Primes_1These libraries (Primes_1 -> Primes_4) contain arrays of reduced Prime Numbers to minimize the amount of tokens, allowing more information to be exported.
Values, for example:
7001, 7013, 7019, 7027, 7039, 7043, 7057, 7069, 7079, 7103, 7109, 7021
are reduced to:
7001, 13, 19, 27, 39, 43, 57, 69, 79, 7103, 9, 21
With the restoreValues() function found in the Primes_4 library, the reduced values can be restored back to its original state.
7001, 13, 19, 27, 39, 43, 57, 69, 79, 7103, 9, 21
is restored back to:
7001, 7013, 7019, 7027, 7039, 7043, 7057, 7069, 7079, 7103, 7109, 7021
The libraries contain all Prime Numbers from 2 to 1.340.011
------------------------------------------------------------
Library "Primes_1"
Prime Numbers 2 - 339.991
primes_a()
Prime numbers 2 - 81.689
primes_b()
Prime numbers 81.701 - 175.897
primes_c()
Prime numbers 175.909 - 273.997
primes_d()
Prime numbers 274.007 - 339.991
MATH

SITFX_FuturesSpec_v17SITFX_FuturesSpec_v17 – Universal Futures Contract Library
Full-scale futures contract specification library for Pine Script v6. Covers CME, CBOT, NYMEX, COMEX, CFE, Eurex, ICE, and more – including minis, micros, metals, energies, FX, and bonds.
Key Features:
✅ Instrument‑agnostic: ES/MES, NQ/MNQ, YM/MYM, RTY/M2K, metals, energies, FX, bonds
✅ Full contract data: Tick size, tick value, point value, margins
✅ Continuation‑safe: Single‑line logic, no arrays or continuation errors
✅ Foundation for SITFX tools: Gann, Fibs, structure, and risk modules
Usage example:
import SITFX_FuturesSpec_v17/1 as fs
spec = fs.get(syminfo.root)
label.new(bar_index, high, str.format("{0}: Tick={1}, Value=${2}", spec.name, spec.tickSize, spec.tickValue))
FunctionADFLibrary "FunctionADF"
Augmented Dickey-Fuller test (ADF), The ADF test is a statistical method used to assess whether a time series is stationary – meaning its statistical properties (like mean and variance) do not change over time. A time series with a unit root is considered non-stationary and often exhibits non-mean-reverting behavior, which is a key concept in technical analysis.
Reference:
-
- rtmath.net
- en.wikipedia.org
adftest(data, n_lag, conf)
: Augmented Dickey-Fuller test for stationarity.
Parameters:
data (array) : Data series.
n_lag (int) : Maximum lag.
conf (string) : Confidence Probability level used to test for critical value, (`90%`, `95%`, `99%`).
Returns: `adf` The test statistic. \
`crit` Critical value for the test statistic at the 10 % levels. \
`nobs` Number of observations used for the ADF regression and calculation of the critical values.


DoublePatternsDetects Double Top and Double Bottom patterns from pivot points using structural symmetry, valley/peak depth, and extreme validation. Returns a detailed result object including similarity score, target price, and breakout quality.
WedgePatternsDetects Rising and Falling Wedge chart patterns using pivot points, trendline convergence, and volume confirmation. Includes adaptive wedge length analysis and a quality score for each match. Returns full wedge geometry and classification via WedgeResult.
HeadShouldersPatternsDetects Head & Shoulders and Inverse Head & Shoulders chart patterns from pivot point arrays. Includes neckline validation, shoulder symmetry checks, and head extremeness filtering. Returns a detailed result object with structure points, bar indices, and projected price target.
XABCD_HarmonicsLibrary for detecting harmonic patterns using ZigZag pivots or custom swing points. Supports Butterfly, Gartley, Bat, and Crab patterns with automatic Fibonacci ratio validation and optional D-point projection using extremes. Returns detailed PatternResult including structure points and target projection. Ideal for technical analysis, algorithmic detection, or overlay visualizations.

