especially during periods of low liquidity or choppy market conditions. Traders should exercise caution and consider using additional confirmation indicators or tools to validate the signals generated by this indicator.
-- Lagging Nature : The indicator relies on historical price data and volume to calculate the RSI and volume-weighted RSI. As a result, the signals provided may have a certain degree of lag compared to real-time price action. Traders should be aware of this inherent lag and consider combining the indicator with other timely indicators to enhance the accuracy of their trading decisions.
-- Parameter Sensitivity : The indicator's effectiveness can be influenced by the choice of parameters, such as the length of the RSI, smoothing length, and adaptive smoothing option. Different market conditions may require adjustments to these parameters to optimize performance. Traders are encouraged to conduct thorough testing and analysis to determine the most suitable parameter values for their specific trading strategies and preferences.
-- Market Conditions : The indicator's performance may vary depending on the prevailing market conditions. It is essential to understand that no indicator can guarantee accurate predictions or consistently profitable trades. Traders should consider the broader market context, fundamental factors, and other technical indicators to complement the insights provided by the "Volume-Weighted RSI with Adaptive Smoothing" indicator.
-- Subjectivity : Interpretation of the indicator's signals involves subjective judgment. Traders may have varying interpretations of overbought and oversold levels, as well as the significance of the volume-weighted RSI in relation to the traditional RSI. It is crucial to combine the indicator with personal analysis and trading experience to make informed trading decisions.
Remember, no single indicator can provide foolproof trading signals. The "Volume-Weighted RSI with Adaptive Smoothing" indicator serves as a valuable tool for analyzing price strength and volume dynamics. It can assist traders in identifying potential entry and exit points, validating trends, and managing risk. However, it should be used as part of a comprehensive trading strategy that considers multiple factors and indicators to increase the likelihood of successful trades.

GKD-M Baseline Optimizer [Loxx]Giga Kaleidoscope GKD-M Baseline Optimizer is a Metamorphosis module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
The Baseline Optimizer enables traders to backtest over 60 moving averages using variable period inputs. It then exports the baseline with the highest cumulative win rate per candle to any baseline-enabled GKD backtest. To perform the backtesting, the trader selects an initial period input (default is 60) and a skip value that increments the initial period input up to seven times. For instance, if a skip value of 5 is chosen, the Baseline Optimizer will run the backtest for the selected moving average on periods such as 60, 65, 70, 75, and so on, up to 90. If the user selects an initial period input of 45 and a skip value of 2, the Baseline Optimizer will conduct backtests for the chosen moving average on periods like 45, 47, 49, 51, and so forth, up to 57.
The Baseline Optimizer provides a table displaying the output of the backtests for a specified date range. The table output represents the cumulative win rate for the given date range.
On the Metamorphosis side of the Baseline Optimizer, a cumulative backtest is calculated for each candle within the date range. This means that each candle may exhibit a different distribution of period inputs with the highest win rate for a particular moving average. The Baseline Optimizer identifies the period input combination with the highest win rates for long and short positions and creates a win-rate adaptive long and short moving average chart. The moving average used for shorts differs from the moving average used for longs, and the moving average for each candle may vary from any other candle. This customized baseline can then be exported to all baseline-enabled GKD backtests.
The backtest employed in the Baseline Optimizer is a Solo Confirmation Simple, allowing only one take profit and one stop loss to be set.
Lastly, the Baseline Optimizer incorporates Goldie Locks Zone filtering, which can be utilized for signal generation in advanced GKD backtests.
█ Moving Averages included in the Baseline Optimizer
Adaptive Moving Average - AMA
ADXvma - Average Directional Volatility Moving Average
Ahrens Moving Average
Alexander Moving Average - ALXMA
Deviation Scaled Moving Average - DSMA
Donchian
Double Exponential Moving Average - DEMA
Double Smoothed Exponential Moving Average - DSEMA
Double Smoothed FEMA - DSFEMA
Double Smoothed Range Weighted EMA - DSRWEMA
Double Smoothed Wilders EMA - DSWEMA
Double Weighted Moving Average - DWMA
Exponential Moving Average - EMA
Fast Exponential Moving Average - FEMA
Fractal Adaptive Moving Average - FRAMA
Generalized DEMA - GDEMA
Generalized Double DEMA - GDDEMA
Hull Moving Average (Type 1) - HMA1
Hull Moving Average (Type 2) - HMA2
Hull Moving Average (Type 3) - HMA3
Hull Moving Average (Type 4) - HMA4
IE /2 - Early T3 by Tim Tilson
Integral of Linear Regression Slope - ILRS
Kaufman Adaptive Moving Average - KAMA
Leader Exponential Moving Average
Linear Regression Value - LSMA ( Least Squares Moving Average )
Linear Weighted Moving Average - LWMA
McGinley Dynamic
McNicholl EMA
Non-Lag Moving Average
Ocean NMA Moving Average - ONMAMA
One More Moving Average - OMA
Parabolic Weighted Moving Average
Probability Density Function Moving Average - PDFMA
Quadratic Regression Moving Average - QRMA
Regularized EMA - REMA
Range Weighted EMA - RWEMA
Recursive Moving Trendline
Simple Decycler - SDEC
Simple Jurik Moving Average - SJMA
Simple Moving Average - SMA
Sine Weighted Moving Average
Smoothed LWMA - SLWMA
Smoothed Moving Average - SMMA
Smoother
Super Smoother
T3
Three-pole Ehlers Butterworth
Three-pole Ehlers Smoother
Triangular Moving Average - TMA
Triple Exponential Moving Average - TEMA
Two-pole Ehlers Butterworth
Two-pole Ehlers smoother
Variable Index Dynamic Average - VIDYA
Variable Moving Average - VMA
Volume Weighted EMA - VEMA
Volume Weighted Moving Average - VWMA
Zero-Lag DEMA - Zero Lag Exponential Moving Average
Zero-Lag Moving Average
Zero Lag TEMA - Zero Lag Triple Exponential Moving Average
Adaptive Moving Average - AMA
The Adaptive Moving Average (AMA) is a moving average that changes its sensitivity to price moves depending on the calculated volatility. It becomes more sensitive during periods when the price is moving smoothly in a certain direction and becomes less sensitive when the price is volatile.
ADXvma - Average Directional Volatility Moving Average
Linnsoft's ADXvma formula is a volatility-based moving average, with the volatility being determined by the value of the ADX indicator.
The ADXvma has the SMA in Chande's CMO replaced with an EMA , it then uses a few more layers of EMA smoothing before the "Volatility Index" is calculated.
A side effect is, those additional layers slow down the ADXvma when you compare it to Chande's Variable Index Dynamic Average VIDYA .
The ADXVMA provides support during uptrends and resistance during downtrends and will stay flat for longer, but will create some of the most accurate market signals when it decides to move.
Ahrens Moving Average
Richard D. Ahrens's Moving Average promises "Smoother Data" that isn't influenced by the occasional price spike. It works by using the Open and the Close in his formula so that the only time the Ahrens Moving Average will change is when the candlestick is either making new highs or new lows.
Alexander Moving Average - ALXMA
This Moving Average uses an elaborate smoothing formula and utilizes a 7 period Moving Average. It corresponds to fitting a second-order polynomial to seven consecutive observations. This moving average is rarely used in trading but is interesting as this Moving Average has been applied to diffusion indexes that tend to be very volatile.
Deviation Scaled Moving Average - DSMA
The Deviation-Scaled Moving Average is a data smoothing technique that acts like an exponential moving average with a dynamic smoothing coefficient. The smoothing coefficient is automatically updated based on the magnitude of price changes. In the Deviation-Scaled Moving Average, the standard deviation from the mean is chosen to be the measure of this magnitude. The resulting indicator provides substantial smoothing of the data even when price changes are small while quickly adapting to these changes.
Donchian
Donchian Channels are three lines generated by moving average calculations that comprise an indicator formed by upper and lower bands around a midrange or median band. The upper band marks the highest price of a security over N periods while the lower band marks the lowest price of a security over N periods.
Double Exponential Moving Average - DEMA
The Double Exponential Moving Average ( DEMA ) combines a smoothed EMA and a single EMA to provide a low-lag indicator. It's primary purpose is to reduce the amount of "lagging entry" opportunities, and like all Moving Averages, the DEMA confirms uptrends whenever price crosses on top of it and closes above it, and confirms downtrends when the price crosses under it and closes below it - but with significantly less lag.
Double Smoothed Exponential Moving Average - DSEMA
The Double Smoothed Exponential Moving Average is a lot less laggy compared to a traditional EMA . It's also considered a leading indicator compared to the EMA , and is best utilized whenever smoothness and speed of reaction to market changes are required.
Double Smoothed FEMA - DSFEMA
Same as the Double Exponential Moving Average (DEMA), but uses a faster version of EMA for its calculation.
Double Smoothed Range Weighted EMA - DSRWEMA
Range weighted exponential moving average (EMA) is, unlike the "regular" range weighted average calculated in a different way. Even though the basis - the range weighting - is the same, the way how it is calculated is completely different. By definition this type of EMA is calculated as a ratio of EMA of price*weight / EMA of weight. And the results are very different and the two should be considered as completely different types of averages. The higher than EMA to price changes responsiveness when the ranges increase remains in this EMA too and in those cases this EMA is clearly leading the "regular" EMA. This version includes double smoothing.
Double Smoothed Wilders EMA - DSWEMA
Welles Wilder was frequently using one "special" case of EMA (Exponential Moving Average) that is due to that fact (that he used it) sometimes called Wilder's EMA. This version is adding double smoothing to Wilder's EMA in order to make it "faster" (it is more responsive to market prices than the original) and is still keeping very smooth values.
Double Weighted Moving Average - DWMA
Double weighted moving average is an LWMA (Linear Weighted Moving Average). Instead of doing one cycle for calculating the LWMA, the indicator is made to cycle the loop 2 times. That produces a smoother values than the original LWMA
Exponential Moving Average - EMA
The EMA places more significance on recent data points and moves closer to price than the SMA ( Simple Moving Average ). It reacts faster to volatility due to its emphasis on recent data and is known for its ability to give greater weight to recent and more relevant data. The EMA is therefore seen as an enhancement over the SMA .
Fast Exponential Moving Average - FEMA
An Exponential Moving Average with a short look-back period.
Fractal Adaptive Moving Average - FRAMA
The Fractal Adaptive Moving Average by John Ehlers is an intelligent adaptive Moving Average which takes the importance of price changes into account and follows price closely enough to display significant moves whilst remaining flat if price ranges. The FRAMA does this by dynamically adjusting the look-back period based on the market's fractal geometry.
Generalized DEMA - GDEMA
The double exponential moving average (DEMA), was developed by Patrick Mulloy in an attempt to reduce the amount of lag time found in traditional moving averages. It was first introduced in the February 1994 issue of the magazine Technical Analysis of Stocks & Commodities in Mulloy's article "Smoothing Data with Faster Moving Averages.". Instead of using fixed multiplication factor in the final DEMA formula, the generalized version allows you to change it. By varying the "volume factor" form 0 to 1 you apply different multiplications and thus producing DEMA with different "speed" - the higher the volume factor is the "faster" the DEMA will be (but also the slope of it will be less smooth). The volume factor is limited in the calculation to 1 since any volume factor that is larger than 1 is increasing the overshooting to the extent that some volume factors usage makes the indicator unusable.
Generalized Double DEMA - GDDEMA
The double exponential moving average (DEMA), was developed by Patrick Mulloy in an attempt to reduce the amount of lag time found in traditional moving averages. It was first introduced in the February 1994 issue of the magazine Technical Analysis of Stocks & Commodities in Mulloy's article "Smoothing Data with Faster Moving Averages''. This is an extension of the Generalized DEMA using Tim Tillsons (the inventor of T3) idea, and is using GDEMA of GDEMA for calculation (which is the "middle step" of T3 calculation). Since there are no versions showing that middle step, this version covers that too. The result is smoother than Generalized DEMA, but is less smooth than T3 - one has to do some experimenting in order to find the optimal way to use it, but in any case, since it is "faster" than the T3 (Tim Tillson T3) and still smooth, it looks like a good compromise between speed and smoothness.
Hull Moving Average (Type 1) - HMA1
Alan Hull's HMA makes use of weighted moving averages to prioritize recent values and greatly reduce lag whilst maintaining the smoothness of a traditional Moving Average. For this reason, it's seen as a well-suited Moving Average for identifying entry points. This version uses SMA for smoothing.
Hull Moving Average (Type 2) - HMA2
Alan Hull's HMA makes use of weighted moving averages to prioritize recent values and greatly reduce lag whilst maintaining the smoothness of a traditional Moving Average. For this reason, it's seen as a well-suited Moving Average for identifying entry points. This version uses EMA for smoothing.
Hull Moving Average (Type 3) - HMA3
Alan Hull's HMA makes use of weighted moving averages to prioritize recent values and greatly reduce lag whilst maintaining the smoothness of a traditional Moving Average. For this reason, it's seen as a well-suited Moving Average for identifying entry points. This version uses LWMA for smoothing.
Hull Moving Average (Type 4) - HMA4
Alan Hull's HMA makes use of weighted moving averages to prioritize recent values and greatly reduce lag whilst maintaining the smoothness of a traditional Moving Average. For this reason, it's seen as a well-suited Moving Average for identifying entry points. This version uses SMMA for smoothing.
IE /2 - Early T3 by Tim Tilson and T3 new
The T3 moving average is a type of technical indicator used in financial analysis to identify trends in price movements. It is similar to the Exponential Moving Average (EMA) and the Double Exponential Moving Average (DEMA), but uses a different smoothing algorithm.
The T3 moving average is calculated using a series of exponential moving averages that are designed to filter out noise and smooth the data. The resulting smoothed data is then weighted with a non-linear function to produce a final output that is more responsive to changes in trend direction.
The T3 moving average can be customized by adjusting the length of the moving average, as well as the weighting function used to smooth the data. It is commonly used in conjunction with other technical indicators as part of a larger trading strategy.
Integral of Linear Regression Slope - ILRS
A Moving Average where the slope of a linear regression line is simply integrated as it is fitted in a moving window of length N (natural numbers in maths) across the data. The derivative of ILRS is the linear regression slope. ILRS is not the same as a SMA ( Simple Moving Average ) of length N, which is actually the midpoint of the linear regression line as it moves across the data.
Kaufman Adaptive Moving Average - KAMA
Developed by Perry Kaufman, Kaufman's Adaptive Moving Average (KAMA) is a moving average designed to account for market noise or volatility. KAMA will closely follow prices when the price swings are relatively small and the noise is low.
Leader Exponential Moving Average
The Leader EMA was created by Giorgos E. Siligardos who created a Moving Average which was able to eliminate lag altogether whilst maintaining some smoothness. It was first described during his research paper "MACD Leader" where he applied this to the MACD to improve its signals and remove its lagging issue. This filter uses his leading MACD's "modified EMA" and can be used as a zero lag filter.
Linear Regression Value - LSMA ( Least Squares Moving Average )
LSMA as a Moving Average is based on plotting the end point of the linear regression line. It compares the current value to the prior value and a determination is made of a possible trend, eg. the linear regression line is pointing up or down.
Linear Weighted Moving Average - LWMA
LWMA reacts to price quicker than the SMA and EMA . Although it's similar to the Simple Moving Average , the difference is that a weight coefficient is multiplied to the price which means the most recent price has the highest weighting, and each prior price has progressively less weight. The weights drop in a linear fashion.
McGinley Dynamic
John McGinley created this Moving Average to track prices better than traditional Moving Averages. It does this by incorporating an automatic adjustment factor into its formula, which speeds (or slows) the indicator in trending, or ranging, markets.
McNicholl EMA
Dennis McNicholl developed this Moving Average to use as his center line for his "Better Bollinger Bands" indicator and was successful because it responded better to volatility changes over the standard SMA and managed to avoid common whipsaws.
Non-lag moving average
The Non Lag Moving average follows price closely and gives very quick signals as well as early signals of price change. As a standalone Moving Average, it should not be used on its own, but as an additional confluence tool for early signals.
Ocean NMA Moving Average - ONMAMA
Created by Jim Sloman, the NMA is a moving average that automatically adjusts to volatility without being programmed to do so. For more info, read his guide "Ocean Theory, an Introduction"
One More Moving Average (OMA)
The One More Moving Average (OMA) is a technical indicator that calculates a series of Jurik-style moving averages in order to reduce noise and provide smoother price data. It uses six exponential moving averages to generate the final value, with the length of the moving averages determined by an adaptive algorithm that adjusts to the current market conditions. The algorithm calculates the average period by comparing the signal to noise ratio and using this value to determine the length of the moving averages. The resulting values are used to generate the final value of the OMA, which can be used to identify trends and potential changes in trend direction.
Parabolic Weighted Moving Average
The Parabolic Weighted Moving Average is a variation of the Linear Weighted Moving Average . The Linear Weighted Moving Average calculates the average by assigning different weights to each element in its calculation. The Parabolic Weighted Moving Average is a variation that allows weights to be changed to form a parabolic curve. It is done simply by using the Power parameter of this indicator.
Probability Density Function Moving Average - PDFMA
Probability density function based MA is a sort of weighted moving average that uses probability density function to calculate the weights. By its nature it is similar to a lot of digital filters.
Quadratic Regression Moving Average - QRMA
A quadratic regression is the process of finding the equation of the parabola that best fits a set of data. This moving average is an obscure concept that was posted to Forex forums in around 2008.
Regularized EMA - REMA
The regularized exponential moving average (REMA) by Chris Satchwell is a variation on the EMA (see Exponential Moving Average) designed to be smoother but not introduce too much extra lag.
Range Weighted EMA - RWEMA
This indicator is a variation of the range weighted EMA. The variation comes from a possible need to make that indicator a bit less "noisy" when it comes to slope changes. The method used for calculating this variation is the method described by Lee Leibfarth in his article "Trading With An Adaptive Price Zone".
Recursive Moving Trendline
Dennis Meyers's Recursive Moving Trendline uses a recursive (repeated application of a rule) polynomial fit, a technique that uses a small number of past values estimations of price and today's price to predict tomorrow's price.
Simple Decycler - SDEC
The Ehlers Simple Decycler study is a virtually zero-lag technical indicator proposed by John F. Ehlers. The original idea behind this study (and several others created by John F. Ehlers) is that market data can be considered a continuum of cycle periods with different cycle amplitudes. Thus, trending periods can be considered segments of longer cycles, or, in other words, low-frequency segments. Applying the right filter might help identify these segments.
Simple Loxx Moving Average - SLMA
A three stage moving average combining an adaptive EMA, a Kalman Filter, and a Kauffman adaptive filter.
Simple Moving Average - SMA
The SMA calculates the average of a range of prices by adding recent prices and then dividing that figure by the number of time periods in the calculation average. It is the most basic Moving Average which is seen as a reliable tool for starting off with Moving Average studies. As reliable as it may be, the basic moving average will work better when it's enhanced into an EMA .
Sine Weighted Moving Average
The Sine Weighted Moving Average assigns the most weight at the middle of the data set. It does this by weighting from the first half of a Sine Wave Cycle and the most weighting is given to the data in the middle of that data set. The Sine WMA closely resembles the TMA (Triangular Moving Average).
Smoothed LWMA - SLWMA
A smoothed version of the LWMA
Smoothed Moving Average - SMMA
The Smoothed Moving Average is similar to the Simple Moving Average ( SMA ), but aims to reduce noise rather than reduce lag. SMMA takes all prices into account and uses a long lookback period. Due to this, it's seen as an accurate yet laggy Moving Average.
Smoother
The Smoother filter is a faster-reacting smoothing technique which generates considerably less lag than the SMMA ( Smoothed Moving Average ). It gives earlier signals but can also create false signals due to its earlier reactions. This filter is sometimes wrongly mistaken for the superior Jurik Smoothing algorithm.
Super Smoother
The Super Smoother filter uses John Ehlers’s “Super Smoother” which consists of a Two pole Butterworth filter combined with a 2-bar SMA ( Simple Moving Average ) that suppresses the 22050 Hz Nyquist frequency: A characteristic of a sampler, which converts a continuous function or signal into a discrete sequence.
Three-pole Ehlers Butterworth
The 3 pole Ehlers Butterworth (as well as the Two pole Butterworth) are both superior alternatives to the EMA and SMA . They aim at producing less lag whilst maintaining accuracy. The 2 pole filter will give you a better approximation for price, whereas the 3 pole filter has superior smoothing.
Three-pole Ehlers smoother
The 3 pole Ehlers smoother works almost as close to price as the above mentioned 3 Pole Ehlers Butterworth. It acts as a strong baseline for signals but removes some noise. Side by side, it hardly differs from the Three Pole Ehlers Butterworth but when examined closely, it has better overshoot reduction compared to the 3 pole Ehlers Butterworth.
Triangular Moving Average - TMA
The TMA is similar to the EMA but uses a different weighting scheme. Exponential and weighted Moving Averages will assign weight to the most recent price data. Simple moving averages will assign the weight equally across all the price data. With a TMA (Triangular Moving Average), it is double smoother (averaged twice) so the majority of the weight is assigned to the middle portion of the data.
Triple Exponential Moving Average - TEMA
The TEMA uses multiple EMA calculations as well as subtracting lag to create a tool which can be used for scalping pullbacks. As it follows price closely, its signals are considered very noisy and should only be used in extremely fast-paced trading conditions.
Two-pole Ehlers Butterworth
The 2 pole Ehlers Butterworth (as well as the three pole Butterworth mentioned above) is another filter that cuts out the noise and follows the price closely. The 2 pole is seen as a faster, leading filter over the 3 pole and follows price a bit more closely. Analysts will utilize both a 2 pole and a 3 pole Butterworth on the same chart using the same period, but having both on chart allows its crosses to be traded.
Two-pole Ehlers smoother
A smoother version of the Two pole Ehlers Butterworth. This filter is the faster version out of the 3 pole Ehlers Butterworth. It does a decent job at cutting out market noise whilst emphasizing a closer following to price over the 3 pole Ehlers .
Variable Index Dynamic Average - VIDYA
Variable Index Dynamic Average Technical Indicator ( VIDYA ) was developed by Tushar Chande. It is an original method of calculating the Exponential Moving Average ( EMA ) with the dynamically changing period of averaging.
Variable Moving Average - VMA
The Variable Moving Average (VMA) is a study that uses an Exponential Moving Average being able to automatically adjust its smoothing factor according to the market volatility.
Volume Weighted EMA - VEMA
An EMA that uses a volume and price weighted calculation instead of the standard price input.
Volume Weighted Moving Average - VWMA
A Volume Weighted Moving Average is a moving average where more weight is given to bars with heavy volume than with light volume. Thus the value of the moving average will be closer to where most trading actually happened than it otherwise would be without being volume weighted.
Zero-Lag DEMA - Zero Lag Double Exponential Moving Average
John Ehlers's Zero Lag DEMA's aim is to eliminate the inherent lag associated with all trend following indicators which average a price over time. Because this is a Double Exponential Moving Average with Zero Lag, it has a tendency to overshoot and create a lot of false signals for swing trading. It can however be used for quick scalping or as a secondary indicator for confluence.
Zero-Lag Moving Average
The Zero Lag Moving Average is described by its creator, John Ehlers , as a Moving Average with absolutely no delay. And it's for this reason that this filter will cause a lot of abrupt signals which will not be ideal for medium to long-term traders. This filter is designed to follow price as close as possible whilst de-lagging data instead of basing it on regular data. The way this is done is by attempting to remove the cumulative effect of the Moving Average.
Zero-Lag TEMA - Zero Lag Triple Exponential Moving Average
Just like the Zero Lag DEMA , this filter will give you the fastest signals out of all the Zero Lag Moving Averages. This is useful for scalping but dangerous for medium to long-term traders, especially during market Volatility and news events. Having no lag, this filter also has no smoothing in its signals and can cause some very bizarre behavior when applied to certain indicators.
█ Volatility Goldie Locks Zone
The Goldie Locks Zone volatility filter is the standard first-pass filter used in all advanced GKD backtests (Complex, Super Complex, and Full GKd). This filter requires the price to fall within a range determined by multiples of volatility. The Goldie Locks Zone is separate from the core Baseline and utilizes its own moving average with Loxx's Exotic Source Types you can read about below.
On the chart, you will find green and red dots positioned at the top, indicating whether a candle qualifies for a long or short trade respectively. Additionally, green and red triangles are located at the bottom of the chart, signifying whether the trigger has crossed up or down and qualifies within the Goldie Locks zone. The Goldie Locks zone is represented by a white color on the mean line, indicating low volatility levels that are not suitable for trading.
█ Volatility Types Included in the Baseline Optimizer
The GKD system utilizes volatility-based take profits and stop losses. Each take profit and stop loss is calculated as a multiple of volatility. Users can also adjust the multiplier values in the settings.
This module includes 17 types of volatility:
Close-to-Close
Parkinson
Garman-Klass
Rogers-Satchell
Yang-Zhang
Garman-Klass-Yang-Zhang
Exponential Weighted Moving Average
Standard Deviation of Log Returns
Pseudo GARCH(2,2)
Average True Range
True Range Double
Standard Deviation
Adaptive Deviation
Median Absolute Deviation
Efficiency-Ratio Adaptive ATR
Mean Absolute Deviation
Static Percent
Various volatility estimators and indicators that investors and traders can use to measure the dispersion or volatility of a financial instrument's price. Each estimator has its strengths and weaknesses, and the choice of estimator should depend on the specific needs and circumstances of the user.
Close-to-Close
Close-to-Close volatility is a classic and widely used volatility measure, sometimes referred to as historical volatility.
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a larger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility is calculated using only a stock's closing prices. It is the simplest volatility estimator. However, in many cases, it is not precise enough. Stock prices could jump significantly during a trading session and return to the opening value at the end. That means that a considerable amount of price information is not taken into account by close-to-close volatility.
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. This is useful as close-to-close prices could show little difference while large price movements could have occurred during the day. Thus, Parkinson's volatility is considered more precise and requires less data for calculation than close-to-close volatility.
One drawback of this estimator is that it doesn't take into account price movements after the market closes. Hence, it systematically undervalues volatility. This drawback is addressed in the Garman-Klass volatility estimator.
Garman-Klass
Garman-Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing prices. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change follows a continuous diffusion process (Geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremes.
Researchers Rogers and Satchell have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates a drift term (mean return not equal to zero). As a result, it provides better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. This leads to an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
Yang-Zhang volatility can be thought of as a combination of the overnight (close-to-open volatility) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility. It is considered to be 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman-Klass-Yang-Zhang (GKYZ) volatility estimator incorporates the returns of open, high, low, and closing prices in its calculation.
GKYZ volatility estimator takes into account overnight jumps but not the trend, i.e., it assumes that the underlying asset follows a Geometric Brownian Motion (GBM) process with zero drift. Therefore, the GKYZ volatility estimator tends to overestimate the volatility when the drift is different from zero. However, for a GBM process, this estimator is eight times more efficient than the close-to-close volatility estimator.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, with the main applications being technical analysis and volatility modeling.
The moving average is designed such that older observations are given lower weights. The weights decrease exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility. It's the standard deviation of ln(close/close(1)).
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by ?.
?avg(var;M) + (1 ? ?) avg(var;N) = 2?var/(M+1-(M-1)L) + 2(1-?)var/(M+1-(M-1)L)
Solving for ? can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg(var; N) against avg(var; M) - avg(var; N) and using the resulting beta estimate as ?.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Standard Deviation
Standard deviation is a statistic that measures the dispersion of a dataset relative to its mean and is calculated as the square root of the variance. The standard deviation is calculated as the square root of variance by determining each data point's deviation relative to the mean. If the data points are further from the mean, there is a higher deviation within the data set; thus, the more spread out the data, the higher the standard deviation.
Adaptive Deviation
By definition, the Standard Deviation (STD, also represented by the Greek letter sigma ? or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis, we usually use it to measure the level of current volatility.
Standard Deviation is based on Simple Moving Average calculation for mean value. This version of standard deviation uses the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA, we can call it EMA deviation. Additionally, Perry Kaufman's efficiency ratio is used to make it adaptive (since all EMA type calculations are nearly perfect for adapting).
The difference when compared to the standard is significant--not just because of EMA usage, but the efficiency ratio makes it a "bit more logical" in very volatile market conditions.
Median Absolute Deviation
The median absolute deviation is a measure of statistical dispersion. Moreover, the MAD is a robust statistic, being more resilient to outliers in a data set than the standard deviation. In the standard deviation, the distances from the mean are squared, so large deviations are weighted more heavily, and thus outliers can heavily influence it. In the MAD, the deviations of a small number of outliers are irrelevant.
Because the MAD is a more robust estimator of scale than the sample variance or standard deviation, it works better with distributions without a mean or variance, such as the Cauchy distribution.
For this indicator, a manual recreation of the quantile function in Pine Script is used. This is so users have a full inside view into how this is calculated.
Efficiency-Ratio Adaptive ATR
Average True Range (ATR) is a widely used indicator for many occasions in technical analysis. It is calculated as the RMA of the true range. This version adds a "twist": it uses Perry Kaufman's Efficiency Ratio to calculate adaptive true range.
Mean Absolute Deviation
The mean absolute deviation (MAD) is a measure of variability that indicates the average distance between observations and their mean. MAD uses the original units of the data, which simplifies interpretation. Larger values signify that the data points spread out further from the average. Conversely, lower values correspond to data points bunching closer to it. The mean absolute deviation is also known as the mean deviation and average absolute deviation.
This definition of the mean absolute deviation sounds similar to the standard deviation (SD). While both measure variability, they have different calculations. In recent years, some proponents of MAD have suggested that it replace the SD as the primary measure because it is a simpler concept that better fits real life.
█ Loxx's Expanded Source Types Included in Baseline Optimizer
This indicator allows you to select from 33 source types. They are as follows:
Close
Open
High
Low
Median
Typical
Weighted
Average
Average Median Body
Trend Biased
Trend Biased (Extreme)
HA Close
HA Open
HA High
HA Low
HA Median
HA Typical
HA Weighted
HA Average
HA Average Median Body
HA Trend Biased
HA Trend Biased (Extreme)
HAB Close
HAB Open
HAB High
HAB Low
HAB Median
HAB Typical
HAB Weighted
HAB Average
HAB Average Median Body
HAB Trend Biased
HAB Trend Biased (Extreme)
What are Heiken Ashi "better" candles?
Heiken Ashi "better" candles are a modified version of the standard Heiken Ashi candles, which are a popular charting technique used in technical analysis. Heiken Ashi candles help traders identify trends and potential reversal points by smoothing out price data and reducing market noise. The "better formula" was proposed by Sebastian Schmidt in an article published by BNP Paribas in Warrants & Zertifikate, a German magazine, in August 2004. The aim of this formula is to further improve the smoothing of the Heiken Ashi chart and enhance its effectiveness in identifying trends and reversals.
Standard Heiken Ashi candles are calculated using the following formulas:
Heiken Ashi Close = (Open + High + Low + Close) / 4
Heiken Ashi Open = (Previous Heiken Ashi Open + Previous Heiken Ashi Close) / 2
Heiken Ashi High = Max (High, Heiken Ashi Open, Heiken Ashi Close)
Heiken Ashi Low = Min (Low, Heiken Ashi Open, Heiken Ashi Close)
The "better formula" modifies the standard Heiken Ashi calculation by incorporating additional smoothing, which can help reduce noise and make it easier to identify trends and reversals. The modified formulas for Heiken Ashi "better" candles are as follows:
Better Heiken Ashi Close = (Open + High + Low + Close) / 4
Better Heiken Ashi Open = (Previous Better Heiken Ashi Open + Previous Better Heiken Ashi Close) / 2
Better Heiken Ashi High = Max (High, Better Heiken Ashi Open, Better Heiken Ashi Close)
Better Heiken Ashi Low = Min (Low, Better Heiken Ashi Open, Better Heiken Ashi Close)
Smoothing Factor = 2 / (N + 1), where N is the chosen period for smoothing
Smoothed Better Heiken Ashi Open = (Better Heiken Ashi Open * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Open * (1 - Smoothing Factor))
Smoothed Better Heiken Ashi Close = (Better Heiken Ashi Close * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Close * (1 - Smoothing Factor))
The smoothed Better Heiken Ashi Open and Close values are then used to calculate the smoothed Better Heiken Ashi High and Low values, resulting in "better" candles that provide a clearer representation of the market trend and potential reversal points.
Heiken Ashi "better" candles, as mentioned previously, provide a clearer representation of market trends and potential reversal points by reducing noise and smoothing out price data. When using these candles in conjunction with other technical analysis tools and indicators, traders can gain valuable insights into market behavior and make more informed decisions.
To effectively use Heiken Ashi "better" candles in your trading strategy, consider the following tips:
-Trend Identification: Heiken Ashi "better" candles can help you identify the prevailing trend in the market. When the majority of the candles are green (or another color, depending on your chart settings) and there are no or few lower wicks, it may indicate a strong uptrend. Conversely, when the majority of the candles are red (or another color) and there are no or few upper wicks, it may signal a strong downtrend.
-Trend Reversals: Look for potential trend reversals when a change in the color of the candles occurs, especially when accompanied by longer wicks. For example, if a green candle with a long lower wick is followed by a red candle, it could indicate a bearish reversal. Similarly, a red candle with a long upper wick followed by a green candle may suggest a bullish reversal.
-Support and Resistance: You can use Heiken Ashi "better" candles to identify potential support and resistance levels. When the candles are consistently moving in one direction and then suddenly change color with longer wicks, it could indicate the presence of a support or resistance level.
-Stop-Loss and Take-Profit: Using Heiken Ashi "better" candles can help you manage risk by determining optimal stop-loss and take-profit levels. For instance, you can place your stop-loss below the low of the most recent green candle in an uptrend or above the high of the most recent red candle in a downtrend.
-Confirming Signals: Heiken Ashi "better" candles should be used in conjunction with other technical indicators, such as moving averages, oscillators, or chart patterns, to confirm signals and improve the accuracy of your analysis.
In this implementation, you have the choice of AMA, KAMA, or T3 smoothing. These are as follows:
Kaufman Adaptive Moving Average (KAMA)
The Kaufman Adaptive Moving Average (KAMA) is a type of adaptive moving average used in technical analysis to smooth out price fluctuations and identify trends. The KAMA adjusts its smoothing factor based on the market's volatility, making it more responsive in volatile markets and smoother in calm markets. The KAMA is calculated using three different efficiency ratios that determine the appropriate smoothing factor for the current market conditions. These ratios are based on the noise level of the market, the speed at which the market is moving, and the length of the moving average. The KAMA is a popular choice among traders who prefer to use adaptive indicators to identify trends and potential reversals.
Adaptive Moving Average
The Adaptive Moving Average (AMA) is a type of moving average that adjusts its sensitivity to price movements based on market conditions. It uses a ratio between the current price and the highest and lowest prices over a certain lookback period to determine its level of smoothing. The AMA can help reduce lag and increase responsiveness to changes in trend direction, making it useful for traders who want to follow trends while avoiding false signals. The AMA is calculated by multiplying a smoothing constant with the difference between the current price and the previous AMA value, then adding the result to the previous AMA value.
T3
The T3 moving average is a type of technical indicator used in financial analysis to identify trends in price movements. It is similar to the Exponential Moving Average (EMA) and the Double Exponential Moving Average (DEMA), but uses a different smoothing algorithm.
The T3 moving average is calculated using a series of exponential moving averages that are designed to filter out noise and smooth the data. The resulting smoothed data is then weighted with a non-linear function to produce a final output that is more responsive to changes in trend direction.
The T3 moving average can be customized by adjusting the length of the moving average, as well as the weighting function used to smooth the data. It is commonly used in conjunction with other technical indicators as part of a larger trading strategy.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
8. Metamorphosis - a technical indicator that produces a compound signal from the combination of other GKD indicators*
*(not part of the NNFX algorithm)
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
What is an Metamorphosis indicator?
The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, or GKD-E slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v2.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
6. GKD-M - Metamorphosis module (Metamorphosis, Number 8 in the NNFX algorithm, but not part of the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data to A backtest module wherein the various components of the GKD system are combined to create a trading signal.
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Full GKD Backtest
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Kase Peak Oscillator
Confirmation 2: uf2018
Continuation: Vortex
Exit: Rex Oscillator
Metamorphosis: Baseline Optimizer as shown on the chart above
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system.
█ Giga Kaleidoscope Modularized Trading System Signals
Standard Entry
1. GKD-C Confirmation gives signal
2. Baseline agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
1-Candle Standard Entry
1a. GKD-C Confirmation gives signal
2a. Baseline agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Baseline Entry
1. GKD-B Basline gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
7. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
1-Candle Baseline Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Volatility/Volume Entry
1. GKD-V Volatility/Volume gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Volatility/Volume Entry
1a. GKD-V Volatility/Volume gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSVVC Bars Back' prior
Next Candle
1b. Price retraced
2b. Volatility/Volume agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Baseline agrees
Confirmation 2 Entry
1. GKD-C Confirmation 2 gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Volatility/Volume agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Confirmation 2 Entry
1a. GKD-C Confirmation 2 gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSC2C Bars Back' prior
Next Candle
1b. Price retraced
2b. Confirmation 2 agrees
3b. Confirmation 1 agrees
4b. Volatility/Volume agrees
5b. Baseline agrees
PullBack Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price is beyond 1.0x Volatility of Baseline
Next Candle
1b. Price inside Goldie Locks Zone Minimum
2b. Price inside Goldie Locks Zone Maximum
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Continuation Entry
1. Standard Entry, 1-Candle Standard Entry, Baseline Entry, 1-Candle Baseline Entry, Volatility/Volume Entry, 1-Candle Volatility/Volume Entry, Confirmation 2 Entry, 1-Candle Confirmation 2 Entry, or Pullback entry triggered previously
2. Baseline hasn't crossed since entry signal trigger
4. Confirmation 1 agrees
5. Baseline agrees
6. Confirmation 2 agrees
█ Connecting to Backtests
All GKD indicators are chained indicators meaning you export the value of the indicators to specialized backtest to creat your GKD trading system. Each indicator contains a proprietary signal generation algo that will only work with GKD backtests. You can find these backtests using the links below.
GKD-BT Giga Confirmation Stack Backtest:
GKD-BT Giga Stacks Backtest:
GKD-BT Full Giga Kaleidoscope Backtest:
GKD-BT Solo Confirmation Super Complex Backtest:
GKD-BT Solo Confirmation Complex Backtest:
GKD-BT Solo Confirmation Simple Backtest:

Non Adaptive Moving Average - Quan DaoThis Non-Adaptive Moving Average (NAMA) is my origin work. It came from the issues that I always face when using existing famous MA like EMA or RMA:
- What length should I choose for the MA for this security?
- Is there a length that works for multiple timeframes?
- Is there a length that works for multiple securities in multiple markets?
Choosing the right length for an MA is a tedious and boring work and is very subjective. One day in early 2023, I decided to create a new MA that will not be dependant a lot (non-adaptive) on the length of it, to make my life a little bit easier. The idea came from the formula of EMA and RMA:
ma = alpha * src + (1 - alpha) * ma
in which,
alpha = 1 / length for RMA
alpha = 2 / (length + 1) for EMA
I decided to use a constant alpha for the formula, which happened to be: 1.618 / 100 (i.e., golden ratio / 100)
This NAMA is using the length in the start only, after running for a while the MA value will be the same for every value of its length, which resolves good my 3 questions above.
The application of this NAMA is wide, I think.
- It can be used like a normal MA but you don't have to choose its length anymore.
- It can be used like EMA in DEMA, TEMA (I called it DNAMA, TNAMA)
- It can be used in calculating some famous indicators (RSI, TR, ...) so that these indicators will not be dependant on the length as well
In this example script, I included an EMA (in blue color) as well so that you can see how the EMA changes and NAMA stays the same when changing the value of its Length.

Benner-Fibonacci Reversal Points [CC]This is an original script based on a very old idea called the Benner Theory from the Civil War times. Benner discovered a pattern in pig iron prices (no clue what those are), and this turned out to be a parallel idea to indicators based on Fibonacci numbers. Because a year is 365 days (nearly 377, which is a Fibonacci number), made up of 52 weeks (nearly 55, which is another Fibonacci number), or 12 months (nearly 13, which is another Fibonacci number), Benner theorized that he could find both past and future turning points in the market by using a pattern he found. He discovered that peaks in prices seemed to follow a pattern of 8-9-10, meaning that after a recent peak, it would be 8 bars until the next peak, 9 bars until after that peak for the next, and 10 bars until the following peak. For past peaks, he would just need to reverse this pattern, and so the previous peak would be 10 bars before the most current peak, 9 bars before that peak, and 8 bars before the previous one, and these patterns seemed to repeat. For troughs, he found a pattern of 16,18,20 which follows the same logic, and this idea also seemed to work on long-term peaks and troughs as well.
This is my version of the Benner theory and the major difference between my version and his is that he would manually select a year or date and either work backwards or forwards from that point. I chose to go with an adaptive version that will automatically detect those points and plot those past and future points. I have included several options such as allowing the algorithm to be calculated in reverse which seems to work well for Crypto for some reason. I also have both short and long term options to only show one or both if you choose and of course the option to enable repainting or leave it disabled.
Big thanks to @HeWhoMustNotBeNamed and @RicardoSantos for helping me fix some bugs in my code and for @kerpiciwuasile for suggesting this idea in the first place.
GKD-C Adaptive-Lookback Stochastic [Loxx]Giga Kaleidoscope GKD-C Adaptive-Lookback Stochastic is a Metamorphosis module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C Adaptive-Lookback Stochastic
The Adaptive-Lookback Stochastic uses a swing pivot lookback algorithm to adjust the periiod input bar-bar-bar thereby converting the regular Stochasitc oscillator into an adaptive Stochatic oscillator.
What is the Adaptive Lookback Period?
The adaptive lookback period is a technique used in technical analysis to adjust the period of an indicator based on changes in market conditions. This technique is particularly useful in volatile or rapidly changing markets where a fixed period may not be optimal for detecting trends or signals.
The concept of the adaptive lookback period is relatively simple. By adjusting the lookback period based on changes in market conditions, traders can more accurately identify trends and signals. This can help traders to enter and exit trades at the right time and improve the profitability of their trading strategies.
The adaptive lookback period works by identifying potential swing points in the market. Once these points are identified, the lookback period is calculated based on the number of swings and a speed parameter. The swing count parameter determines the number of swings that must occur before the lookback period is adjusted. The speed parameter controls the rate at which the lookback period is adjusted, with higher values indicating a more rapid adjustment.
The adaptive lookback period can be applied to a wide range of technical indicators, including moving averages, oscillators, and trendlines. By adjusting the period of these indicators based on changes in market conditions, traders can reduce the impact of noise and false signals, leading to more profitable trades.
The adaptive lookback period is a powerful technique for traders and analysts looking to optimize their technical indicators. By adjusting the period based on changes in market conditions, traders can more accurately identify trends and signals, leading to more profitable trades. While there are various ways to implement the adaptive lookback period, the basic concept remains the same, and traders can adapt and customize the technique to suit their individual needs and trading styles.
What is the Stochastic Oscillator?
The Stochastic Oscillator is a popular technical analysis indicator developed by George Lane in the 1950s. It is a momentum indicator that compares a security's closing price to its price range over a specified period. The main idea behind the Stochastic Oscillator is that, in an upward trending market, prices tend to close near their high, while in a downward trending market, prices tend to close near their low. The Stochastic Oscillator ranges from 0 to 100 and is primarily used to identify overbought and oversold conditions or potential trend reversals.
The Stochastic Oscillator is calculated using the following formula:
%K = ((C - L14) / (H14 - L14)) * 100
Where:
%K: The Stochastic Oscillator value.
C: The most recent closing price.
L14: The lowest price of the last 14 periods (or any other chosen period).
H14: The highest price of the last 14 periods (or any other chosen period).
Additionally, a moving average of %K, called %D, is calculated to provide a signal line:
%D = Simple Moving Average of %K over 'n' periods
The Stochastic Oscillator generates signals based on the following conditions:
1. Overbought and Oversold Levels: The Stochastic Oscillator typically uses 80 and 20 as overbought and oversold levels, respectively. When the oscillator is above 80, it is considered overbought, indicating that the market may be overvalued and a price decline is possible. When the oscillator is below 20, it is considered oversold, indicating that the market may be undervalued and a price rise is possible.
2. Bullish and Bearish Divergences: A bullish divergence occurs when the price makes a lower low, but the Stochastic Oscillator makes a higher low, suggesting a potential trend reversal to the upside. A bearish divergence occurs when the price makes a higher high, but the Stochastic Oscillator makes a lower high, suggesting a potential trend reversal to the downside.
3. Crosses: Buy signals are generated when %K crosses above %D, indicating upward momentum. Sell signals are generated when %K crosses below %D, indicating downward momentum.
The Stochastic Oscillator is commonly used in combination with other technical analysis tools to confirm signals and improve the accuracy of predictions.
When using the Stochastic Oscillator, it's important to consider a few best practices and additional insights:
1. Confirmation with other indicators: While the Stochastic Oscillator can provide valuable insights into potential trend reversals and overbought/oversold conditions, it is generally more effective when used in conjunction with other technical indicators, such as moving averages, RSI (Relative Strength Index), or MACD (Moving Average Convergence Divergence). This can help confirm signals and reduce the chances of false signals or whipsaws.
2. Timeframes: The Stochastic Oscillator can be applied to various timeframes, such as daily, weekly, or intraday charts. Adjusting the lookback period for the calculation can also alter the sensitivity of the indicator. A shorter lookback period will make the oscillator more sensitive to price movements, while a longer lookback period will make it less sensitive. Traders should choose a timeframe and lookback period that aligns with their trading strategy and risk tolerance.
3. Variations: There are two primary variations of the Stochastic Oscillator: Fast Stochastic and Slow Stochastic. The Fast Stochastic uses the original %K and %D calculations, while the Slow Stochastic smooths %K with an additional moving average and uses this smoothed %K as the new %D. The Slow Stochastic is generally considered to generate fewer false signals due to the additional smoothing.
4. Overbought and Oversold: It's important to remember that overbought and oversold conditions can persist for an extended period, especially during strong trends. This means that the Stochastic Oscillator alone should not be relied upon as a definitive buy or sell signal. Instead, traders should wait for additional confirmation from other indicators or price action before entering or exiting a trade.
The Stochastic Oscillator is a valuable momentum indicator that helps traders identify potential trend reversals and overbought/oversold conditions in the market. However, it is most effective when used in combination with other technical analysis tools and should be adapted to suit the specific needs of the individual trader's strategy and risk tolerance.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
8. Metamorphosis - a technical indicator that produces a compound signal from the combination of other GKD indicators*
*(not part of the NNFX algorithm)
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
What is an Metamorphosis indicator?
The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, or GKD-E slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v2.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
6. GKD-M - Metamorphosis module (Metamorphosis, Number 8 in the NNFX algorithm, but not part of the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data to A backtest module wherein the various components of the GKD system are combined to create a trading signal.
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Full GKD Backtest
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Composite RSI
Confirmation 2: uf2018
Continuation: Vortex
Exit: Rex Oscillator
Metamorphosis: Fisher Transform, Universal Oscillator, Aroon, Vortex .. combined
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system.
█ Giga Kaleidoscope Modularized Trading System Signals
Standard Entry
1. GKD-C Confirmation gives signal
2. Baseline agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
1-Candle Standard Entry
1a. GKD-C Confirmation gives signal
2a. Baseline agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Baseline Entry
1. GKD-B Basline gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
7. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
1-Candle Baseline Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Volatility/Volume Entry
1. GKD-V Volatility/Volume gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Volatility/Volume Entry
1a. GKD-V Volatility/Volume gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSVVC Bars Back' prior
Next Candle
1b. Price retraced
2b. Volatility/Volume agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Baseline agrees
Confirmation 2 Entry
1. GKD-C Confirmation 2 gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Volatility/Volume agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Confirmation 2 Entry
1a. GKD-C Confirmation 2 gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSC2C Bars Back' prior
Next Candle
1b. Price retraced
2b. Confirmation 2 agrees
3b. Confirmation 1 agrees
4b. Volatility/Volume agrees
5b. Baseline agrees
PullBack Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price is beyond 1.0x Volatility of Baseline
Next Candle
1b. Price inside Goldie Locks Zone Minimum
2b. Price inside Goldie Locks Zone Maximum
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Continuation Entry
1. Standard Entry, 1-Candle Standard Entry, Baseline Entry, 1-Candle Baseline Entry, Volatility/Volume Entry, 1-Candle Volatility/Volume Entry, Confirmation 2 Entry, 1-Candle Confirmation 2 Entry, or Pullback entry triggered previously
2. Baseline hasn't crossed since entry signal trigger
4. Confirmation 1 agrees
5. Baseline agrees
6. Confirmation 2 agrees
█ Connecting to Backtests
All GKD indicators are chained indicators meaning you export the value of the indicators to specialized backtest to creat your GKD trading system. Each indicator contains a proprietary signal generation algo that will only work with GKD backtests. You can find these backtests using the links below.
GKD-BT Giga Confirmation Stack Backtest:
GKD-BT Giga Stacks Backtest:
GKD-BT Full Giga Kaleidoscope Backtest:
GKD-BT Solo Confirmation Super Complex Backtest:
GKD-BT Solo Confirmation Complex Backtest:
GKD-BT Solo Confirmation Simple Backtest:

Endpointed SSA of Price [Loxx]The Endpointed SSA of Price: A Comprehensive Tool for Market Analysis and Decision-Making
The financial markets present sophisticated challenges for traders and investors as they navigate the complexities of market behavior. To effectively interpret and capitalize on these complexities, it is crucial to employ powerful analytical tools that can reveal hidden patterns and trends. One such tool is the Endpointed SSA of Price, which combines the strengths of Caterpillar Singular Spectrum Analysis, a sophisticated time series decomposition method, with insights from the fields of economics, artificial intelligence, and machine learning.
The Endpointed SSA of Price has its roots in the interdisciplinary fusion of mathematical techniques, economic understanding, and advancements in artificial intelligence. This unique combination allows for a versatile and reliable tool that can aid traders and investors in making informed decisions based on comprehensive market analysis.
The Endpointed SSA of Price is not only valuable for experienced traders but also serves as a useful resource for those new to the financial markets. By providing a deeper understanding of market forces, this innovative indicator equips users with the knowledge and confidence to better assess risks and opportunities in their financial pursuits.
█ Exploring Caterpillar SSA: Applications in AI, Machine Learning, and Finance
Caterpillar SSA (Singular Spectrum Analysis) is a non-parametric method for time series analysis and signal processing. It is based on a combination of principles from classical time series analysis, multivariate statistics, and the theory of random processes. The method was initially developed in the early 1990s by a group of Russian mathematicians, including Golyandina, Nekrutkin, and Zhigljavsky.
Background Information:
SSA is an advanced technique for decomposing time series data into a sum of interpretable components, such as trend, seasonality, and noise. This decomposition allows for a better understanding of the underlying structure of the data and facilitates forecasting, smoothing, and anomaly detection. Caterpillar SSA is a particular implementation of SSA that has proven to be computationally efficient and effective for handling large datasets.
Uses in AI and Machine Learning:
In recent years, Caterpillar SSA has found applications in various fields of artificial intelligence (AI) and machine learning. Some of these applications include:
1. Feature extraction: Caterpillar SSA can be used to extract meaningful features from time series data, which can then serve as inputs for machine learning models. These features can help improve the performance of various models, such as regression, classification, and clustering algorithms.
2. Dimensionality reduction: Caterpillar SSA can be employed as a dimensionality reduction technique, similar to Principal Component Analysis (PCA). It helps identify the most significant components of a high-dimensional dataset, reducing the computational complexity and mitigating the "curse of dimensionality" in machine learning tasks.
3. Anomaly detection: The decomposition of a time series into interpretable components through Caterpillar SSA can help in identifying unusual patterns or outliers in the data. Machine learning models trained on these decomposed components can detect anomalies more effectively, as the noise component is separated from the signal.
4. Forecasting: Caterpillar SSA has been used in combination with machine learning techniques, such as neural networks, to improve forecasting accuracy. By decomposing a time series into its underlying components, machine learning models can better capture the trends and seasonality in the data, resulting in more accurate predictions.
Application in Financial Markets and Economics:
Caterpillar SSA has been employed in various domains within financial markets and economics. Some notable applications include:
1. Stock price analysis: Caterpillar SSA can be used to analyze and forecast stock prices by decomposing them into trend, seasonal, and noise components. This decomposition can help traders and investors better understand market dynamics, detect potential turning points, and make more informed decisions.
2. Economic indicators: Caterpillar SSA has been used to analyze and forecast economic indicators, such as GDP, inflation, and unemployment rates. By decomposing these time series, researchers can better understand the underlying factors driving economic fluctuations and develop more accurate forecasting models.
3. Portfolio optimization: By applying Caterpillar SSA to financial time series data, portfolio managers can better understand the relationships between different assets and make more informed decisions regarding asset allocation and risk management.
Application in the Indicator:
In the given indicator, Caterpillar SSA is applied to a financial time series (price data) to smooth the series and detect significant trends or turning points. The method is used to decompose the price data into a set number of components, which are then combined to generate a smoothed signal. This signal can help traders and investors identify potential entry and exit points for their trades.
The indicator applies the Caterpillar SSA method by first constructing the trajectory matrix using the price data, then computing the singular value decomposition (SVD) of the matrix, and finally reconstructing the time series using a selected number of components. The reconstructed series serves as a smoothed version of the original price data, highlighting significant trends and turning points. The indicator can be customized by adjusting the lag, number of computations, and number of components used in the reconstruction process. By fine-tuning these parameters, traders and investors can optimize the indicator to better match their specific trading style and risk tolerance.
Caterpillar SSA is versatile and can be applied to various types of financial instruments, such as stocks, bonds, commodities, and currencies. It can also be combined with other technical analysis tools or indicators to create a comprehensive trading system. For example, a trader might use Caterpillar SSA to identify the primary trend in a market and then employ additional indicators, such as moving averages or RSI, to confirm the trend and generate trading signals.
In summary, Caterpillar SSA is a powerful time series analysis technique that has found applications in AI and machine learning, as well as financial markets and economics. By decomposing a time series into interpretable components, Caterpillar SSA enables better understanding of the underlying structure of the data, facilitating forecasting, smoothing, and anomaly detection. In the context of financial trading, the technique is used to analyze price data, detect significant trends or turning points, and inform trading decisions.
█ Input Parameters
This indicator takes several inputs that affect its signal output. These inputs can be classified into three categories: Basic Settings, UI Options, and Computation Parameters.
Source: This input represents the source of price data, which is typically the closing price of an asset. The user can select other price data, such as opening price, high price, or low price. The selected price data is then utilized in the Caterpillar SSA calculation process.
Lag: The lag input determines the window size used for the time series decomposition. A higher lag value implies that the SSA algorithm will consider a longer range of historical data when extracting the underlying trend and components. This parameter is crucial, as it directly impacts the resulting smoothed series and the quality of extracted components.
Number of Computations: This input, denoted as 'ncomp,' specifies the number of eigencomponents to be considered in the reconstruction of the time series. A smaller value results in a smoother output signal, while a higher value retains more details in the series, potentially capturing short-term fluctuations.
SSA Period Normalization: This input is used to normalize the SSA period, which adjusts the significance of each eigencomponent to the overall signal. It helps in making the algorithm adaptive to different timeframes and market conditions.
Number of Bars: This input specifies the number of bars to be processed by the algorithm. It controls the range of data used for calculations and directly affects the computation time and the output signal.
Number of Bars to Render: This input sets the number of bars to be plotted on the chart. A higher value slows down the computation but provides a more comprehensive view of the indicator's performance over a longer period. This value controls how far back the indicator is rendered.
Color bars: This boolean input determines whether the bars should be colored according to the signal's direction. If set to true, the bars are colored using the defined colors, which visually indicate the trend direction.
Show signals: This boolean input controls the display of buy and sell signals on the chart. If set to true, the indicator plots shapes (triangles) to represent long and short trade signals.
Static Computation Parameters:
The indicator also includes several internal parameters that affect the Caterpillar SSA algorithm, such as Maxncomp, MaxLag, and MaxArrayLength. These parameters set the maximum allowed values for the number of computations, the lag, and the array length, ensuring that the calculations remain within reasonable limits and do not consume excessive computational resources.
█ A Note on Endpionted, Non-repainting Indicators
An endpointed indicator is one that does not recalculate or repaint its past values based on new incoming data. In other words, the indicator's previous signals remain the same even as new price data is added. This is an important feature because it ensures that the signals generated by the indicator are reliable and accurate, even after the fact.
When an indicator is non-repainting or endpointed, it means that the trader can have confidence in the signals being generated, knowing that they will not change as new data comes in. This allows traders to make informed decisions based on historical signals, without the fear of the signals being invalidated in the future.
In the case of the Endpointed SSA of Price, this non-repainting property is particularly valuable because it allows traders to identify trend changes and reversals with a high degree of accuracy, which can be used to inform trading decisions. This can be especially important in volatile markets where quick decisions need to be made.
GKD-C Volatility-Adaptive Rapid RSI T3 [Loxx]Giga Kaleidoscope GKD-C Volatility-Adaptive Rapid RSI T3 is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C Volatility-Adaptive Rapid RSI T3
Adaptive Momentum: Mastering Market Dynamics with Advanced RSI Techniques
The Volatility-Adaptive Rapid RSI T3 is a sophisticated technical indicator that combines the concepts of Rapid RSI, Volatility Adaptation, and T3 smoothing. This combination results in a more responsive, accurate, and adaptable momentum oscillator compared to the regular RSI.
The Rapid RSI is a variation of the RSI designed to provide faster and more responsive signals. It does this by modifying the way average gains and losses are calculated, using a simple moving average (SMA) instead of an exponential moving average (EMA). This makes the Rapid RSI more sensitive to recent price changes, allowing traders to identify overbought and oversold conditions more quickly.
Volatility adaptation is a concept that adjusts the parameters of an indicator based on the current market volatility. In the context of the Volatility-Adaptive Rapid RSI T3, the volatility is calculated using the standard deviation of price changes over a specified period. This value is then used to adjust the T3 smoothing period, making the indicator more adaptive to changing market conditions. When the market is volatile, the indicator will respond more quickly to price changes, while in less volatile markets, the indicator will be less sensitive, reducing the likelihood of false signals.
T3 smoothing, developed by Tim Tilson, is a powerful and flexible moving average technique that aims to reduce lag and improve the responsiveness of an indicator. It utilizes a combination of multiple exponential moving averages with varying degrees of weighting to create a smoother and more accurate representation of the underlying data. The T3 smoothing method is applied to the price data before the Rapid RSI calculation, enhancing the overall responsiveness of the indicator.
By combining these three concepts, the Volatility-Adaptive Rapid RSI T3 offers several advantages over the regular RSI:
1. Faster and more responsive signals: The Rapid RSI and T3 smoothing components allow the indicator to respond more quickly to price changes, potentially leading to earlier entry and exit points.
2. Adaptability to market conditions: The volatility adaptation feature enables the indicator to adjust its sensitivity based on the current market volatility. This helps to reduce false signals in less volatile markets and increase responsiveness in more volatile markets.
2. Smoother representation of price data: The T3 smoothing technique provides a more accurate and smoother representation of the underlying data, making it easier to identify trends and potential reversals.
In conclusion, the Volatility-Adaptive Rapid RSI T3 is a powerful technical indicator that offers several improvements over the regular RSI. Its responsiveness, adaptability, and smoothing capabilities make it a valuable tool for traders seeking to identify overbought and oversold conditions more accurately. However, it is essential to remember that no indicator is perfect, and using the Volatility-Adaptive Rapid RSI T3 in conjunction with other technical indicators and analysis tools can provide more reliable trading signals.
Additional Features
This indicator allows you to select from 33 source types. They are as follows:
Close
Open
High
Low
Median
Typical
Weighted
Average
Average Median Body
Trend Biased
Trend Biased (Extreme)
HA Close
HA Open
HA High
HA Low
HA Median
HA Typical
HA Weighted
HA Average
HA Average Median Body
HA Trend Biased
HA Trend Biased (Extreme)
HAB Close
HAB Open
HAB High
HAB Low
HAB Median
HAB Typical
HAB Weighted
HAB Average
HAB Average Median Body
HAB Trend Biased
HAB Trend Biased (Extreme)
What are Heiken Ashi "better" candles?
Heiken Ashi "better" candles are a modified version of the standard Heiken Ashi candles, which are a popular charting technique used in technical analysis. Heiken Ashi candles help traders identify trends and potential reversal points by smoothing out price data and reducing market noise. The "better formula" was proposed by Sebastian Schmidt in an article published by BNP Paribas in Warrants & Zertifikate, a German magazine, in August 2004. The aim of this formula is to further improve the smoothing of the Heiken Ashi chart and enhance its effectiveness in identifying trends and reversals.
Standard Heiken Ashi candles are calculated using the following formulas:
Heiken Ashi Close = (Open + High + Low + Close) / 4
Heiken Ashi Open = (Previous Heiken Ashi Open + Previous Heiken Ashi Close) / 2
Heiken Ashi High = Max (High, Heiken Ashi Open, Heiken Ashi Close)
Heiken Ashi Low = Min (Low, Heiken Ashi Open, Heiken Ashi Close)
The "better formula" modifies the standard Heiken Ashi calculation by incorporating additional smoothing, which can help reduce noise and make it easier to identify trends and reversals. The modified formulas for Heiken Ashi "better" candles are as follows:
Better Heiken Ashi Close = (Open + High + Low + Close) / 4
Better Heiken Ashi Open = (Previous Better Heiken Ashi Open + Previous Better Heiken Ashi Close) / 2
Better Heiken Ashi High = Max (High, Better Heiken Ashi Open, Better Heiken Ashi Close)
Better Heiken Ashi Low = Min (Low, Better Heiken Ashi Open, Better Heiken Ashi Close)
Smoothing Factor = 2 / (N + 1), where N is the chosen period for smoothing
Smoothed Better Heiken Ashi Open = (Better Heiken Ashi Open * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Open * (1 - Smoothing Factor))
Smoothed Better Heiken Ashi Close = (Better Heiken Ashi Close * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Close * (1 - Smoothing Factor))
The smoothed Better Heiken Ashi Open and Close values are then used to calculate the smoothed Better Heiken Ashi High and Low values, resulting in "better" candles that provide a clearer representation of the market trend and potential reversal points.
It's important to note that, like any other technical analysis tool, Heiken Ashi "better" candles are not foolproof and should be used in conjunction with other indicators and analysis techniques to make well-informed trading decisions.
Heiken Ashi "better" candles, as mentioned previously, provide a clearer representation of market trends and potential reversal points by reducing noise and smoothing out price data. When using these candles in conjunction with other technical analysis tools and indicators, traders can gain valuable insights into market behavior and make more informed decisions.
To effectively use Heiken Ashi "better" candles in your trading strategy, consider the following tips:
Trend Identification: Heiken Ashi "better" candles can help you identify the prevailing trend in the market. When the majority of the candles are green (or another color, depending on your chart settings) and there are no or few lower wicks, it may indicate a strong uptrend. Conversely, when the majority of the candles are red (or another color) and there are no or few upper wicks, it may signal a strong downtrend.
Trend Reversals: Look for potential trend reversals when a change in the color of the candles occurs, especially when accompanied by longer wicks. For example, if a green candle with a long lower wick is followed by a red candle, it could indicate a bearish reversal. Similarly, a red candle with a long upper wick followed by a green candle may suggest a bullish reversal.
Support and Resistance: You can use Heiken Ashi "better" candles to identify potential support and resistance levels. When the candles are consistently moving in one direction and then suddenly change color with longer wicks, it could indicate the presence of a support or resistance level.
Stop-Loss and Take-Profit: Using Heiken Ashi "better" candles can help you manage risk by determining optimal stop-loss and take-profit levels. For instance, you can place your stop-loss below the low of the most recent green candle in an uptrend or above the high of the most recent red candle in a downtrend.
Confirming Signals: Heiken Ashi "better" candles should be used in conjunction with other technical indicators, such as moving averages, oscillators, or chart patterns, to confirm signals and improve the accuracy of your analysis.
In this implementation, you have the choice of AMA, KAMA, or T3 smoothing. These are as follows:
Kaufman Adaptive Moving Average (KAMA)
The Kaufman Adaptive Moving Average (KAMA) is a type of adaptive moving average used in technical analysis to smooth out price fluctuations and identify trends. The KAMA adjusts its smoothing factor based on the market's volatility, making it more responsive in volatile markets and smoother in calm markets. The KAMA is calculated using three different efficiency ratios that determine the appropriate smoothing factor for the current market conditions. These ratios are based on the noise level of the market, the speed at which the market is moving, and the length of the moving average. The KAMA is a popular choice among traders who prefer to use adaptive indicators to identify trends and potential reversals.
Adaptive Moving Average
The Adaptive Moving Average (AMA) is a type of moving average that adjusts its sensitivity to price movements based on market conditions. It uses a ratio between the current price and the highest and lowest prices over a certain lookback period to determine its level of smoothing. The AMA can help reduce lag and increase responsiveness to changes in trend direction, making it useful for traders who want to follow trends while avoiding false signals. The AMA is calculated by multiplying a smoothing constant with the difference between the current price and the previous AMA value, then adding the result to the previous AMA value.
T3
The T3 moving average is a type of technical indicator used in financial analysis to identify trends in price movements. It is similar to the Exponential Moving Average (EMA) and the Double Exponential Moving Average (DEMA), but uses a different smoothing algorithm.
The T3 moving average is calculated using a series of exponential moving averages that are designed to filter out noise and smooth the data. The resulting smoothed data is then weighted with a non-linear function to produce a final output that is more responsive to changes in trend direction.
The T3 moving average can be customized by adjusting the length of the moving average, as well as the weighting function used to smooth the data. It is commonly used in conjunction with other technical indicators as part of a larger trading strategy.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Volatility-Adaptive Rapid RSI T3 as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Volatility-Adaptive Rapid RSI T3
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

GKD-C Adaptive-Lookback Variety RSI [Loxx]Giga Kaleidoscope GKD-C Adaptive-Lookback Variety RSI is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C Adaptive-Lookback Variety RSI
What is the Adaptive Lookback Period?
The adaptive lookback period is a technique used in technical analysis to adjust the period of an indicator based on changes in market conditions. This technique is particularly useful in volatile or rapidly changing markets where a fixed period may not be optimal for detecting trends or signals.
The concept of the adaptive lookback period is relatively simple. By adjusting the lookback period based on changes in market conditions, traders can more accurately identify trends and signals. This can help traders to enter and exit trades at the right time and improve the profitability of their trading strategies.
The adaptive lookback period works by identifying potential swing points in the market. Once these points are identified, the lookback period is calculated based on the number of swings and a speed parameter. The swing count parameter determines the number of swings that must occur before the lookback period is adjusted. The speed parameter controls the rate at which the lookback period is adjusted, with higher values indicating a more rapid adjustment.
The adaptive lookback period can be applied to a wide range of technical indicators, including moving averages, oscillators, and trendlines. By adjusting the period of these indicators based on changes in market conditions, traders can reduce the impact of noise and false signals, leading to more profitable trades.
In summary, the adaptive lookback period is a powerful technique for traders and analysts looking to optimize their technical indicators. By adjusting the period based on changes in market conditions, traders can more accurately identify trends and signals, leading to more profitable trades. While there are various ways to implement the adaptive lookback period, the basic concept remains the same, and traders can adapt and customize the technique to suit their individual needs and trading styles.
This indicator includes 10 types of RSI
1. Regular RSI
2. Slow RSI
3. Ehlers Smoothed RSI
4. Cutler's RSI
5. Rapid RSI
6. Harris' RSI
7. RSI DEMA
8. RSI TEMA
9. RSI T3
10. Jurik RSX
Regular RSI
The Relative Strength Index (RSI) is a widely used technical indicator in the field of financial market analysis. Developed by J. Welles Wilder Jr. in 1978, the RSI is a momentum oscillator that measures the speed and change of price movements. It helps traders identify potential trend reversals, overbought, and oversold conditions in a market.
The RSI is calculated based on the average gains and losses of an asset over a specified period, typically 14 days. The formula for calculating the RSI is as follows:
RSI = 100 - (100 / (1 + RS))
Where:
RS (Relative Strength) = Average gain over the specified period / Average loss over the specified period
The RSI ranges from 0 to 100, with values above 70 generally considered overbought (potentially indicating that the asset is overvalued and may experience a price decline) and values below 30 considered oversold (potentially indicating that the asset is undervalued and may experience a price increase).
Slow RSI
Slow RSI is a modified version of the Relative Strength Index (RSI) indicator that aims to provide a smoother, more consistent signal than the traditional RSI. The Slow RSI is designed to be less sensitive to sudden price movements, which can cause false signals.
To calculate Slow RSI, we first calculate the up and down values, just like in traditional RSI and Ehlers RSI. The up and down values are calculated by comparing the current price to the previous price, and then adding up the positive and negative differences.
Next, we calculate the Slow RSI value using the formula:
SlowRSI = 100 * up / (up + dn)
where "up" and "dn" are the total positive and negative differences, respectively.
This formula is similar to the one used in traditional RSI, but the dynamic lookback period based on the average of the up and down values is used to smooth out the signal.
Finally, we apply smoothing to the Slow RSI value by taking an exponential moving average (EMA) of the Slow RSI values over a specified period. This EMA helps to reduce the impact of sudden price movements and provide a smoother, more consistent signal over time.
Ehler's Smoothed RSI
Ehlers RSI is a modified version of the Relative Strength Index (RSI) indicator created by John Ehlers, a well-known technical analyst and author. The purpose of Ehlers RSI is to reduce lag and improve the responsiveness of the traditional RSI indicator.
To calculate Ehlers RSI, we first smooth the prices by taking a weighted average of the current price and the two previous prices. This smoothing helps to reduce noise in the data and produce a more accurate signal.
Next, we calculate the up and down values differently than in traditional RSI. In traditional RSI, the up and down values are based on the difference between the current price and the previous price. In Ehlers RSI, the up and down values are based on the difference between the current price and the price two bars ago. This approach helps to reduce lag and produce a more responsive indicator.
Finally, we calculate Ehlers RSI using the formula:
EhlersRSI = 50 * (up - down) / (up + down) + 50
The result is a more timely signal that can help traders identify potential trends and reversals in the market. However, as with any technical indicator, Ehlers RSI should be used in conjunction with other analysis tools and should not be relied on as the sole basis for trading decisions.
Cutler's RSI
Cutler's RSI (Relative Strength Index) is a variation of the traditional RSI, a popular technical analysis indicator used to measure the speed and change of price movements. The main difference between Cutler's RSI and the traditional RSI is the calculation method used to smooth the data. While the traditional RSI uses an exponential moving average (EMA) to smooth the data, Cutler's RSI uses a simple moving average (SMA).
Here's the formula for Cutler's RSI:
1. Calculate the price change: Price Change = Current Price - Previous Price
2. Calculate the average gain and average loss over a specified period (usually 14 days):
If Price Change > 0, add it to the total gains.
If Price Change < 0, add the absolute value to the total losses.
3. Calculate the average gain and average loss by dividing the totals by the specified period: Average Gain = Total Gains / Period, Average Loss = Total Losses / Period
4. Calculate the Relative Strength (RS): RS = Average Gain / Average Loss
5. Calculate Cutler's RSI: Cutler's RSI = 100 - (100 / (1 + RS))
Cutler's RSI is not necessarily better than the regular RSI; it's just a different variation of the traditional RSI that uses a simple moving average (SMA) instead of an exponential moving average (EMA) quantifiedstrategies.com. The main advantage of Cutler's RSI is that it is not data length dependent, meaning it returns consistent results regardless of the length of the period, or the starting point within a data file quantifiedstrategies.com.
However, it's worth noting that Cutler's RSI does not necessarily outperform the traditional RSI. In fact, backtests reveal that Cutler's RSI is no improvement compared to Wilder's RSI quantifiedstrategies.com. Additionally, using an SMA instead of an EMA in Cutler's RSI may result in the loss of the "believed" advantage of weighting the most recent price action aaii.com.
Both Cutler's RSI and the traditional RSI can be used to identify overbought/oversold levels, support and resistance, spot divergences for possible reversals, and confirm the signals from other indicators investopedia.com. Ultimately, the choice between Cutler's RSI and the traditional RSI depends on personal preference and the specific trading strategy being employed.
Rapid RSI
Rapid RSI is a technical analysis indicator that is a modified version of the Relative Strength Index (RSI). It was developed by Andrew Cardwell and was first introduced in the October 2006 issue of Technical Analysis of Stocks & Commodities magazine.
The Rapid RSI improves upon the regular RSI by modifying the way the average gains and losses are calculated. Here's a general breakdown of the Rapid RSI calculation:
1. Calculate the upward change (when the price has increased) and the downward change (when the price has decreased) for each period.
2. Calculate the simple moving average (SMA) of the upward changes and the SMA of the downward changes over the specified period.
3. Divide the SMA of the upward changes by the SMA of the downward changes to get the relative strength (RS).
4. Calculate the Rapid RSI by transforming the relative strength (RS) into a value ranging from 0 to 100.
By using the simple moving average (SMA) instead of the slow exponential moving average (RMA) as in the regular RSI, the Rapid RSI tends to be more responsive to recent price changes. This can help traders identify overbought and oversold conditions more quickly, potentially leading to earlier entry and exit points. However, it is important to note that a faster indicator may also produce more false signals.
Harris' RSI
Harris RSI (Relative Strength Index) is a technical indicator used in financial analysis to measure the strength or weakness of a security over time. It was developed by Larry Harris in 1986 as an alternative to the traditional RSI, which measures the price change of a security over a given period.
The Harris RSI uses a slightly different formula from the traditional RSI, but it is based on the same principles. It calculates the ratio of the average gain to the average loss over a specified period, typically 14 days. The result is then plotted on a scale of 0 to 100, with high values indicating overbought conditions and low values indicating oversold conditions.
The Harris RSI is believed to be more responsive to short-term price movements than the traditional RSI, making it useful for traders who are looking for quick trading opportunities. However, like any technical indicator, it should be used in conjunction with other forms of analysis to make informed trading decisions.
The calculation of the Harris RSI involves several steps:
1. Calculate the price change over the specified period (usually 14 days) using the following formula:
Price Change = Close Price - Prior Close Price
2. Calculate the average gain and average loss over the same period, using separate formulas for each:
Average Gain = (Sum of Gains over the Period) / Period
Average Loss = (Sum of Losses over the Period) / Period
Gains are calculated as the sum of all positive price changes over the period, while losses are calculated as the sum of all negative price changes over the period.
3. Calculate the Relative Strength (RS) as the ratio of the Average Gain to the Average Loss:
RS = Average Gain / Average Loss
4. Calculate the Harris RSI using the following formula:
Harris RSI = 100 - (100 / (1 + RS))
The resulting Harris RSI value is a number between 0 and 100, which is plotted on a chart to identify overbought or oversold conditions in the security. A value above 70 is generally considered overbought, while a value below 30 is generally considered oversold.
DEMA RSI
DEMA RSI is a variation of the Relative Strength Index (RSI) technical indicator that incorporates the Double Exponential Moving Average (DEMA) for smoothing. Like the regular RSI, the DEMA RSI is a momentum oscillator used to measure the speed and change of price movements, and it ranges from 0 to 100. Readings below 30 typically indicate oversold conditions, while readings above 70 indicate overbought conditions.
The DEMA RSI aims to improve upon the regular RSI by addressing its limitations, such as lag and false signals. By using the DEMA, a more responsive and faster RSI can be achieved. Here's a general breakdown of the DEMA RSI calculation:
1. Calculate the price change for each period, as well as the absolute value of the change.
2. Apply the DEMA smoothing technique to both the price change and its absolute value, separately. This involves calculating two sets of exponential moving averages and combining them to create a double-weighted moving average with reduced lag.
3. Divide the smoothed price change by the smoothed absolute value of the price change.
4. Transform the result into a value ranging from 0 to 100 to obtain the DEMA RSI.
The DEMA RSI is considered an improvement over the regular RSI because it provides faster and more responsive signals. This can help traders identify overbought and oversold conditions more accurately and potentially avoid false signals.
In summary, the main advantages of these RSI variations over the regular RSI are their ability to reduce noise, provide smoother lines, and be more responsive to price changes. This can lead to more accurate signals and fewer false positives in different market conditions.
TEMA RSI
TEMA RSI is a variation of the Relative Strength Index (RSI) technical indicator that incorporates the Triple Exponential Moving Average (TEMA) for smoothing. Like the regular RSI, the TEMA RSI is a momentum oscillator used to measure the speed and change of price movements, and it ranges from 0 to 100. Readings below 30 typically indicate oversold conditions, while readings above 70 indicate overbought conditions.
The TEMA RSI aims to improve upon the regular RSI by addressing its limitations, such as lag and false signals. By using the TEMA, a more responsive and faster RSI can be achieved. Here's a general breakdown of the TEMA RSI calculation:
1. Calculate the price change for each period, as well as the absolute value of the change.
2. Apply the TEMA smoothing technique to both the price change and its absolute value, separately. This involves calculating two sets of exponential moving averages and combining them to create a double-weighted moving average with reduced lag.
3. Divide the smoothed price change by the smoothed absolute value of the price change.
4. Transform the result into a value ranging from 0 to 100 to obtain the TEMA RSI.
The TEMA RSI is considered an improvement over the regular RSI because it provides faster and more responsive signals. This can help traders identify overbought and oversold conditions more accurately and potentially avoid false signals.
T3 RSI
T3 RSI is a variation of the Relative Strength Index (RSI) technical indicator that incorporates the Tilson T3 for smoothing. Like the regular RSI, the T3 RSI is a momentum oscillator used to measure the speed and change of price movements, and it ranges from 0 to 100. Readings below 30 typically indicate oversold conditions, while readings above 70 indicate overbought conditions.
The T3 RSI aims to improve upon the regular RSI by addressing its limitations, such as lag and false signals. By using the T3, a more responsive and faster RSI can be achieved. Here's a general breakdown of the T3 RSI calculation:
1. Calculate the price change for each period, as well as the absolute value of the change.
2. Apply the T3 smoothing technique to both the price change and its absolute value, separately. This involves calculating two sets of exponential moving averages and combining them to create a double-weighted moving average with reduced lag.
3. Divide the smoothed price change by the smoothed absolute value of the price change.
4. Transform the result into a value ranging from 0 to 100 to obtain the T3 RSI.
The T3 RSI is considered an improvement over the regular RSI because it provides faster and more responsive signals. This can help traders identify overbought and oversold conditions more accurately and potentially avoid false signals.
Jurik RSX
The Jurik RSX is a technical indicator developed by Mark Jurik to measure the momentum and strength of price movements in financial markets, such as stocks, commodities, and currencies. It is an advanced version of the traditional Relative Strength Index (RSI), designed to offer smoother and less lagging signals compared to the standard RSI.
The main advantage of the Jurik RSX is that it provides more accurate and timely signals for traders and analysts, thanks to its improved calculation methods that reduce noise and lag in the indicator's output. This enables better decision-making when analyzing market trends and potential trading opportunities.
What is Adaptive-Lookback Variety RSI
This indicator allows the user to select from 9 different RSI types and 33 source types. The various RSI types is enhanced by injecting an adaptive lookback period into the caculation making the RSI able to adaptive to differing market conditions.
Additional Features
This indicator allows you to select from 33 source types. They are as follows:
Close
Open
High
Low
Median
Typical
Weighted
Average
Average Median Body
Trend Biased
Trend Biased (Extreme)
HA Close
HA Open
HA High
HA Low
HA Median
HA Typical
HA Weighted
HA Average
HA Average Median Body
HA Trend Biased
HA Trend Biased (Extreme)
HAB Close
HAB Open
HAB High
HAB Low
HAB Median
HAB Typical
HAB Weighted
HAB Average
HAB Average Median Body
HAB Trend Biased
HAB Trend Biased (Extreme)
What are Heiken Ashi "better" candles?
Heiken Ashi "better" candles are a modified version of the standard Heiken Ashi candles, which are a popular charting technique used in technical analysis. Heiken Ashi candles help traders identify trends and potential reversal points by smoothing out price data and reducing market noise. The "better formula" was proposed by Sebastian Schmidt in an article published by BNP Paribas in Warrants & Zertifikate, a German magazine, in August 2004. The aim of this formula is to further improve the smoothing of the Heiken Ashi chart and enhance its effectiveness in identifying trends and reversals.
Standard Heiken Ashi candles are calculated using the following formulas:
Heiken Ashi Close = (Open + High + Low + Close) / 4
Heiken Ashi Open = (Previous Heiken Ashi Open + Previous Heiken Ashi Close) / 2
Heiken Ashi High = Max (High, Heiken Ashi Open, Heiken Ashi Close)
Heiken Ashi Low = Min (Low, Heiken Ashi Open, Heiken Ashi Close)
The "better formula" modifies the standard Heiken Ashi calculation by incorporating additional smoothing, which can help reduce noise and make it easier to identify trends and reversals. The modified formulas for Heiken Ashi "better" candles are as follows:
Better Heiken Ashi Close = (Open + High + Low + Close) / 4
Better Heiken Ashi Open = (Previous Better Heiken Ashi Open + Previous Better Heiken Ashi Close) / 2
Better Heiken Ashi High = Max (High, Better Heiken Ashi Open, Better Heiken Ashi Close)
Better Heiken Ashi Low = Min (Low, Better Heiken Ashi Open, Better Heiken Ashi Close)
Smoothing Factor = 2 / (N + 1), where N is the chosen period for smoothing
Smoothed Better Heiken Ashi Open = (Better Heiken Ashi Open * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Open * (1 - Smoothing Factor))
Smoothed Better Heiken Ashi Close = (Better Heiken Ashi Close * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Close * (1 - Smoothing Factor))
The smoothed Better Heiken Ashi Open and Close values are then used to calculate the smoothed Better Heiken Ashi High and Low values, resulting in "better" candles that provide a clearer representation of the market trend and potential reversal points.
It's important to note that, like any other technical analysis tool, Heiken Ashi "better" candles are not foolproof and should be used in conjunction with other indicators and analysis techniques to make well-informed trading decisions.
Heiken Ashi "better" candles, as mentioned previously, provide a clearer representation of market trends and potential reversal points by reducing noise and smoothing out price data. When using these candles in conjunction with other technical analysis tools and indicators, traders can gain valuable insights into market behavior and make more informed decisions.
To effectively use Heiken Ashi "better" candles in your trading strategy, consider the following tips:
Trend Identification: Heiken Ashi "better" candles can help you identify the prevailing trend in the market. When the majority of the candles are green (or another color, depending on your chart settings) and there are no or few lower wicks, it may indicate a strong uptrend. Conversely, when the majority of the candles are red (or another color) and there are no or few upper wicks, it may signal a strong downtrend.
Trend Reversals: Look for potential trend reversals when a change in the color of the candles occurs, especially when accompanied by longer wicks. For example, if a green candle with a long lower wick is followed by a red candle, it could indicate a bearish reversal. Similarly, a red candle with a long upper wick followed by a green candle may suggest a bullish reversal.
Support and Resistance: You can use Heiken Ashi "better" candles to identify potential support and resistance levels. When the candles are consistently moving in one direction and then suddenly change color with longer wicks, it could indicate the presence of a support or resistance level.
Stop-Loss and Take-Profit: Using Heiken Ashi "better" candles can help you manage risk by determining optimal stop-loss and take-profit levels. For instance, you can place your stop-loss below the low of the most recent green candle in an uptrend or above the high of the most recent red candle in a downtrend.
Confirming Signals: Heiken Ashi "better" candles should be used in conjunction with other technical indicators, such as moving averages, oscillators, or chart patterns, to confirm signals and improve the accuracy of your analysis.
In this implementation, you have the choice of AMA, KAMA, or T3 smoothing. These are as follows:
Kaufman Adaptive Moving Average (KAMA)
The Kaufman Adaptive Moving Average (KAMA) is a type of adaptive moving average used in technical analysis to smooth out price fluctuations and identify trends. The KAMA adjusts its smoothing factor based on the market's volatility, making it more responsive in volatile markets and smoother in calm markets. The KAMA is calculated using three different efficiency ratios that determine the appropriate smoothing factor for the current market conditions. These ratios are based on the noise level of the market, the speed at which the market is moving, and the length of the moving average. The KAMA is a popular choice among traders who prefer to use adaptive indicators to identify trends and potential reversals.
Adaptive Moving Average
The Adaptive Moving Average (AMA) is a type of moving average that adjusts its sensitivity to price movements based on market conditions. It uses a ratio between the current price and the highest and lowest prices over a certain lookback period to determine its level of smoothing. The AMA can help reduce lag and increase responsiveness to changes in trend direction, making it useful for traders who want to follow trends while avoiding false signals. The AMA is calculated by multiplying a smoothing constant with the difference between the current price and the previous AMA value, then adding the result to the previous AMA value.
T3
The T3 moving average is a type of technical indicator used in financial analysis to identify trends in price movements. It is similar to the Exponential Moving Average (EMA) and the Double Exponential Moving Average (DEMA), but uses a different smoothing algorithm.
The T3 moving average is calculated using a series of exponential moving averages that are designed to filter out noise and smooth the data. The resulting smoothed data is then weighted with a non-linear function to produce a final output that is more responsive to changes in trend direction.
The T3 moving average can be customized by adjusting the length of the moving average, as well as the weighting function used to smooth the data. It is commonly used in conjunction with other technical indicators as part of a larger trading strategy.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Adaptive-Lookback Variety RSI as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Adaptive-Lookback Variety RSI
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.
GKD-C Time Fractal Energy Adaptive Laguerre RSI [Loxx]Giga Kaleidoscope GKD-C Time Fractal Energy Adaptive Laguerre RSI is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C Time Fractal Energy Adaptive Laguerre RSI
Cracking the Code of Price Momentum with the Time Fractal Energy Adaptive Laguerre RSI Indicator
The Time Fractal Energy adaptive Laguerre RSI is a technical indicator used in financial trading to provide a measure of the momentum of a security's price. It combines several mathematical concepts and techniques, including the Laguerre polynomial, fractal patterns, and adaptive smoothing factors, to provide a more accurate representation of price momentum.
Before diving into the details of how this indicator works, it's important to understand what momentum is and why it's important in trading. Momentum is a measure of the strength and persistence of a trend in a security's price. It can be calculated in various ways, but the basic idea is to look at the change in price over a certain period and use that to infer whether the trend is likely to continue or reverse.
One common momentum indicator is the Relative Strength Index (RSI), which measures the magnitude of recent price changes. The RSI is calculated by dividing the average gain of the price over a certain period by the average loss over the same period, and then normalizing the result to a scale of 0 to 100. A reading above 70 is generally considered overbought, while a reading below 30 is oversold.
While the RSI is a useful tool, it can be prone to noise and false signals, especially in volatile markets. This is where the Time Fractal Energy adaptive Laguerre RSI comes in. It combines the RSI with several other techniques to provide a smoother, more accurate measure of momentum.
Let's break down the components of the Time Fractal Energy adaptive Laguerre RSI in more detail.
-Time Fractal Energy: "Time Fractal" refers to the idea that the behavior of a system can be characterized by self-similar patterns at different time scales. "Energy" in this context refers to the intensity or strength of the fractal pattern. In the context of the indicator, this means that the momentum of a security's price can be characterized by fractal patterns at different time scales.
-Laguerre polynomial: The Laguerre polynomial is a mathematical function used to smooth out data. In the context of the Time Fractal Energy adaptive Laguerre RSI, it is used to filter out noise and highlight underlying trends in the RSI data.
-Adaptive smoothing factors: The smoothing factor used in the Laguerre polynomial is adjusted based on the volatility of the underlying security. This means that the indicator is more responsive to changes in volatility, which can help it perform better in different market conditions.
Now, let's look at how these components come together in the Time Fractal Energy adaptive Laguerre RSI indicator. The code you provided is written in Pine Script, a programming language used on the trading platform TradingView. Here's a step-by-step explanation of what the code does:
1. The input parameters are defined at the top of the code. These include the length of the Average True Range (ATR) period, the price used for the RSI calculation (in this case, the closing price), the smoothing factor, and the upper and lower levels that define overbought and oversold conditions.
2. The Laguerre Filter function is defined using the Laguerre polynomial. This function is used to smooth out the RSI data and filter out noise.
3. The Laguerre RSI function is defined. This function calculates the RSI value based on the Laguerre Filtered data. This step further removes any noise from the RSI calculation, resulting in a smoother, more accurate measure of momentum.
4. The ATR value is calculated based on the highest and lowest prices of the security over the specified period. ATR measures the volatility of a security and is used to determine the adaptive smoothing factor.
5. The gamma value is calculated based on the ATR and the high and low prices of the security over the specified period. Gamma is used as the adaptive smoothing factor in the Laguerre Filter function. The higher the volatility, the higher the gamma value, resulting in a more responsive filter.
6. The Laguerre Filtered RSI value is smoothed further using the gamma value and the smoothing factor. This step helps to reduce any remaining noise in the momentum signal and provide a more accurate representation of the underlying trend.
7. The signal line is created based on the smoothed Laguerre Filtered RSI value from the previous bar. The signal line acts as a trigger for buying or selling, depending on whether it crosses above or below the upper or lower levels defined in the input parameters.
The Time Fractal Energy adaptive Laguerre RSI indicator aims to provide a more accurate measure of momentum by combining several mathematical techniques. The Laguerre polynomial is used to filter out noise and highlight underlying trends, while the adaptive smoothing factor helps to adjust the filter based on the volatility of the underlying security. The result is a smoother, more accurate measure of momentum that can be used to make more informed trading decisions.
It's important to note that no indicator is perfect, and the Time Fractal Energy adaptive Laguerre RSI is no exception. Like any technical indicator, it should be used in combination with other tools and analysis to make informed trading decisions. Additionally, traders should be aware that the indicator may perform differently in different market conditions and should be used in conjunction with other tools to account for changing market conditions.
In conclusion, the Time Fractal Energy adaptive Laguerre RSI is a technical indicator used in financial trading that aims to provide a more accurate measure of momentum. It combines several mathematical techniques, including the Laguerre polynomial, fractal patterns, and adaptive smoothing factors, to filter out noise and highlight underlying trends. While no indicator is perfect, the Time Fractal Energy adaptive Laguerre RSI can be a useful tool when used in combination with other analysis to make informed trading decisions.
Additional Features
This indicator allows you to select from 33 source types. They are as follows:
Close
Open
High
Low
Median
Typical
Weighted
Average
Average Median Body
Trend Biased
Trend Biased (Extreme)
HA Close
HA Open
HA High
HA Low
HA Median
HA Typical
HA Weighted
HA Average
HA Average Median Body
HA Trend Biased
HA Trend Biased (Extreme)
HAB Close
HAB Open
HAB High
HAB Low
HAB Median
HAB Typical
HAB Weighted
HAB Average
HAB Average Median Body
HAB Trend Biased
HAB Trend Biased (Extreme)
What are Heiken Ashi "better" candles?
Heiken Ashi "better" candles are a modified version of the standard Heiken Ashi candles, which are a popular charting technique used in technical analysis. Heiken Ashi candles help traders identify trends and potential reversal points by smoothing out price data and reducing market noise. The "better formula" was proposed by Sebastian Schmidt in an article published by BNP Paribas in Warrants & Zertifikate, a German magazine, in August 2004. The aim of this formula is to further improve the smoothing of the Heiken Ashi chart and enhance its effectiveness in identifying trends and reversals.
Standard Heiken Ashi candles are calculated using the following formulas:
Heiken Ashi Close = (Open + High + Low + Close) / 4
Heiken Ashi Open = (Previous Heiken Ashi Open + Previous Heiken Ashi Close) / 2
Heiken Ashi High = Max (High, Heiken Ashi Open, Heiken Ashi Close)
Heiken Ashi Low = Min (Low, Heiken Ashi Open, Heiken Ashi Close)
The "better formula" modifies the standard Heiken Ashi calculation by incorporating additional smoothing, which can help reduce noise and make it easier to identify trends and reversals. The modified formulas for Heiken Ashi "better" candles are as follows:
Better Heiken Ashi Close = (Open + High + Low + Close) / 4
Better Heiken Ashi Open = (Previous Better Heiken Ashi Open + Previous Better Heiken Ashi Close) / 2
Better Heiken Ashi High = Max (High, Better Heiken Ashi Open, Better Heiken Ashi Close)
Better Heiken Ashi Low = Min (Low, Better Heiken Ashi Open, Better Heiken Ashi Close)
Smoothing Factor = 2 / (N + 1), where N is the chosen period for smoothing
Smoothed Better Heiken Ashi Open = (Better Heiken Ashi Open * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Open * (1 - Smoothing Factor))
Smoothed Better Heiken Ashi Close = (Better Heiken Ashi Close * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Close * (1 - Smoothing Factor))
The smoothed Better Heiken Ashi Open and Close values are then used to calculate the smoothed Better Heiken Ashi High and Low values, resulting in "better" candles that provide a clearer representation of the market trend and potential reversal points.
It's important to note that, like any other technical analysis tool, Heiken Ashi "better" candles are not foolproof and should be used in conjunction with other indicators and analysis techniques to make well-informed trading decisions.
Heiken Ashi "better" candles, as mentioned previously, provide a clearer representation of market trends and potential reversal points by reducing noise and smoothing out price data. When using these candles in conjunction with other technical analysis tools and indicators, traders can gain valuable insights into market behavior and make more informed decisions.
To effectively use Heiken Ashi "better" candles in your trading strategy, consider the following tips:
Trend Identification: Heiken Ashi "better" candles can help you identify the prevailing trend in the market. When the majority of the candles are green (or another color, depending on your chart settings) and there are no or few lower wicks, it may indicate a strong uptrend. Conversely, when the majority of the candles are red (or another color) and there are no or few upper wicks, it may signal a strong downtrend.
Trend Reversals: Look for potential trend reversals when a change in the color of the candles occurs, especially when accompanied by longer wicks. For example, if a green candle with a long lower wick is followed by a red candle, it could indicate a bearish reversal. Similarly, a red candle with a long upper wick followed by a green candle may suggest a bullish reversal.
Support and Resistance: You can use Heiken Ashi "better" candles to identify potential support and resistance levels. When the candles are consistently moving in one direction and then suddenly change color with longer wicks, it could indicate the presence of a support or resistance level.
Stop-Loss and Take-Profit: Using Heiken Ashi "better" candles can help you manage risk by determining optimal stop-loss and take-profit levels. For instance, you can place your stop-loss below the low of the most recent green candle in an uptrend or above the high of the most recent red candle in a downtrend.
Confirming Signals: Heiken Ashi "better" candles should be used in conjunction with other technical indicators, such as moving averages, oscillators, or chart patterns, to confirm signals and improve the accuracy of your analysis.
In this implementation, you have the choice of AMA, KAMA, or T3 smoothing. These are as follows:
Kaufman Adaptive Moving Average (KAMA)
The Kaufman Adaptive Moving Average (KAMA) is a type of adaptive moving average used in technical analysis to smooth out price fluctuations and identify trends. The KAMA adjusts its smoothing factor based on the market's volatility, making it more responsive in volatile markets and smoother in calm markets. The KAMA is calculated using three different efficiency ratios that determine the appropriate smoothing factor for the current market conditions. These ratios are based on the noise level of the market, the speed at which the market is moving, and the length of the moving average. The KAMA is a popular choice among traders who prefer to use adaptive indicators to identify trends and potential reversals.
Adaptive Moving Average
The Adaptive Moving Average (AMA) is a type of moving average that adjusts its sensitivity to price movements based on market conditions. It uses a ratio between the current price and the highest and lowest prices over a certain lookback period to determine its level of smoothing. The AMA can help reduce lag and increase responsiveness to changes in trend direction, making it useful for traders who want to follow trends while avoiding false signals. The AMA is calculated by multiplying a smoothing constant with the difference between the current price and the previous AMA value, then adding the result to the previous AMA value.
T3
The T3 moving average is a type of technical indicator used in financial analysis to identify trends in price movements. It is similar to the Exponential Moving Average (EMA) and the Double Exponential Moving Average (DEMA), but uses a different smoothing algorithm.
The T3 moving average is calculated using a series of exponential moving averages that are designed to filter out noise and smooth the data. The resulting smoothed data is then weighted with a non-linear function to produce a final output that is more responsive to changes in trend direction.
The T3 moving average can be customized by adjusting the length of the moving average, as well as the weighting function used to smooth the data. It is commonly used in conjunction with other technical indicators as part of a larger trading strategy.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Time Fractal Energy Adaptive Laguerre RSI as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Time Fractal Energy Adaptive Laguerre RSI
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.
GKD-C CCI Adaptive Smoother [Loxx]Giga Kaleidoscope GKD-C CCI Adaptive Smoother is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C CCI Adaptive Smoother
Commodity Channel Index: History, Calculation, and Advantages
The Commodity Channel Index (CCI) is a versatile technical analysis indicator widely used by traders and analysts to identify potential trends, reversals, and trading opportunities in various financial markets. Developed by Donald Lambert in 1980, the CCI was initially designed to analyze the cyclical behavior of commodities. However, its applications have expanded over time to include stocks, currencies, and other financial instruments. The following provides an overview of the CCI's history, explain its calculation, and discuss its advantages compared to other indicators.
History
Donald Lambert, a commodities trader and technical analyst, created the Commodity Channel Index in response to the unique challenges posed by the cyclical nature of the commodities markets. Lambert aimed to develop an indicator that could help traders identify potential turning points in the market, allowing them to capitalize on price trends and reversals. The CCI quickly gained popularity among traders and analysts due to its ability to adapt to various market conditions and provide valuable insights into price movements.
Calculation
The CCI is calculated through the following steps:
1. Determine the typical price for each period: The typical price is calculated as the average of the high, low, and closing prices for each period.
Typical Price = (High + Low + Close) / 3
2. Calculate the moving average of the typical price: The moving average is computed over a specified period, typically 14 or 20 days.
3. Calculate the mean deviation: For each period, subtract the moving average from the typical price, and take the absolute value of the result. Then, compute the average of these absolute values over the specified period.
4. Calculate the CCI: Divide the difference between the typical price and its moving average by the product of the mean deviation and a constant, typically 0.015.
CCI = (Typical Price - Moving Average) / (0.015 * Mean Deviation)
Why CCI is Used and Its Advantages over Other Indicators
The CCI offers several advantages over other technical indicators, making it a popular choice among traders and analysts:
1. Versatility: Although initially developed for commodities, the CCI has proven to be effective in analyzing a wide range of financial instruments, including stocks, currencies, and indices. Its adaptability to different markets and timeframes makes it a valuable tool for various trading strategies.
2. Identification of overbought and oversold conditions: The CCI measures the strength of the price movement relative to its historical average. When the CCI reaches extreme values, it can signal overbought or oversold conditions, indicating potential trend reversals or price corrections.
3. Confirmation of price trends: The CCI can help traders confirm the presence of a price trend by identifying periods of strong momentum. A rising CCI indicates increasing positive momentum, while a falling CCI suggests increasing negative momentum.
4. Divergence analysis: Traders can use the CCI to identify divergences between the indicator and price action. For example, if the price reaches a new high, but the CCI fails to reach a corresponding high, it can signal a weakening trend and potential reversal.
5. Independent of price scale: Unlike some other technical indicators, the CCI is not affected by the price scale of the asset being analyzed. This characteristic allows traders to apply the CCI consistently across various instruments and markets.
The Commodity Channel Index is a powerful and versatile technical analysis tool that has stood the test of time. Developed to address the unique challenges of the commodities markets, the CCI has evolved into an essential tool for traders and analysts in various financial markets. Its ability to identify trends, reversals, and trading opportunities, as well as its versatility and adaptability, sets it apart from other technical indicators. By incorporating the CCI into their analytical toolkit, traders can gain valuable insights into market conditions, enabling them to make more informed decisions and improve their overall trading performance.
As financial markets continue to evolve and grow more complex, the importance of reliable and versatile technical analysis tools like the CCI cannot be overstated. In an environment characterized by rapidly changing market conditions, the ability to quickly identify trends, reversals, and potential trading opportunities is crucial for success. The CCI's adaptability to different markets, timeframes, and instruments makes it an indispensable resource for traders seeking to navigate the increasingly dynamic financial landscape.
Additionally, the CCI can be effectively combined with other technical analysis tools, such as moving averages, trend lines, and candlestick patterns, to create a more comprehensive and robust trading strategy. By using the CCI in conjunction with these complementary techniques, traders can develop a more nuanced understanding of market behavior and enhance their ability to identify high-probability trading opportunities.
In conclusion, the Commodity Channel Index is a valuable and versatile tool in the world of technical analysis. Its ability to adapt to various market conditions and provide insights into price trends, reversals, and trading opportunities make it an essential resource for traders and analysts alike. As the financial markets continue to evolve, the CCI's proven track record and adaptability ensure that it will remain a cornerstone of technical analysis for years to come.
What is the Smoother Moving Average?
The smoother function is a custom algorithm designed to smooth the price data of a financial asset using a moving average technique. It takes the price (src) and the period of the rolling window sample (len) to reduce noise in the data and reveal underlying trends.
smoother(float src, int len)=>
wrk = src, wrk2 = src, wrk4 = src
wrk0 = 0., wrk1 = 0., wrk3 = 0.
alpha = 0.45 * (len - 1.0) / (0.45 * (len - 1.0) + 2.0)
wrk0 := src + alpha * (nz(wrk ) - src)
wrk1 := (src - wrk) * (1 - alpha) + alpha * nz(wrk1 )
wrk2 := wrk0 + wrk1
wrk3 := (wrk2 - nz(wrk4 )) * math.pow(1.0 - alpha, 2) + math.pow(alpha, 2) * nz(wrk3 )
wrk4 := wrk3 + nz(wrk4 )
wrk4
Here's a detailed breakdown of the code, explaining each step and its purpose:
1. wrk, wrk2, and wrk4: These variables are assigned the value of src, which represents the source price of the asset. This step initializes the variables with the current price data, serving as a starting point for the smoothing calculations.
wrk0, wrk1, and wrk3: These variables are initialized to 0. They will be used as temporary variables to hold intermediate results during the calculations.
Calculation of the alpha parameter:
2. The alpha parameter is calculated using the formula: 0.45 * (len - 1.0) / (0.45 * (len - 1.0) + 2.0). The purpose of this calculation is to determine the smoothing factor that will be used in the subsequent calculations. This factor will influence the balance between responsiveness to recent price changes and smoothness of the resulting moving average. A higher value of alpha will result in a more responsive moving average, while a lower value will produce a smoother curve.
Calculation of wrk0:
3. wrk0 is updated with the expression: src + alpha * (nz(wrk ) - src). This step calculates the first component of the moving average, which is based on the current price (src) and the previous value of wrk (if it exists, otherwise 0 is used). This calculation applies the alpha parameter to weight the contribution of the previous wrk value, effectively making the moving average more responsive to recent price changes.
Calculation of wrk1:
4. wrk1 is updated with the expression: (src - wrk) * (1 - alpha) + alpha * nz(wrk1 ). This step calculates the second component of the moving average, which is based on the difference between the current price (src) and the current value of wrk. The alpha parameter is used to weight the contribution of the previous wrk1 value, allowing the moving average to be even more responsive to recent price changes.
Calculation of wrk2:
5. wrk2 is updated with the expression: wrk0 + wrk1. This step combines the first and second components of the moving average (wrk0 and wrk1) to produce a preliminary smoothed value.
Calculation of wrk3:
6. wrk3 is updated with the expression: (wrk2 - nz(wrk4 )) * math.pow(1.0 - alpha, 2) + math.pow(alpha, 2) * nz(wrk3 ). This step refines the preliminary smoothed value (wrk2) by accounting for the differences between the current smoothed value and the previous smoothed values (wrk4 and wrk3 ). The alpha parameter is used to weight the contributions of the previous smoothed values, providing a balance between smoothness and responsiveness.
Calculation of wrk4:
7. Calculation of wrk4:
wrk4 is updated with the expression: wrk3 + nz(wrk4 ). This step combines the refined smoothed value (wrk3) with the previous smoothed value (wrk4 , or 0 if it doesn't exist) to produce the final smoothed value. The purpose of this step is to ensure that the resulting moving average incorporates information from past values, making it smoother and more representative of the underlying trend.
8. Return wrk4:
The function returns the final smoothed value wrk4. This value represents the Smoother Moving Average for the given data point in the price series.
In summary, the smoother function calculates a custom moving average by using a series of steps to weight and combine recent price data with past smoothed values. The resulting moving average is more responsive to recent price changes while still maintaining a smooth curve, which helps reveal underlying trends and reduce noise in the data. The alpha parameter plays a key role in balancing the responsiveness and smoothness of the moving average, allowing users to customize the behavior of the algorithm based on their specific needs and preferences.
What is the CCI Adaptive Smoother?
The Commodity Channel Index (CCI) Adaptive Smoother is an innovative technical analysis tool that combines the benefits of the CCI indicator with a Smoother Moving Average. By adapting the CCI calculation based on the current market volatility, this method offers a more responsive and flexible approach to identifying potential trends and trading signals in financial markets.
The CCI is a momentum-based oscillator designed to determine whether an asset is overbought or oversold. It measures the difference between the typical price of an asset and its moving average, divided by the mean absolute deviation of the typical price. The traditional CCI calculation relies on a fixed period, which may not be suitable for all market conditions, as volatility can change over time.
The introduction of the Smoother Moving Average to the CCI calculation addresses this limitation. The Smoother Moving Average is a custom smoothing algorithm that combines elements of exponential moving averages with additional calculations to fine-tune the smoothing effect based on a given parameter. This algorithm assigns more importance to recent data points, making it more sensitive to recent changes in the data.
The CCI Adaptive Smoother dynamically adjusts the period of the Smoother Moving Average based on the current market volatility. This is accomplished by calculating the standard deviation of the close prices over a specified period and then computing the simple moving average of the standard deviation. By comparing the average standard deviation with the current standard deviation, the adaptive period for the Smoother Moving Average can be determined.
This adaptive approach allows the CCI Adaptive Smoother to be more responsive to changing market conditions. In periods of high volatility, the adaptive period will be shorter, resulting in a more responsive moving average. Conversely, in periods of low volatility, the adaptive period will be longer, producing a smoother moving average. This flexibility enables the CCI Adaptive Smoother to better identify trends and potential trading signals in a variety of market environments.
Furthermore, the CCI Adaptive Smoother is a prime example of the evolution of technical analysis methodologies. As markets continue to become more complex and dynamic, it is crucial for analysts and traders to adapt and improve their techniques to stay competitive. The incorporation of adaptive algorithms, like the Smoother Moving Average, demonstrates the potential for blending traditional indicators with cutting-edge methods to create more powerful and versatile tools for market analysis.
The versatility of the CCI Adaptive Smoother makes it suitable for various trading strategies, including trend-following, mean-reversion, and breakout systems. By providing a more precise measurement of overbought and oversold conditions, the CCI Adaptive Smoother can help traders identify potential entry and exit points with greater accuracy. Additionally, its responsiveness to changing market conditions allows for more timely adjustments in trading positions, reducing the risk of holding onto losing trades.
While the CCI Adaptive Smoother is a valuable tool, it is essential to remember that no single indicator can provide a complete picture of the market. As seasoned analysts and traders, we must always consider a holistic approach, incorporating multiple indicators and techniques to confirm signals and validate our trading decisions. By combining the CCI Adaptive Smoother with other technical analysis tools, such as trend lines, support and resistance levels, and candlestick patterns, traders can develop a more comprehensive understanding of the market and make more informed decisions.
The development of the CCI Adaptive Smoother also highlights the increasing importance of computational power and advanced algorithms in the field of technical analysis. As financial markets become more interconnected and influenced by various factors, including macroeconomic events, geopolitical developments, and technological innovations, the need for sophisticated tools to analyze and interpret complex data sets becomes even more critical.
Machine learning and artificial intelligence (AI) are becoming increasingly relevant in the world of trading and investing. These technologies have the potential to revolutionize how technical analysis is performed, by automating the discovery of patterns, relationships, and trends in the data. By leveraging machine learning algorithms and AI-driven techniques, traders can uncover hidden insights, improve decision-making processes, and optimize trading strategies.
The CCI Adaptive Smoother is just one example of how advanced algorithms can enhance traditional technical indicators. As the adoption of machine learning and AI continues to grow in the financial sector, we can expect to see the emergence of even more sophisticated and powerful analysis tools. These innovations will undoubtedly lead to a new era of technical analysis, where the ability to quickly adapt to changing market conditions and extract meaningful insights from complex data becomes increasingly critical for success.
In conclusion, the CCI Adaptive Smoother is an essential step forward in the evolution of technical analysis. It demonstrates the potential for combining traditional indicators with advanced algorithms to create more responsive and versatile tools for market analysis. As technology continues to advance and reshape the financial landscape, it is crucial for traders and analysts to stay informed and embrace innovation. By integrating cutting-edge tools like the CCI Adaptive Smoother into their arsenal, traders can gain a competitive edge and enhance their ability to navigate the increasingly complex world of financial markets.
Additional Features
This indicator allows you to select from 33 source types. They are as follows:
Close
Open
High
Low
Median
Typical
Weighted
Average
Average Median Body
Trend Biased
Trend Biased (Extreme)
HA Close
HA Open
HA High
HA Low
HA Median
HA Typical
HA Weighted
HA Average
HA Average Median Body
HA Trend Biased
HA Trend Biased (Extreme)
HAB Close
HAB Open
HAB High
HAB Low
HAB Median
HAB Typical
HAB Weighted
HAB Average
HAB Average Median Body
HAB Trend Biased
HAB Trend Biased (Extreme)
What are Heiken Ashi "better" candles?
Heiken Ashi "better" candles are a modified version of the standard Heiken Ashi candles, which are a popular charting technique used in technical analysis. Heiken Ashi candles help traders identify trends and potential reversal points by smoothing out price data and reducing market noise. The "better formula" was proposed by Sebastian Schmidt in an article published by BNP Paribas in Warrants & Zertifikate, a German magazine, in August 2004. The aim of this formula is to further improve the smoothing of the Heiken Ashi chart and enhance its effectiveness in identifying trends and reversals.
Standard Heiken Ashi candles are calculated using the following formulas:
Heiken Ashi Close = (Open + High + Low + Close) / 4
Heiken Ashi Open = (Previous Heiken Ashi Open + Previous Heiken Ashi Close) / 2
Heiken Ashi High = Max (High, Heiken Ashi Open, Heiken Ashi Close)
Heiken Ashi Low = Min (Low, Heiken Ashi Open, Heiken Ashi Close)
The "better formula" modifies the standard Heiken Ashi calculation by incorporating additional smoothing, which can help reduce noise and make it easier to identify trends and reversals. The modified formulas for Heiken Ashi "better" candles are as follows:
Better Heiken Ashi Close = (Open + High + Low + Close) / 4
Better Heiken Ashi Open = (Previous Better Heiken Ashi Open + Previous Better Heiken Ashi Close) / 2
Better Heiken Ashi High = Max (High, Better Heiken Ashi Open, Better Heiken Ashi Close)
Better Heiken Ashi Low = Min (Low, Better Heiken Ashi Open, Better Heiken Ashi Close)
Smoothing Factor = 2 / (N + 1), where N is the chosen period for smoothing
Smoothed Better Heiken Ashi Open = (Better Heiken Ashi Open * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Open * (1 - Smoothing Factor))
Smoothed Better Heiken Ashi Close = (Better Heiken Ashi Close * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Close * (1 - Smoothing Factor))
The smoothed Better Heiken Ashi Open and Close values are then used to calculate the smoothed Better Heiken Ashi High and Low values, resulting in "better" candles that provide a clearer representation of the market trend and potential reversal points.
It's important to note that, like any other technical analysis tool, Heiken Ashi "better" candles are not foolproof and should be used in conjunction with other indicators and analysis techniques to make well-informed trading decisions.
Heiken Ashi "better" candles, as mentioned previously, provide a clearer representation of market trends and potential reversal points by reducing noise and smoothing out price data. When using these candles in conjunction with other technical analysis tools and indicators, traders can gain valuable insights into market behavior and make more informed decisions.
To effectively use Heiken Ashi "better" candles in your trading strategy, consider the following tips:
Trend Identification: Heiken Ashi "better" candles can help you identify the prevailing trend in the market. When the majority of the candles are green (or another color, depending on your chart settings) and there are no or few lower wicks, it may indicate a strong uptrend. Conversely, when the majority of the candles are red (or another color) and there are no or few upper wicks, it may signal a strong downtrend.
Trend Reversals: Look for potential trend reversals when a change in the color of the candles occurs, especially when accompanied by longer wicks. For example, if a green candle with a long lower wick is followed by a red candle, it could indicate a bearish reversal. Similarly, a red candle with a long upper wick followed by a green candle may suggest a bullish reversal.
Support and Resistance: You can use Heiken Ashi "better" candles to identify potential support and resistance levels. When the candles are consistently moving in one direction and then suddenly change color with longer wicks, it could indicate the presence of a support or resistance level.
Stop-Loss and Take-Profit: Using Heiken Ashi "better" candles can help you manage risk by determining optimal stop-loss and take-profit levels. For instance, you can place your stop-loss below the low of the most recent green candle in an uptrend or above the high of the most recent red candle in a downtrend.
Confirming Signals: Heiken Ashi "better" candles should be used in conjunction with other technical indicators, such as moving averages, oscillators, or chart patterns, to confirm signals and improve the accuracy of your analysis.
In this implementation, you have the choice of AMA, KAMA, or T3 smoothing. These are as follows:
Kaufman Adaptive Moving Average (KAMA)
The Kaufman Adaptive Moving Average (KAMA) is a type of adaptive moving average used in technical analysis to smooth out price fluctuations and identify trends. The KAMA adjusts its smoothing factor based on the market's volatility, making it more responsive in volatile markets and smoother in calm markets. The KAMA is calculated using three different efficiency ratios that determine the appropriate smoothing factor for the current market conditions. These ratios are based on the noise level of the market, the speed at which the market is moving, and the length of the moving average. The KAMA is a popular choice among traders who prefer to use adaptive indicators to identify trends and potential reversals.
Adaptive Moving Average
The Adaptive Moving Average (AMA) is a type of moving average that adjusts its sensitivity to price movements based on market conditions. It uses a ratio between the current price and the highest and lowest prices over a certain lookback period to determine its level of smoothing. The AMA can help reduce lag and increase responsiveness to changes in trend direction, making it useful for traders who want to follow trends while avoiding false signals. The AMA is calculated by multiplying a smoothing constant with the difference between the current price and the previous AMA value, then adding the result to the previous AMA value.
T3
The T3 moving average is a type of technical indicator used in financial analysis to identify trends in price movements. It is similar to the Exponential Moving Average (EMA) and the Double Exponential Moving Average (DEMA), but uses a different smoothing algorithm.
The T3 moving average is calculated using a series of exponential moving averages that are designed to filter out noise and smooth the data. The resulting smoothed data is then weighted with a non-linear function to produce a final output that is more responsive to changes in trend direction.
The T3 moving average can be customized by adjusting the length of the moving average, as well as the weighting function used to smooth the data. It is commonly used in conjunction with other technical indicators as part of a larger trading strategy.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: CCI Adaptive Smoother as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: CCI Adaptive Smoother
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

GKD-C Adaptive-Lookback Phase Change Index [Loxx]Giga Kaleidoscope GKD-C Adaptive-Lookback Phase Change Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C Adaptive-Lookback Phase Change Index
What is the Phase Change Index?
The Phase Change Index (PCI) is a technical indicator that has gained popularity among traders in recent years. It is used to identify market phases and make profitable trades based on momentum and price data. The PCI was developed by M.H. Pee and first introduced in the Stocks & Commodities magazine in 2004.
The PCI is calculated using the 35-day momentum and the 35-day price channel index (PCI). The momentum is the difference between the current day's close and the close 35 days ago, while the PCI measures the distance between the highest high and lowest low over a period of 35 days. By combining these two indicators, traders can identify six possible market phases, each with its own trading strategy.
The formula for calculating the Phase Change Index (PCI) is as follows:
PCI = 100 * (C - L) / (H - L)
Where:
- C is the closing price of the current day
- L is the lowest low over a period of 35 days
- H is the highest high over a period of 35 days
The formula for calculating momentum is as follows:
Momentum = C - Cn
Where:
- C is the closing price of the current day
- Cn is the closing price n days ago, where n = 35 in this case.
The first two phases are characterized by negative momentum, with phase one having a low PCI value (less than 20) and phase two having a high PCI value (greater than 80). In these phases, traders should enter short positions. The next two phases have positive momentum, with phase three having a low PCI value and phase four having a high PCI value. In these phases, traders should enter long positions.
The final two phases are characterized by neutral momentum, with phase five having a low PCI value and phase six having a high PCI value. In these phases, traders should maintain their previous positions until there is a clear signal to enter or exit.
Traders can also use other technical indicators in conjunction with the PCI to confirm signals or filter out false signals. For example, some traders use moving averages or trendlines to confirm trend direction before entering a trade based on the PCI.
In conclusion, the Phase Change Index is a powerful technical indicator that can help traders identify market phases and make profitable trades. By combining momentum and price data, traders can enter long or short positions based on the six possible market phases. Backtesting results have shown that the PCI is robust across parameters, markets, and years. However, it is important to use proper risk management and not rely solely on past profitability when making trading decisions.
What is the Jurik Filter?
The Jurik Filter is a technical analysis tool that is used to filter out market noise and identify trends in financial markets. It was developed by Mark Jurik in the 1990s and is based on a non-linear smoothing algorithm that provides a more accurate representation of price movements.
Traditional moving averages, such as the Simple Moving Average ( SMA ) or Exponential Moving Average ( EMA ), are linear filters that produce a lag between price and the moving average line. This can cause false signals during periods of market volatility , which can result in losses for traders and investors.
The Jurik Filter is designed to address this issue by incorporating a damping factor into the smoothing algorithm. This damping factor adjusts the filter's responsiveness to the changes in price, allowing it to filter out market noise without overshooting price peaks and valleys.
The Jurik Filter is calculated using a mathematical formula that takes into account the current and past prices of an asset, as well as the volatility of the market. This formula incorporates the damping factor and produces a smoother price curve than traditional moving average filters.
One of the advantages of the Jurik Filter is its ability to adjust to changing market conditions. The damping factor can be adjusted to suit different securities and time frames, making it a versatile tool for traders and investors.
Traders and investors often use the Jurik Filter in conjunction with other technical analysis tools, such as the MACD or RSI , to confirm or complement their trading strategies. By filtering out market noise and identifying trends in the financial markets, the Jurik Filter can help improve the accuracy of trading signals and reduce the risks of false signals during periods of market volatility .
Overall, the Jurik Filter is a powerful technical analysis tool that can help traders and investors make more informed decisions about buying and selling securities. By providing a smoother price curve and reducing false signals, it can help improve trading performance and reduce risk in volatile markets.
What is the Adaptive Lookback Period?
The adaptive lookback period is a technique used in technical analysis to adjust the period of an indicator based on changes in market conditions. This technique is particularly useful in volatile or rapidly changing markets where a fixed period may not be optimal for detecting trends or signals.
The concept of the adaptive lookback period is relatively simple. By adjusting the lookback period based on changes in market conditions, traders can more accurately identify trends and signals. This can help traders to enter and exit trades at the right time and improve the profitability of their trading strategies.
The adaptive lookback period works by identifying potential swing points in the market. Once these points are identified, the lookback period is calculated based on the number of swings and a speed parameter. The swing count parameter determines the number of swings that must occur before the lookback period is adjusted. The speed parameter controls the rate at which the lookback period is adjusted, with higher values indicating a more rapid adjustment.
The adaptive lookback period can be applied to a wide range of technical indicators, including moving averages, oscillators, and trendlines. By adjusting the period of these indicators based on changes in market conditions, traders can reduce the impact of noise and false signals, leading to more profitable trades.
In summary, the adaptive lookback period is a powerful technique for traders and analysts looking to optimize their technical indicators. By adjusting the period based on changes in market conditions, traders can more accurately identify trends and signals, leading to more profitable trades. While there are various ways to implement the adaptive lookback period, the basic concept remains the same, and traders can adapt and customize the technique to suit their individual needs and trading styles.
What is the Adaptive-Lookback Phase Change Index?
The combination of adaptive lookback and Jurik filtering is an effective technique used in technical analysis to filter out market noise and improve the accuracy of trading signals. When applied to the Phase Change Index (PCI) indicator, the adaptive lookback period can be used to adjust the period of the indicator based on changes in market conditions. Jurik filtering can then be used to filter out market noise and improve the accuracy of the signals produced by the PCI indicator.
The adaptive lookback period is particularly useful in volatile or rapidly changing markets where a fixed period may not be optimal for detecting trends or signals. By adjusting the lookback period based on changes in market conditions, traders can more accurately identify trends and signals, leading to more profitable trades.
Jurik filtering is a more advanced filtering technique that uses a combination of smoothing and phase shift to produce a more accurate signal. This technique is particularly useful in filtering out market noise and improving the accuracy of trading signals. Jurik filtering can be applied to various indicators, including moving averages, oscillators, and trendlines.
Overall, the combination of adaptive lookback and Jurik filtering is a powerful technique used in technical analysis to filter out market noise and improve the accuracy of trading signals. When applied to the Phase Change Index (PCI) indicator, this technique is particularly effective in identifying trend changes and producing more accurate signals for entry and exit points in trading strategies.
Keep in mind, this is an inverse indicator meaning that above the middle-line/signal is short, below is long.
Additional Features
This indicator allows you to select from 33 source types. They are as follows:
Close
Open
High
Low
Median
Typical
Weighted
Average
Average Median Body
Trend Biased
Trend Biased (Extreme)
HA Close
HA Open
HA High
HA Low
HA Median
HA Typical
HA Weighted
HA Average
HA Average Median Body
HA Trend Biased
HA Trend Biased (Extreme)
HAB Close
HAB Open
HAB High
HAB Low
HAB Median
HAB Typical
HAB Weighted
HAB Average
HAB Average Median Body
HAB Trend Biased
HAB Trend Biased (Extreme)
What are Heiken Ashi "better" candles?
Heiken Ashi "better" candles are a modified version of the standard Heiken Ashi candles, which are a popular charting technique used in technical analysis. Heiken Ashi candles help traders identify trends and potential reversal points by smoothing out price data and reducing market noise. The "better formula" was proposed by Sebastian Schmidt in an article published by BNP Paribas in Warrants & Zertifikate, a German magazine, in August 2004. The aim of this formula is to further improve the smoothing of the Heiken Ashi chart and enhance its effectiveness in identifying trends and reversals.
Standard Heiken Ashi candles are calculated using the following formulas:
Heiken Ashi Close = (Open + High + Low + Close) / 4
Heiken Ashi Open = (Previous Heiken Ashi Open + Previous Heiken Ashi Close) / 2
Heiken Ashi High = Max (High, Heiken Ashi Open, Heiken Ashi Close)
Heiken Ashi Low = Min (Low, Heiken Ashi Open, Heiken Ashi Close)
The "better formula" modifies the standard Heiken Ashi calculation by incorporating additional smoothing, which can help reduce noise and make it easier to identify trends and reversals. The modified formulas for Heiken Ashi "better" candles are as follows:
Better Heiken Ashi Close = (Open + High + Low + Close) / 4
Better Heiken Ashi Open = (Previous Better Heiken Ashi Open + Previous Better Heiken Ashi Close) / 2
Better Heiken Ashi High = Max (High, Better Heiken Ashi Open, Better Heiken Ashi Close)
Better Heiken Ashi Low = Min (Low, Better Heiken Ashi Open, Better Heiken Ashi Close)
Smoothing Factor = 2 / (N + 1), where N is the chosen period for smoothing
Smoothed Better Heiken Ashi Open = (Better Heiken Ashi Open * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Open * (1 - Smoothing Factor))
Smoothed Better Heiken Ashi Close = (Better Heiken Ashi Close * Smoothing Factor) + (Previous Smoothed Better Heiken Ashi Close * (1 - Smoothing Factor))
The smoothed Better Heiken Ashi Open and Close values are then used to calculate the smoothed Better Heiken Ashi High and Low values, resulting in "better" candles that provide a clearer representation of the market trend and potential reversal points.
It's important to note that, like any other technical analysis tool, Heiken Ashi "better" candles are not foolproof and should be used in conjunction with other indicators and analysis techniques to make well-informed trading decisions.
Heiken Ashi "better" candles, as mentioned previously, provide a clearer representation of market trends and potential reversal points by reducing noise and smoothing out price data. When using these candles in conjunction with other technical analysis tools and indicators, traders can gain valuable insights into market behavior and make more informed decisions.
To effectively use Heiken Ashi "better" candles in your trading strategy, consider the following tips:
Trend Identification: Heiken Ashi "better" candles can help you identify the prevailing trend in the market. When the majority of the candles are green (or another color, depending on your chart settings) and there are no or few lower wicks, it may indicate a strong uptrend. Conversely, when the majority of the candles are red (or another color) and there are no or few upper wicks, it may signal a strong downtrend.
Trend Reversals: Look for potential trend reversals when a change in the color of the candles occurs, especially when accompanied by longer wicks. For example, if a green candle with a long lower wick is followed by a red candle, it could indicate a bearish reversal. Similarly, a red candle with a long upper wick followed by a green candle may suggest a bullish reversal.
Support and Resistance: You can use Heiken Ashi "better" candles to identify potential support and resistance levels. When the candles are consistently moving in one direction and then suddenly change color with longer wicks, it could indicate the presence of a support or resistance level.
Stop-Loss and Take-Profit: Using Heiken Ashi "better" candles can help you manage risk by determining optimal stop-loss and take-profit levels. For instance, you can place your stop-loss below the low of the most recent green candle in an uptrend or above the high of the most recent red candle in a downtrend.
Confirming Signals: Heiken Ashi "better" candles should be used in conjunction with other technical indicators, such as moving averages, oscillators, or chart patterns, to confirm signals and improve the accuracy of your analysis.
In this implementation, you have the choice of AMA, KAMA, or T3 smoothing. These are as follows:
Kaufman Adaptive Moving Average (KAMA)
The Kaufman Adaptive Moving Average (KAMA) is a type of adaptive moving average used in technical analysis to smooth out price fluctuations and identify trends. The KAMA adjusts its smoothing factor based on the market's volatility, making it more responsive in volatile markets and smoother in calm markets. The KAMA is calculated using three different efficiency ratios that determine the appropriate smoothing factor for the current market conditions. These ratios are based on the noise level of the market, the speed at which the market is moving, and the length of the moving average. The KAMA is a popular choice among traders who prefer to use adaptive indicators to identify trends and potential reversals.
Adaptive Moving Average
The Adaptive Moving Average (AMA) is a type of moving average that adjusts its sensitivity to price movements based on market conditions. It uses a ratio between the current price and the highest and lowest prices over a certain lookback period to determine its level of smoothing. The AMA can help reduce lag and increase responsiveness to changes in trend direction, making it useful for traders who want to follow trends while avoiding false signals. The AMA is calculated by multiplying a smoothing constant with the difference between the current price and the previous AMA value, then adding the result to the previous AMA value.
T3
The T3 moving average is a type of technical indicator used in financial analysis to identify trends in price movements. It is similar to the Exponential Moving Average (EMA) and the Double Exponential Moving Average (DEMA), but uses a different smoothing algorithm.
The T3 moving average is calculated using a series of exponential moving averages that are designed to filter out noise and smooth the data. The resulting smoothed data is then weighted with a non-linear function to produce a final output that is more responsive to changes in trend direction.
The T3 moving average can be customized by adjusting the length of the moving average, as well as the weighting function used to smooth the data. It is commonly used in conjunction with other technical indicators as part of a larger trading strategy.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Adaptive-Lookback Phase Change Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.
GKD-C STD-Filtered, Adaptive Exponential HMA [Loxx]Giga Kaleidoscope GKD-C STD-Filtered, Adaptive Exponential HMA is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ GKD-C STD-Filtered, Adaptive Exponential HMA
What is the STD-Filtered, Adaptive Exponential HMA?
The Adaptive Hull Moving Average (AHMA) is a powerful technical indicator that combines the advantages of both the Hull Moving Average (HMA) and adaptive filtering techniques. It is primarily used by traders and investors to identify trends in financial markets and generate buy/sell signals. This essay aims to provide a comprehensive understanding of the AHMA, its components, and its applications in trading and investing.
Components of Adaptive Hull Moving Average
Exponential Moving Average (EMA)
The EMA is a widely-used technical indicator that assigns more weight to recent data points, making it more responsive to new information. The EMA is calculated using a smoothing factor (alpha), which determines the degree of responsiveness.
Adaptive Alpha
The adaptive alpha is a crucial component of the AHMA, as it determines the optimal alpha value for the EMA calculations based on the market's signal-to-noise ratio (SNR). This adaptive approach ensures that the indicator responds appropriately to different market conditions, providing more accurate buy/sell signals.
Hull Moving Average (HMA)
The HMA is a popular technical indicator that combines the advantages of weighted moving averages and simple moving averages. The HMA is designed to be more responsive to price changes while reducing lag, making it a valuable tool for trend analysis.
Standard Deviation Filter
The standard deviation filter is an optional component of the AHMA that helps reduce noise in the input data series. By applying this filter, traders can further improve the accuracy of the AHMA, minimizing false signals.
How this is done
Important functions:
aEMA(float src, float alpha) =>
float ema = src
ema := na(ema ) ? src : nz(ema ) + alpha * (src - nz(ema ))
ema
adaptiveAlpha(float SNR, float periodL, float periodH)=>
float al = 2.0 / (periodL + 1.0)
float ah = 2.0 / (periodH + 1.0)
float out = (ah + SNR * (al - ah))
out
hullAdaptiveMovingAverage(float src, int persnr, int perfast, int perslow, int gain, float beta)=>
float signal = math.abs(src - nz(src ))
float noise = 0
for i = 0 to persnr - 1
noise += math.abs(nz(src ) - nz(src ))
float SNR = beta * signal / noise * math.sqrt(persnr)
float exp2SNR = math.exp(2.0 * SNR)
float tanhSNR = (exp2SNR - 1.0) / (exp2SNR + 1.0)
float w = math.pow(tanhSNR, gain)
float a1 = adaptiveAlpha(w, perfast * 0.5, perslow * 0.5)
float a2 = adaptiveAlpha(w, perfast, perslow)
float a3 = adaptiveAlpha(w, math.sqrt(perfast), math.sqrt(perslow))
float h1 = src
float h2 = src
float h3 = src
h1 := aEMA(h1, a1)
h2 := aEMA(h2, a2)
h3 := (2 * h1 - h2)
h3 := aEMA(h3, a3)
h3
stdFilter(float src, int len, float filter)=>
float price = src
float filtdev = filter * ta.stdev(src, len)
price := math.abs(price - nz(price )) < filtdev ? nz(price ) : price
price
1. aEMA(): This function calculates the exponential moving average (EMA) of a given data series (src) using the specified alpha value. It initializes the EMA with the data series and then calculates it recursively using the previous EMA and alpha value.
2. adaptiveAlpha(): This function calculates the adaptive alpha value based on the signal-to-noise ratio (SNR), the fast period (periodL), and the slow period (periodH). It computes the adaptive alpha by linearly interpolating between the fast and slow alpha values based on the SNR.
3. hullAdaptiveMovingAverage(): This function implements the AHMA by taking the input data series (src), the signal-to-noise ratio period (persnr), fast and slow periods (perfast, perslow), gain, and a beta value. It calculates the SNR by dividing the absolute difference between the current data point and its previous value (signal) by the sum of the absolute differences between consecutive data points (noise) over the specified SNR period. The function then computes the adaptive alpha values (a1, a2, a3) and calculates the Hull Moving Average (HMA) using three EMAs (h1, h2, h3).
4. stdFilter(): This function applies a standard deviation filter to the input data series (src) using the specified filter period (len) and filter coefficient (filter). It filters out the data points whose absolute difference from the previous data point is less than the specified multiple of the standard deviation.
The code computes the AHMA of the input data series (src) by applying the hullAdaptiveMovingAverage() function, and if the filter option is set to "Both" or "AEHMA" and the filter coefficient is greater than 0, the standard deviation filter is applied to the AHMA using the stdFilter() function. Finally, the output is stored in the variable "out," and the previous value of the output is stored in the variable "sig."
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: STD-Filtered, Adaptive Exponential HMA as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.
GKD-C Volatility Ratio Adaptive RSX [Loxx]Giga Kaleidoscope GKD-C Volatility Ratio Adaptive RSX is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Volatility Ratio Adaptive RSX as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
█ GKD-C Volatility Ratio Adaptive RSX
What is the RSX?
The Jurik RSX is a technical indicator developed by Mark Jurik to measure the momentum and strength of price movements in financial markets, such as stocks, commodities, and currencies. It is an advanced version of the traditional Relative Strength Index (RSI), designed to offer smoother and less lagging signals compared to the standard RSI.
The main advantage of the Jurik RSX is that it provides more accurate and timely signals for traders and analysts, thanks to its improved calculation methods that reduce noise and lag in the indicator's output. This enables better decision-making when analyzing market trends and potential trading opportunities.
What is the Voaltility Ratio?
The volatility ratio is a technical analysis indicator used by traders and investors to measure the relative volatility of a financial instrument, such as stocks, commodities, or forex. It is calculated by comparing the True Range (TR) of the instrument to its average range over a specified period, typically expressed as a percentage. The higher the volatility ratio, the more volatile the instrument is considered to be.
The formula for the volatility ratio is:
Volatility Ratio (VR) = (Today's True Range) / (Average True Range over a specified period)
Where:
Today's True Range is the highest value among:
Current High - Current Low
Current High - Previous Close
Current Low - Previous Close
Average True Range (ATR) is the average of the True Range values over a specified period, typically 14 days.
Traders and investors use the volatility ratio to gauge the risk associated with a particular instrument and to identify potential entry and exit points. A high volatility ratio can signal strong price movements, while a low ratio may indicate stability or stagnation in price. The volatility ratio can also be used in conjunction with other technical indicators to create a more comprehensive trading strategy.
What is Volatility Ratio Adaptive RSX?
For this indicator the calculation of volatility is changed to the following:
Volatility Ratio (VR) = (Standard Deviation of Price) / (Simple Moving Average of Standard Deviation over a specified period)
Where:
src: source data (typically closing prices) of the financial instrument.
per: the period over which the standard deviation and simple moving average are calculated.
This version of the Volatility Ratio helps identify periods of high or low price volatility relative to the historical average over the specified period. A value above 1 indicates higher than average volatility, while a value below 1 suggests lower than average volatility. Traders and investors can use this indicator to assess the risk of a particular instrument, determine market sentiment, or identify potential trading opportunities.
What this looks like inside:
This code defines two functions, rsx() and volatratio(), and then calculates the Volatility Ratio Adaptive RSX by combining their outputs.
1. rsx(src, len, speed): This function calculates the Adaptive RSX (Relative Strength Index) based on the input source data (src), the lookback period (len), and the speed factor (speed). The function computes a smoothed version of the price momentum (mom_out) and its absolute version (moa_out) using an iterative process. The final output, rsiout, is the Adaptive RSX oscillator value, which is calculated by normalizing the momentum ratio to the 0-100 range.
2. volatratio(src, per): This function calculates the Volatility Ratio using the input source data (src) and the lookback period (per). It computes the standard deviation (dev) and its simple moving average (devavg) over the specified period, and then calculates the Volatility Ratio by dividing the standard deviation by its average.
The main part of the code calculates the Volatility Ratio Adaptive RSX using the rsx() and volatratio() functions:
-volRatio = volatratio(src, inpPeriod): It calculates the Volatility Ratio using the input source data (src) and the lookback period (inpPeriod).
-rsxout = _rsx(src, int(inpPeriod/volRatio), inpSpeed): It calculates the Adaptive RSX using the input source data (src), the adjusted lookback period (which is the original period divided by the Volatility Ratio), and the speed factor (inpSpeed).
The final output, rsxout, represents the Volatility Ratio Adaptive RSX oscillator. Traders can use this oscillator to identify potential entry and exit points, confirm trends, or detect price reversals based on overbought or oversold conditions.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

GKD-C PA-Adaptive T3 Loxxer [Loxx]Giga Kaleidoscope GKD-C PA-Adaptive T3 Loxxer is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: PA-Adaptive T3 Loxxer as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
█ GKD-C PA-Adaptive T3 Loxxer
What is the T3?
The T3 Moving Average (T3MA) is a technical analysis indicator that was developed by Tim Tillson. It is a trend-following indicator that aims to provide a smoother and more accurate representation of price trends than other moving average indicators.
The T3MA is a type of exponential moving average ( EMA ) that is calculated using a series of complex formulas. Unlike a simple or exponential moving average , which use fixed smoothing factors, the T3MA uses a variable smoothing factor that is based on the volatility of the underlying asset. This means that the T3MA is able to adapt to changing market conditions and provide more accurate signals.
The formula for calculating the T3MA is as follows:
T3 = a * EMA1 + (1 - a) * T3
Where:
-T3 is the current value of the T3MA
-EMA1 is the current value of the first EMA
-T3 is the previous value of the T3MA
-a is the smoothing factor, which is based on the volatility of the underlying asset and is calculated using the following formulas:
-c1 = -1 + exp (-sqrt(2) * pi / period)
-c2 = 2 * c1 * c1 + 2 * c1
-c3 = 1 - c1 - c2
-a = c1 * sqrt(period) * (close - T3) + c2 * T3 + c3 * EMA1
In simple terms, the T3MA is calculated by taking a weighted average of two different EMAs, with the weight given to each EMA depending on the volatility of the asset being analyzed. The T3MA is then smoothed using a second smoothing factor, which further reduces noise and improves the accuracy of the indicator.
The T3MA can be used in a variety of ways by traders and analysts. Some common applications include using the T3MA as a trend-following indicator, with buy signals generated when the price of an asset crosses above the T3MA and sell signals generated when the price crosses below. The T3MA can also be used in combination with other indicators and analytical techniques to confirm trading decisions and identify potential trend reversals.
Overall, the T3 Moving Average is a highly sophisticated and complex technical indicator that is designed to provide a more accurate and reliable representation of price trends. While it may be difficult for novice traders to understand and use effectively, experienced traders and analysts may find the T3MA to be a valuable tool in their trading toolbox.
What is the Phase Accumulation Cycle?
The Phase Accumulation Cycle Period by Ehlers is a concept developed by Dr. John Ehlers, an expert in the field of technical analysis and digital signal processing for financial markets. The Phase Accumulation Cycle Period is a technique used to estimate the dominant cycle period in a financial time series, such as stock prices or market indices. It is based on the premise that financial markets are cyclical in nature, and understanding the underlying cycles can help traders and investors make better-informed decisions.
The Phase Accumulation method works by accumulating the phase of the input data over a specific number of bars or periods, and then measuring the difference between the current and prior phase. This difference represents the change in phase over the specified accumulation period. The method uses a combination of digital signal processing techniques, such as complex demodulation and Hilbert Transform, to determine the phase and amplitude of the underlying cycles.
One of the key benefits of the Phase Accumulation Cycle Period is that it is less sensitive to noise and provides a more stable estimation of the cycle period when compared to other methods, such as the traditional spectral analysis techniques. This makes it particularly useful for analyzing noisy financial time series data.
Dr. Ehlers has published several papers and books on the subject, and his work is widely respected in the field of technical analysis. If you are interested in learning more about the Phase Accumulation Cycle Period and other techniques developed by Dr. Ehlers, you may want to explore his publications, such as "Rocket Science for Traders" and "Cycle Analytics for Traders."
My apologies for not providing the details and formulas in my previous response. Here's a more detailed explanation of the Phase Accumulation Cycle Period by Ehlers, including the relevant formulas.
The Phase Accumulation Cycle Period calculation involves the following steps:
1. Apply the Hilbert Transform to the input data: The Hilbert Transform is a mathematical technique used to calculate the instantaneous phase and amplitude of a signal. The formula for the Hilbert Transform (HT) is:
HT(x) = (1/π) * ∫ dτ
Where x(τ) is the input data, t is the time index, and the integral is taken over the entire data length.
2. Calculate the instantaneous phase: The instantaneous phase (φ) is calculated as the arctangent of the ratio between the Hilbert Transform output and the input data.
φ(t) = arctan(HT(x(t)) / x(t))
3. Calculate the phase difference: The phase difference (Δφ) is the difference between the instantaneous phase at the current bar and the previous bar.
Δφ(t) = φ(t) - φ(t-1)
4. Accumulate the phase difference: The accumulated phase difference is the sum of the phase differences over a specified accumulation period (N).
ΣΔφ(t) = Σ for k = 0 to N-1
5. Calculate the average phase change: The average phase change (Δφ_avg) is the accumulated phase difference divided by the accumulation period (N).
Δφ_avg = ΣΔφ(t) / N
6. Estimate the cycle period: The estimated cycle period (P) is calculated using the following formula:
P = (2π) / Δφ_avg
The Phase Accumulation Cycle Period by Ehlers is the estimated cycle period (P) derived from the above calculations. The technique is designed to provide a more accurate and stable estimation of the dominant cycle period in a financial time series, which can be useful for market analysis, trading, and investing.
What is the Loxxer indicator?
The Loxxer Indicator is a technical analysis tool developed by Loxx. It is an oscillator that measures the demand of an asset, helping traders and investors identify potential buying and selling opportunities. The Loxxer Indicator compares the current maximum and minimum prices with those of the previous period, aiming to assess the directional pressure and the possible trend exhaustion points.
The Loxxer Indicator ranges between 0 and 1, with values above 0.7 generally considered overbought and values below 0.3 considered oversold. These overbought and oversold levels can provide potential entry or exit signals for traders.
Here's how the Loxxer Indicator is calculated:
1. Calculate LoxxMax: If the current high minus the previous high is greater than zero, LoxxMax equals the difference. If the result is less than or equal to zero, LoxxMax equals zero.
LoxxMax = max(current high - previous high, 0)
2. Calculate LoxxMin: If the previous low minus the current low is greater than zero, LoxxMin equals the difference. If the result is less than or equal to zero, LoxxMin equals zero.
LoxxMin = max(previous low - current low, 0)
3. Calculate the moving average of LoxxMax for the specified period (N):
LoxxMaxAvg = Simple Moving Average of LoxxMax over N periods
4. Calculate the moving average of LoxxMin for the specified period (N):
LoxxMinAvg = Simple Moving Average of LoxxMin over N periods
5. Calculate the Loxxer Indicator:
Loxxer = LoxxMaxAvg / (LoxxMaxAvg + LoxxMinAvg)
The Loxxer Indicator can be used in various ways, such as generating trading signals, identifying divergence, or confirming trends. Keep in mind that, like any other technical analysis tool, the Loxxer Indicator should be used in conjunction with other tools and techniques to increase the reliability of trading signals.
What is the PA-Adaptive T3 Loxxer?
This indicator computes the Phase Accumulation Cycle Period (dominant cycle period) and subsequently incorporates it into the Loxxer algorithm. Here, the Loxxer algorithm is equipped with T3 filtering. The T3 filter utilizes the Phase Accumulation dominant cycle period as its input for the period. This comprehensive computation generates an exceptionally smooth and rapid indicator.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.
GKD-C PA-Adaptive RSX [Loxx]Giga Kaleidoscope GKD-C PA-Adaptive RSX is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: PA-Adaptive RSX as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
█ GKD-C PA-Adaptive RSX
What is the RSX?
The Jurik RSX is a technical indicator developed by Mark Jurik to measure the momentum and strength of price movements in financial markets, such as stocks, commodities, and currencies. It is an advanced version of the traditional Relative Strength Index (RSI), designed to offer smoother and less lagging signals compared to the standard RSI.
The main advantage of the Jurik RSX is that it provides more accurate and timely signals for traders and analysts, thanks to its improved calculation methods that reduce noise and lag in the indicator's output. This enables better decision-making when analyzing market trends and potential trading opportunities.
What is the Phase Accumulation Cycle?
The Phase Accumulation Cycle Period by Ehlers is a concept developed by Dr. John Ehlers, an expert in the field of technical analysis and digital signal processing for financial markets. The Phase Accumulation Cycle Period is a technique used to estimate the dominant cycle period in a financial time series, such as stock prices or market indices. It is based on the premise that financial markets are cyclical in nature, and understanding the underlying cycles can help traders and investors make better-informed decisions.
The Phase Accumulation method works by accumulating the phase of the input data over a specific number of bars or periods, and then measuring the difference between the current and prior phase. This difference represents the change in phase over the specified accumulation period. The method uses a combination of digital signal processing techniques, such as complex demodulation and Hilbert Transform, to determine the phase and amplitude of the underlying cycles.
One of the key benefits of the Phase Accumulation Cycle Period is that it is less sensitive to noise and provides a more stable estimation of the cycle period when compared to other methods, such as the traditional spectral analysis techniques. This makes it particularly useful for analyzing noisy financial time series data.
Dr. Ehlers has published several papers and books on the subject, and his work is widely respected in the field of technical analysis. If you are interested in learning more about the Phase Accumulation Cycle Period and other techniques developed by Dr. Ehlers, you may want to explore his publications, such as "Rocket Science for Traders" and "Cycle Analytics for Traders."
My apologies for not providing the details and formulas in my previous response. Here's a more detailed explanation of the Phase Accumulation Cycle Period by Ehlers, including the relevant formulas.
The Phase Accumulation Cycle Period calculation involves the following steps:
1. Apply the Hilbert Transform to the input data: The Hilbert Transform is a mathematical technique used to calculate the instantaneous phase and amplitude of a signal. The formula for the Hilbert Transform (HT) is:
HT(x) = (1/π) * ∫ dτ
Where x(τ) is the input data, t is the time index, and the integral is taken over the entire data length.
2. Calculate the instantaneous phase: The instantaneous phase (φ) is calculated as the arctangent of the ratio between the Hilbert Transform output and the input data.
φ(t) = arctan(HT(x(t)) / x(t))
3. Calculate the phase difference: The phase difference (Δφ) is the difference between the instantaneous phase at the current bar and the previous bar.
Δφ(t) = φ(t) - φ(t-1)
4. Accumulate the phase difference: The accumulated phase difference is the sum of the phase differences over a specified accumulation period (N).
ΣΔφ(t) = Σ for k = 0 to N-1
5. Calculate the average phase change: The average phase change (Δφ_avg) is the accumulated phase difference divided by the accumulation period (N).
Δφ_avg = ΣΔφ(t) / N
6. Estimate the cycle period: The estimated cycle period (P) is calculated using the following formula:
P = (2π) / Δφ_avg
The Phase Accumulation Cycle Period by Ehlers is the estimated cycle period (P) derived from the above calculations. The technique is designed to provide a more accurate and stable estimation of the dominant cycle period in a financial time series, which can be useful for market analysis, trading, and investing.
What is the PA-Adaptive RSX?
This indcator calculates a Phase Accumulation Cycle Period (dominant cycle period) and then injects this value into the RSX formula as the period input. This purpose of this indicator is to identify longer price trends.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

GKD-C Schaff-Trend, Jurik-Volty-Adaptive RSX [Loxx]Giga Kaleidoscope GKD-C Schaff-Trend, Jurik-Volty-Adaptive RSX is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Schaff-Trend, Jurik-Volty-Adaptive RSX as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
█ GKD-C Schaff-Trend, Jurik-Volty-Adaptive RSX
The Schaff-Trend, Jurik-Volty-Adaptive RSX is an advanced moving average overlay indicator that incorporates adaptive period inputs from Jurik Volty into a Triple Exponential Moving Average (TEMA). The resulting value is further refined using a standard deviation filter to minimize noise. This adaptation aims to develop a faster TEMA that leads the standard, non-adaptive TEMA. However, during periods of low volatility, the output may be noisy, so a standard deviation filter is employed to decrease choppiness, yielding a highly responsive TEMA without the noise typically caused by low market volatility.
What is Jurik Volty?
Jurik Volty calculates the price volatility and relative price volatility factor.
The Jurik smoothing includes 3 stages:
1st stage - Preliminary smoothing by adaptive EMA
2nd stage - One more preliminary smoothing by Kalman filter
3rd stage - Final smoothing by unique Jurik adaptive filter
Here's a breakdown of the code:
1. volty(float src, int len) => defines a function called volty that takes two arguments: src, which represents the source price data (like close price), and len, which represents the length or period for calculating the indicator.
2. int avgLen = 65 sets the length for the Simple Moving Average (SMA) to 65.
3. Various variables are initialized like volty, voltya, bsmax, bsmin, and vsum.
4. len1 is calculated as math.max(math.log(math.sqrt(0.5 * (len-1))) / math.log(2.0) + 2.0, 0); this expression involves some mathematical transformations based on the len input. The purpose is to create a dynamic factor that will be used later in the calculations.
5. pow1 is calculated as math.max(len1 - 2.0, 0.5); this variable is another dynamic factor used in further calculations.
6. del1 and del2 represent the differences between the current src value and the previous values of bsmax and bsmin, respectively.
7. volty is assigned a value based on a conditional expression, which checks whether the absolute value of del1 is greater than the absolute value of del2. This step is essential for determining the direction and magnitude of the price change.
8. vsum is updated based on the previous value and the difference between the current and previous volty values.
9. The Simple Moving Average (SMA) of vsum is calculated with the length avgLen and assigned to avg.
10. Variables dVolty, pow2, len2, and Kv are calculated using various mathematical transformations based on previously calculated variables. These variables are used to adjust the Jurik Volty indicator based on the observed volatility.
11. The bsmax and bsmin variables are updated based on the calculated Kv value and the direction of the price change.
12. inally, the temp variable is calculated as the ratio of avolty to vsum. This value represents the Jurik Volty indicator's output and can be used to analyze the market trends and potential reversals.
Jurik Volty can be used to identify periods of high or low volatility and to spot potential trade setups based on price behavior near the volatility bands.
What is RSX?
The Jurik RSX ( Relative Strength Index ) is a technical indicator used in financial markets to measure the strength of price movement. It was developed by Mark Jurik and is based on the RSI formula, with the addition of smoothing and other modifications.
The Jurik RSX is designed to be smoother and more responsive than traditional RSI indicators, making it more useful for detecting trends and trading signals. It is also less prone to false signals and noise, which can be a problem with some other technical indicators.
The Jurik RSX can be used in a variety of ways, including as a trend-following indicator or a momentum indicator . It can also be combined with other indicators and trading strategies to improve overall performance.
What is the Schaff Trend Cycle indicator?
The Schaff Trend Cycle (STC) indicator is a technical analysis tool developed by Doug Schaff in the 1990s. It combines elements of both the Moving Average Convergence Divergence (MACD) and the Stochastic Oscillator, aiming to provide more accurate and timely signals for entering and exiting trades in financial markets.
The STC indicator attempts to identify the beginning and end of trends more effectively than traditional indicators. It does this by identifying cyclical movements in price data and smoothing out market noise, which can often lead to false signals in other indicators.
The general calculation for Schaff Trend Cycle indicator involves the following steps:
1. Calculate an Exponential Moving Average (EMA) of the price data with a short period (e.g., 23 periods).
2. Calculate an EMA of the price data with a longer period (e.g., 50 periods).
3. Subtract the longer EMA from the shorter EMA to obtain the MACD line.
4. Calculate an EMA of the MACD line with a short period (e.g., 10 periods).
5. Calculate the Stochastic Oscillator with the same period as the shorter EMA (e.g., 23 periods).
6. Subtract the lowest Stochastic value in the range from the current Stochastic value.
7. Divide the result by the range of the Stochastic values (i.e., highest - lowest) and multiply by 100 to get the Schaff Trend Cycle value.
The STC indicator can generate buy and sell signals based on crossovers. A buy signal occurs when the STC value crosses above a threshold, such as 25, while a sell signal occurs when the STC value crosses below a higher threshold, such as 75. These thresholds can be adjusted to suit different trading styles and market conditions.
What is the Schaff-Trend, Jurik-Volty-Adaptive RSX?
This indicator generates a Jurik-Volty-adaptive RSX of the Schaff Trend Cycle. This is computed by obtaining the RSX of the Schaff Trend Cycle with an adaptive period input, which is determined by a coefficient derived from Jurik Volty.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.
GKD-C STD-Filtered Jurik Volty Adaptive TEMA [Loxx]Giga Kaleidoscope GKD-C STD-Filtered Jurik Volty Adaptive TEMA is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: STD-Filtered Jurik Volty Adaptive TEMA as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit or Backtest"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit or Backtest"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
█ GKD-C STD-Filtered Jurik Volty Adaptive TEMA
The STD-Filtered Jurik Volty Adaptive TEMA is an advanced moving average overlay indicator that incorporates adaptive period inputs from Jurik Volty into a Triple Exponential Moving Average (TEMA). The resulting value is further refined using a standard deviation filter to minimize noise. This adaptation aims to develop a faster TEMA that leads the standard, non-adaptive TEMA. However, during periods of low volatility, the output may be noisy, so a standard deviation filter is employed to decrease choppiness, yielding a highly responsive TEMA without the noise typically caused by low market volatility.
What is Jurik Volty?
Jurik Volty calculates the price volatility and relative price volatility factor.
The Jurik smoothing includes 3 stages:
1st stage - Preliminary smoothing by adaptive EMA
2nd stage - One more preliminary smoothing by Kalman filter
3rd stage - Final smoothing by unique Jurik adaptive filter
Here's a breakdown of the code:
1. volty(float src, int len) => defines a function called volty that takes two arguments: src, which represents the source price data (like close price), and len, which represents the length or period for calculating the indicator.
2. int avgLen = 65 sets the length for the Simple Moving Average (SMA) to 65.
3. Various variables are initialized like volty, voltya, bsmax, bsmin, and vsum.
4. len1 is calculated as math.max(math.log(math.sqrt(0.5 * (len-1))) / math.log(2.0) + 2.0, 0); this expression involves some mathematical transformations based on the len input. The purpose is to create a dynamic factor that will be used later in the calculations.
5. pow1 is calculated as math.max(len1 - 2.0, 0.5); this variable is another dynamic factor used in further calculations.
6. del1 and del2 represent the differences between the current src value and the previous values of bsmax and bsmin, respectively.
7. volty is assigned a value based on a conditional expression, which checks whether the absolute value of del1 is greater than the absolute value of del2. This step is essential for determining the direction and magnitude of the price change.
8. vsum is updated based on the previous value and the difference between the current and previous volty values.
9. The Simple Moving Average (SMA) of vsum is calculated with the length avgLen and assigned to avg.
10. Variables dVolty, pow2, len2, and Kv are calculated using various mathematical transformations based on previously calculated variables. These variables are used to adjust the Jurik Volty indicator based on the observed volatility.
11. The bsmax and bsmin variables are updated based on the calculated Kv value and the direction of the price change.
12. inally, the temp variable is calculated as the ratio of avolty to vsum. This value represents the Jurik Volty indicator's output and can be used to analyze the market trends and potential reversals.
Jurik Volty can be used to identify periods of high or low volatility and to spot potential trade setups based on price behavior near the volatility bands.
What is the Triple Exponential Moving Average?
The Triple Exponential Moving Average (TEMA) is a technical indicator used by traders and investors to identify trends and price reversals in financial markets. It is a more advanced and responsive version of the Exponential Moving Average (EMA). TEMA was developed by Patrick Mulloy and introduced in the January 1994 issue of Technical Analysis of Stocks & Commodities magazine. The aim of TEMA is to minimize the lag associated with single and double exponential moving averages while also filtering out market noise, thus providing a smoother, more accurate representation of the market trend.
To understand TEMA, let's first briefly review the EMA.
Exponential Moving Average (EMA):
EMA is a weighted moving average that gives more importance to recent price data. The formula for EMA is:
EMA_t = (Price_t * α) + (EMA_(t-1) * (1 - α))
Where:
EMA_t: EMA at time t
Price_t: Price at time t
α: Smoothing factor (α = 2 / (N + 1))
N: Length of the moving average period
EMA_(t-1): EMA at time t-1
Triple Exponential Moving Average (TEMA):
Triple Exponential Moving Average (TEMA):
TEMA combines three exponential moving averages to provide a more accurate and responsive trend indicator. The formula for TEMA is:
TEMA = 3 * EMA_1 - 3 * EMA_2 + EMA_3
Where:
EMA_1: The first EMA of the price data
EMA_2: The EMA of EMA_1
EMA_3: The EMA of EMA_2
Here are the steps to calculate TEMA:
1. Choose the length of the moving average period (N).
2. Calculate the smoothing factor α (α = 2 / (N + 1)).
3. Calculate the first EMA (EMA_1) using the price data and the smoothing factor α.
4. Calculate the second EMA (EMA_2) using the values of EMA_1 and the same smoothing factor α.
5. Calculate the third EMA (EMA_3) using the values of EMA_2 and the same smoothing factor α.
5. Finally, compute the TEMA using the formula: TEMA = 3 * EMA_1 - 3 * EMA_2 + EMA_3
The Triple Exponential Moving Average, with its combination of three EMAs, helps to reduce the lag and filter out market noise more effectively than a single or double EMA. It is particularly useful for short-term traders who require a responsive indicator to capture rapid price changes. Keep in mind, however, that TEMA is still a lagging indicator, and as with any technical analysis tool, it should be used in conjunction with other indicators and analysis methods to make well-informed trading decisions.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

STD-Filtered Jurik Volty Adaptive TEMA [Loxx]The STD-Filtered Jurik Volty Adaptive TEMA is an advanced moving average overlay indicator that incorporates adaptive period inputs from Jurik Volty into a Triple Exponential Moving Average (TEMA). The resulting value is further refined using a standard deviation filter to minimize noise. This adaptation aims to develop a faster TEMA that leads the standard, non-adaptive TEMA. However, during periods of low volatility, the output may be noisy, so a standard deviation filter is employed to decrease choppiness, yielding a highly responsive TEMA without the noise typically caused by low market volatility.
█ What is Jurik Volty?
Jurik Volty calculates the price volatility and relative price volatility factor.
The Jurik smoothing includes 3 stages:
1st stage - Preliminary smoothing by adaptive EMA
2nd stage - One more preliminary smoothing by Kalman filter
3rd stage - Final smoothing by unique Jurik adaptive filter
Here's a breakdown of the code:
1. volty(float src, int len) => defines a function called volty that takes two arguments: src, which represents the source price data (like close price), and len, which represents the length or period for calculating the indicator.
2. int avgLen = 65 sets the length for the Simple Moving Average (SMA) to 65.
3. Various variables are initialized like volty, voltya, bsmax, bsmin, and vsum.
4. len1 is calculated as math.max(math.log(math.sqrt(0.5 * (len-1))) / math.log(2.0) + 2.0, 0); this expression involves some mathematical transformations based on the len input. The purpose is to create a dynamic factor that will be used later in the calculations.
5. pow1 is calculated as math.max(len1 - 2.0, 0.5); this variable is another dynamic factor used in further calculations.
6. del1 and del2 represent the differences between the current src value and the previous values of bsmax and bsmin, respectively.
7. volty is assigned a value based on a conditional expression, which checks whether the absolute value of del1 is greater than the absolute value of del2. This step is essential for determining the direction and magnitude of the price change.
8. vsum is updated based on the previous value and the difference between the current and previous volty values.
9. The Simple Moving Average (SMA) of vsum is calculated with the length avgLen and assigned to avg.
10. Variables dVolty, pow2, len2, and Kv are calculated using various mathematical transformations based on previously calculated variables. These variables are used to adjust the Jurik Volty indicator based on the observed volatility.
11. The bsmax and bsmin variables are updated based on the calculated Kv value and the direction of the price change.
12. inally, the temp variable is calculated as the ratio of avolty to vsum. This value represents the Jurik Volty indicator's output and can be used to analyze the market trends and potential reversals.
Jurik Volty can be used to identify periods of high or low volatility and to spot potential trade setups based on price behavior near the volatility bands.
█ What is the Triple Exponential Moving Average?
The Triple Exponential Moving Average (TEMA) is a technical indicator used by traders and investors to identify trends and price reversals in financial markets. It is a more advanced and responsive version of the Exponential Moving Average (EMA). TEMA was developed by Patrick Mulloy and introduced in the January 1994 issue of Technical Analysis of Stocks & Commodities magazine. The aim of TEMA is to minimize the lag associated with single and double exponential moving averages while also filtering out market noise, thus providing a smoother, more accurate representation of the market trend.
To understand TEMA, let's first briefly review the EMA.
Exponential Moving Average (EMA):
EMA is a weighted moving average that gives more importance to recent price data. The formula for EMA is:
EMA_t = (Price_t * α) + (EMA_(t-1) * (1 - α))
Where:
EMA_t: EMA at time t
Price_t: Price at time t
α: Smoothing factor (α = 2 / (N + 1))
N: Length of the moving average period
EMA_(t-1): EMA at time t-1
Triple Exponential Moving Average (TEMA):
Triple Exponential Moving Average (TEMA):
TEMA combines three exponential moving averages to provide a more accurate and responsive trend indicator. The formula for TEMA is:
TEMA = 3 * EMA_1 - 3 * EMA_2 + EMA_3
Where:
EMA_1: The first EMA of the price data
EMA_2: The EMA of EMA_1
EMA_3: The EMA of EMA_2
Here are the steps to calculate TEMA:
1. Choose the length of the moving average period (N).
2. Calculate the smoothing factor α (α = 2 / (N + 1)).
3. Calculate the first EMA (EMA_1) using the price data and the smoothing factor α.
4. Calculate the second EMA (EMA_2) using the values of EMA_1 and the same smoothing factor α.
5. Calculate the third EMA (EMA_3) using the values of EMA_2 and the same smoothing factor α.
5. Finally, compute the TEMA using the formula: TEMA = 3 * EMA_1 - 3 * EMA_2 + EMA_3
The Triple Exponential Moving Average, with its combination of three EMAs, helps to reduce the lag and filter out market noise more effectively than a single or double EMA. It is particularly useful for short-term traders who require a responsive indicator to capture rapid price changes. Keep in mind, however, that TEMA is still a lagging indicator, and as with any technical analysis tool, it should be used in conjunction with other indicators and analysis methods to make well-informed trading decisions.
Extras
Signals
Alerts
Bar coloring
Loxx's Expanded Source Types (see below):
GKD-C Stepped Moving Average of CCI [Loxx]Giga Kaleidoscope GKD-C Stepped Moving Average of CCI is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Stepped Moving Average of CCI as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
█ GKD-C Stepped Moving Average of CCI
What is Stepped Moving Average?
The Step MA function is a custom implementation of a step-moving average that uses the high and low prices of a security, along with the current price, to calculate the maximum and minimum step-moving average values. It then determines the current trend based on the relationship between the current price and the maximum and minimum values, and calculates the step-moving average for that trend. The calculated step-moving average is returned as the output of the function.
What is CCI?
CCI, or Commodity Channel Index, is a momentum-based technical analysis indicator developed by Donald Lambert in 1980. Initially created for the commodity markets, CCI has since been widely adopted for use in various financial markets, including stocks, forex, and indices.
The CCI measures the difference between the current price and its historical average relative to the average price fluctuations over a specific period. It helps traders identify potential overbought and oversold conditions and possible trend reversals.
The CCI is calculated as follows:
Calculate the Typical Price (TP) for each period: TP = (High + Low + Close) / 3
Calculate the Simple Moving Average (SMA) of the Typical Price over the chosen period (usually 14 or 20 periods).
Calculate the Mean Deviation (MD) by finding the average of the absolute difference between the Typical Price and its SMA for each period.
Calculate the CCI: CCI = (Typical Price - SMA) / (0.015 * Mean Deviation)
The constant 0.015 is a scaling factor that brings the CCI values within a standardized range, typically -100 to +100. Some traders might use different scaling factors depending on their preferences.
When using the CCI, traders consider the following:
Values above +100 typically indicate overbought conditions, suggesting a potential price decline.
Values below -100 typically indicate oversold conditions, suggesting a potential price increase.
CCI crossing above or below the zero line can signal a change in the direction of the market trend.
It is important to note that the CCI is a versatile indicator and can be used in combination with other technical analysis tools to improve the accuracy of trading signals.
What is the Stepped Moving Average of CCI?
This indicator runs the CCI through Stepped Moving Average algorithm to derive a smoother CCI.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

GKD-C Variety RSI of Adaptive Lookback Averages [Loxx]Giga Kaleidoscope GKD-C Variety RSI of Adaptive Lookback Averages is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Variety RSI of Adaptive Lookback Averages as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
]█ Setting up the GKD
The GKD system involves chaining indicators together. These are the steps to set this up.
Use a GKD-C indicator alone on a chart
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
Use a GKD-V indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Use a GKD-B indicator alone on a chart
**nothing, it's already useable on the chart without any settings changes
Baseline (Baseline, Backtest)
1. Import the GKD-B Baseline into the GKD-BT Backtest: "Input into Volatility/Volume or Backtest (Baseline testing)"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline"
Volatility/Volume (Volatility/Volume, Backte st)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Solo"
2. Inside the GKD-V indicator, change the "Signal Type" setting to "Crossing" (neither traditional nor both can be backtested)
3. Import the GKD-V indicator into the GKD-BT Backtest: "Input into C1 or Backtest"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Volatility/Volume"
5. Inside the GKD-BT Backtest, a) change the setting "Backtest Type" to "Trading" if using a directional GKD-V indicator; or, b) change the setting "Backtest Type" to "Full" if using a directional or non-directional GKD-V indicator (non-directional GKD-V can only test Longs and Shorts separately)
6. If "Backtest Type" is set to "Full": Inside the GKD-BT Backtest, change the setting "Backtest Side" to "Long" or "Short
7. If "Backtest Type" is set to "Full": To allow the system to open multiple orders at one time so you test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
Solo Confirmation Simple (Confirmation, Backtest)
1. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Simple"
1. Import the GKD-C indicator into the GKD-BT Backtest: "Input into Backtest"
2. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Solo Confirmation Simple"
Solo Confirmation Complex without Exits (Baseline, Volatility/Volume, Confirmation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
6. Import the GKD-C into the GKD-BT Backtest: "Input into Exit"
Solo Confirmation Complex with Exits (Baseline, Volatility/Volume, Confirmation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C indicator, change the "Confirmation Type" setting to "Solo Confirmation Complex"
4. Import the GKD-V indicator into the GKD-C indicator: "Input into C1 or Backtest"
5. Import the GKD-C indicator into the GKD-E indicator: "Input into Exit"
6. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
7. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Full GKD without Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full wo/ Exits"
9. Import the GKD-E into the GKD-BT Backtest: "Input into Exit"
Full GKD with Exits (Baseline, Volatility/Volume, Confirmation 1, Confirmation 2, Continuation, Exit, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Chained"
2. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
3. Inside the GKD-C 1 indicator, change the "Confirmation Type" setting to "Confirmation 1"
4. Import the GKD-V indicator into the GKD-C 1 indicator: "Input into C1 or Backtest"
5. Inside the GKD-C 2 indicator, change the "Confirmation Type" setting to "Confirmation 2"
6. Import the GKD-C 1 indicator into the GKD-C 2 indicator: "Input into C2"
7. Inside the GKD-C Continuation indicator, change the "Confirmation Type" setting to "Continuation"
8. Import the GKD-C Continuation indicator into the GKD-E indicator: "Input into Exit"
9. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "GKD Full w/ Exits"
10. Import the GKD-E into the GKD-BT Backtest: "Input into Backtest"
Baseline + Volatility/Volume (Baseline, Volatility/Volume, Backtest)
1. Inside the GKD-V indicator, change the "Testing Type" setting to "Baseline + Volatility/Volume"
2. Inside the GKD-V indicator, make sure the "Signal Type" setting is set to "Traditional"
3. Import the GKD-B Baseline into the GKD-V indicator: "Input into Volatility/Volume or Backtest (Baseline testing)"
4. Inside the GKD-BT Backtest, change the setting "Backtest Special" to "Baseline + Volatility/Volume"
5. Import the GKD-V into the GKD-BT Backtest: "Input into C1 or Backtest"
6. Inside the GKD-BT Backtest, change the setting "Backtest Type" to "Full". For this backtest, you must test Longs and Shorts separately
7. To allow the system to open multiple orders at one time so you can test all Longs or Shorts, open the GKD-BT Backtest, click the tab "Properties" and then insert a value of something like 10 orders into the "Pyramiding" settings. This will allow 10 orders to be opened at one time which should be enough to catch all possible Longs or Shorts.
█ GKD-C Variety RSI of Adaptive Lookback Averages
This indicator contains 7 different types of RSI:
RSX
Regular
Slow
Rapid
Harris
Cuttler
Ehlers Smoothed
What is RSI?
RSI stands for Relative Strength Index . It is a technical indicator used to measure the strength or weakness of a financial instrument's price action.
The RSI is calculated based on the price movement of an asset over a specified period of time, typically 14 days, and is expressed on a scale of 0 to 100. The RSI is considered overbought when it is above 70 and oversold when it is below 30.
Traders and investors use the RSI to identify potential buy and sell signals. When the RSI indicates that an asset is oversold, it may be considered a buying opportunity, while an overbought RSI may signal that it is time to sell or take profits.
It's important to note that the RSI should not be used in isolation and should be used in conjunction with other technical and fundamental analysis tools to make informed trading decisions.
What is RSX?
Jurik RSX is a technical analysis indicator that is a variation of the Relative Strength Index Smoothed ( RSX ) indicator. It was developed by Mark Jurik and is designed to help traders identify trends and momentum in the market.
The Jurik RSX uses a combination of the RSX indicator and an adaptive moving average (AMA) to smooth out the price data and reduce the number of false signals. The adaptive moving average is designed to adjust the smoothing period based on the current market conditions, which makes the indicator more responsive to changes in price.
The Jurik RSX can be used to identify potential trend reversals and momentum shifts in the market. It oscillates between 0 and 100, with values above 50 indicating a bullish trend and values below 50 indicating a bearish trend . Traders can use these levels to make trading decisions, such as buying when the indicator crosses above 50 and selling when it crosses below 50.
The Jurik RSX is a more advanced version of the RSX indicator, and while it can be useful in identifying potential trade opportunities, it should not be used in isolation. It is best used in conjunction with other technical and fundamental analysis tools to make informed trading decisions.
What is Slow RSI?
Slow RSI is a variation of the traditional Relative Strength Index ( RSI ) indicator. It is a more smoothed version of the RSI and is designed to filter out some of the noise and short-term price fluctuations that can occur with the standard RSI .
The Slow RSI uses a longer period of time than the traditional RSI , typically 21 periods instead of 14. This longer period helps to smooth out the price data and makes the indicator less reactive to short-term price fluctuations.
Like the traditional RSI , the Slow RSI is used to identify potential overbought and oversold conditions in the market. It oscillates between 0 and 100, with values above 70 indicating overbought conditions and values below 30 indicating oversold conditions. Traders often use these levels as potential buy and sell signals.
The Slow RSI is a more conservative version of the RSI and can be useful in identifying longer-term trends in the market. However, it can also be slower to respond to changes in price, which may result in missed trading opportunities. Traders may choose to use a combination of both the Slow RSI and the traditional RSI to make informed trading decisions.
What is Rapid RSI?
Same as regular RSI but with a faster calculation method
What is Harris RSI?
Harris RSI is a technical analysis indicator that is a variation of the Relative Strength Index ( RSI ). It was developed by Larry Harris and is designed to help traders identify potential trend changes and momentum shifts in the market.
The Harris RSI uses a different calculation formula compared to the traditional RSI . It takes into account both the opening and closing prices of a financial instrument, as well as the high and low prices. The Harris RSI is also normalized to a range of 0 to 100, with values above 50 indicating a bullish trend and values below 50 indicating a bearish trend .
Like the traditional RSI , the Harris RSI is used to identify potential overbought and oversold conditions in the market. It oscillates between 0 and 100, with values above 70 indicating overbought conditions and values below 30 indicating oversold conditions. Traders often use these levels as potential buy and sell signals.
The Harris RSI is a more advanced version of the RSI and can be useful in identifying longer-term trends in the market. However, it can also generate more false signals than the standard RSI . Traders may choose to use a combination of both the Harris RSI and the traditional RSI to make informed trading decisions.
What is Cuttler RSI?
Cuttler RSI is a technical analysis indicator that is a variation of the Relative Strength Index ( RSI ). It was developed by Curt Cuttler and is designed to help traders identify potential trend changes and momentum shifts in the market.
The Cuttler RSI uses a different calculation formula compared to the traditional RSI . It takes into account the difference between the closing price of a financial instrument and the average of the high and low prices over a specified period of time. This difference is then normalized to a range of 0 to 100, with values above 50 indicating a bullish trend and values below 50 indicating a bearish trend .
Like the traditional RSI , the Cuttler RSI is used to identify potential overbought and oversold conditions in the market. It oscillates between 0 and 100, with values above 70 indicating overbought conditions and values below 30 indicating oversold conditions. Traders often use these levels as potential buy and sell signals.
The Cuttler RSI is a more advanced version of the RSI and can be useful in identifying longer-term trends in the market. However, it can also generate more false signals than the standard RSI . Traders may choose to use a combination of both the Cuttler RSI and the traditional RSI to make informed trading decisions.
What is Ehlers Smoothed RSI?
Ehlers smoothed RSI is a technical analysis indicator that is a variation of the Relative Strength Index ( RSI ). It was developed by John Ehlers and is designed to help traders identify potential trend changes and momentum shifts in the market.
The Ehlers smoothed RSI uses a different calculation formula compared to the traditional RSI . It uses a smoothing algorithm that is designed to reduce the noise and random fluctuations that can occur with the standard RSI . The smoothing algorithm is based on a concept called "digital signal processing" and is intended to improve the accuracy of the indicator.
Like the traditional RSI , the Ehlers smoothed RSI is used to identify potential overbought and oversold conditions in the market. It oscillates between 0 and 100, with values above 70 indicating overbought conditions and values below 30 indicating oversold conditions. Traders often use these levels as potential buy and sell signals.
The Ehlers smoothed RSI can be useful in identifying longer-term trends and momentum shifts in the market. However, it can also generate more false signals than the standard RSI . Traders may choose to use a combination of both the Ehlers smoothed RSI and the traditional RSI to make informed trading decisions.
What is the Adaptive Lookback Period?
Adaptive Lookback Period defines a function called _albper that takes two parameters: swingCount and speed. The function is designed to calculate an adaptive lookback period for a financial chart, based on the count of detected swings and a speed factor. The adaptive lookback period can be used in various technical analysis techniques to adapt to market conditions.
Here's a step-by-step description of the code:
1. Initialize swing to 0.
2. If the current bar index is greater than 3 (meaning there are at least 4 bars of data), check for swings in price: a. If a downward swing is detected, set swing to -1.; b. If an upward swing is detected, set swing to 1.
3. Initialize swingBuffer to swing, k to 0, and n to 0.
4. Use a while loop to iterate through the bar indices up to the current bar index, while the swing count (n) is less than the specified swingCount:, a. If the swing buffer at the index k is not 0 (i.e., there's a swing at that index), increment n by 1.; b. Increment k by 1.
5. Calculate the adaptive lookback period (albPeriod) based on the swing count and speed factor, with a minimum value of 1.
6. Return the calculated albPeriod.
In summary, this function takes in the desired swing count and speed factor, and it calculates the adaptive lookback period based on the detected swings in the price data. It detects upward and downward swings in price and calculates the lookback period according to the input parameters swingCount and speed. This adaptive lookback period can be used in various technical analysis techniques to adapt to market conditions.
What is Variety RSI of Adaptive Lookback Averages?
This indicator calcualtes the adaptive lookback period and uses that value to smooth price before outputting one of seven different types of RSI. Because the period input is different each bar, this indicator uses specialized filters of common moving average caculations tht allow for variability in the period input.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C, GKD-V, or GKD-B Stacked 2+
Stacked 2+: GKD-C, GKD-V, or GKD-B Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.

GKD-C Price-Filtered Ocean Natural Moving Average (NMA) [Loxx]Giga Kaleidoscope GKD-C Price-Filtered Ocean Natural Moving Average (NMA) is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is the NNFX algorithmic trading strategy?
The NNFX (No-Nonsense Forex) trading system is a comprehensive approach to Forex trading that is designed to simplify the process and remove the confusion and complexity that often surrounds trading. The system was developed by a Forex trader who goes by the pseudonym "VP" and has gained a significant following in the Forex community.
The NNFX trading system is based on a set of rules and guidelines that help traders make objective and informed decisions. These rules cover all aspects of trading, including market analysis, trade entry, stop loss placement, and trade management.
Here are the main components of the NNFX trading system:
1. Trading Philosophy: The NNFX trading system is based on the idea that successful trading requires a comprehensive understanding of the market, objective analysis, and strict risk management. The system aims to remove subjective elements from trading and focuses on objective rules and guidelines.
2. Technical Analysis: The NNFX trading system relies heavily on technical analysis and uses a range of indicators to identify high-probability trading opportunities. The system uses a combination of trend-following and mean-reverting strategies to identify trades.
3. Market Structure: The NNFX trading system emphasizes the importance of understanding the market structure, including price action, support and resistance levels, and market cycles. The system uses a range of tools to identify the market structure, including trend lines, channels, and moving averages.
4. Trade Entry: The NNFX trading system has strict rules for trade entry. The system uses a combination of technical indicators to identify high-probability trades, and traders must meet specific criteria to enter a trade.
5. Stop Loss Placement: The NNFX trading system places a significant emphasis on risk management and requires traders to place a stop loss order on every trade. The system uses a combination of technical analysis and market structure to determine the appropriate stop loss level.
6. Trade Management: The NNFX trading system has specific rules for managing open trades. The system aims to minimize risk and maximize profit by using a combination of trailing stops, take profit levels, and position sizing.
Overall, the NNFX trading system is designed to be a straightforward and easy-to-follow approach to Forex trading that can be applied by traders of all skill levels.
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, the Average Directional Index (ADX), and the Chandelier Exit.
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Price-Filtered Ocean Natural Moving Average (NMA) as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
1-Candle Rule Volatility/Volume Entry
1. GKD-V Volatility/Volume signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close)
2. GKD-B Volatility/Volume agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-B Baseline agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
2. GKD-C Confirmation 1 agrees
3. GKD-C Confirmation 2 agrees
4. GKD-V Volatility/Volume Agrees
█ GKD-C Price-Filtered Ocean Natural Moving Average (NMA)
What is Ocean Natural Moving Average (NMA)?
The natural moving average is calculated by taking a weighted average of the data over a certain time period, with the weights assigned based on the distance of each data point from the center of the time period. Specifically, he suggests using a Gaussian weighting function to assign the weights, which gives greater weight to more recent data points and less weight to older data points.
The formula for the natural moving average, as presented by Sloman, is as follows:
NMA(t) = (w1D(t) + w2D(t-1) + ... + wn*D(t-n+1))/W
where NMA(t) is the natural moving average at time t, D(t) is the value of the data point at time t, w1, w2, ..., wn are the weights assigned to the data points, and W is the sum of the weights.
The weights w1, w2, ..., wn are calculated using a Gaussian function, which is given by:
w(i) = exp(-((i-1)^2)/(2*sigma^2))
where i is the number of time periods between the current data point and the center of the time period, and sigma is a smoothing parameter that controls the width of the Gaussian function.
Sloman suggests that the natural moving average can be useful for identifying long-term trends in oceanographic variables, such as sea surface temperature or sea level, that may be related to climate change or other large-scale processes. However, he also notes that the method has limitations, particularly in areas where the data is sparse or irregularly sampled.
It is important to note that the specific method used to calculate the ocean natural moving average may vary depending on the researcher and the type of data being analyzed. Additionally, the natural moving average is just one of many statistical tools used in oceanography to analyze long-term trends in oceanographic variables.
What is Price-Filtered Ocean Natural Moving Average (NMA) ?
This indicator smooths price then injects this output into the Ocean NMA calculation to produce an adaptive moving average based on Ocean Theory by Jim Sloman. This indicator includes 65+ moving average filter types to smooth price.
Requirements
Inputs
Confirmation 1: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Solo Confirmation Simple: GKD-B Baseline
Solo Confirmation Complex: GKD-V Volatility / Volume indicator
Solo Confirmation Super Complex: GKD-V Volatility / Volume indicator
Stacked 1: None
Stacked 2+: GKD-C Stacked 1
Outputs
Confirmation 1: GKD-C Confirmation 2 indicator
Confirmation 2: GKD-C Continuation indicator
Continuation: GKD-E Exit indicator
Solo Confirmation Simple: GKD-BT Backtest
Solo Confirmation Complex: GKD-BT Backtest or GKD-E Exit indicator
Solo Confirmation Super Complex: GKD-C Continuation indicator
Stacked 1: GKD-C Stacked 2+
Stacked 2+: GKD-C Stacked 2+ or GKD-BT Backtest
Additional features will be added in future releases.