FastMetrixLibrary "FastMetrix"
This is a library I've been tweaking and working with for a while and I find it useful to get valuable technical analysis metrics faster (why its called FastMetrix). A lot of is personal to my trading style, so sorry if it does not have everything you want. The way I get my variables from library to script is by copying the return function into my new script.
TODO: Volatility and short term price analysis functions
slope(source, smoothing)
Parameters:
source (float)
smoothing (int)
integral(topfunction, bottomfunction, start, end)
Parameters:
topfunction (float)
bottomfunction (float)
start (int)
end (int)
deviation(x, y)
Parameters:
x (float)
y (float)
getema(len)
TODO: return important exponential long term moving averages and derivatives/variables
Parameters:
len (simple int)
getsma(len)
TODO: return requested sma
Parameters:
len (int)
kc(mult, len)
TODO: Return Keltner Channels variables and calculations
Parameters:
mult (simple float)
len (simple int)
bollinger(len, mult)
TODO: returns bollinger bands with optimal settings
Parameters:
len (int)
mult (simple float)
volatility(atrlen, smoothing)
TODO: Returns volatility indicators based on atr
Parameters:
atrlen (simple int)
smoothing (int)
premarketfib()
countinday(xcondition)
Parameters:
xcondition (bool)
countinsession(condition, n)
Parameters:
condition (bool)
n (int)
MathConstantsSolarSystemLibrary "MathConstantsSolarSystem"
Properties and data for the celestial objects in the Solar System.
LMAsLibrary "LMAs"
Credits
Thank you to @QuantraSystems for dynamic calculations.
Introduction
This lightweight library offers dynamic implementations of popular moving averages that adapt their length automatically as new bars are added to the chart.
Each function is built on a dynamic length formula:
len = math.min(maxLength, bar_index + 1)
This approach ensures that calculations begin as early as the first bar, allowing for smoother initialization and more consistent behavior across all timeframes. It’s especially useful in custom scripts that run from bar 0 or when historical data is limited.
Usage
You can use this library as a drop-in replacement for standard moving averages. It provides more flexibility and stability in live or backtesting environments where fixed-length indicators may delay or fail to initialize properly.
Why Use This?
• Works from the very first bar
• Avoids na values during early bars
• Great for real-time indicators, strategies, and bar-replay
• Clean and efficient code with dynamic behavior
How to Use
Import the library into your script and call any of the included functions just like you would with their native counterparts.
Summary
A lightweight Pine Script™ library offering dynamic moving averages that work seamlessly from the very first bar. Ideal for strategies and indicators requiring robust initialization and adaptive behavior.
SMA(sourceData, maxLength)
Dynamic SMA
Parameters:
sourceData (float)
maxLength (int)
EMA(src, length)
Dynamic EMA
Parameters:
src (float)
length (int)
DEMA(src, length)
Dynamic DEMA
Parameters:
src (float)
length (int)
TEMA(src, length)
Dynamic TEMA
Parameters:
src (float)
length (int)
WMA(src, length)
Dynamic WMA
Parameters:
src (float)
length (int)
HMA(src, length)
Dynamic HMA
Parameters:
src (float)
length (int)
VWMA(src, volsrc, length)
Dynamic VWMA
Parameters:
src (float)
volsrc (float)
length (int)
SMMA(src, length)
Dynamic SMMA
Parameters:
src (float)
length (int)
LSMA(src, length, offset)
Dynamic LSMA
Parameters:
src (float)
length (int)
offset (int)
RMA(src, length)
Dynamic RMA
Parameters:
src (float)
length (int)
ALMA(src, length, offset_sigma, sigma)
Dynamic ALMA
Parameters:
src (float)
length (int)
offset_sigma (float)
sigma (float)
ZLSMA(src, length)
Dynamic ZLSMA
Parameters:
src (float)
length (int)
FRAMA(src, length)
Parameters:
src (float)
length (int)
KAMA(src, length)
Dynamic KAMA
Parameters:
src (float)
length (int)
JMA(src, length, phase)
Dynamic JMA
Parameters:
src (float)
length (int)
phase (float)
T3(src, length, volumeFactor)
Dynamic T3
Parameters:
src (float)
length (int)
volumeFactor (float)

FvgCalculations█ OVERVIEW
This library provides the core calculation engine for identifying Fair Value Gaps (FVGs) across different timeframes and for processing their interaction with price. It includes functions to detect FVGs on both the current chart and higher timeframes, as well as to check for their full or partial mitigation.
█ CONCEPTS
The library's primary functions revolve around the concept of Fair Value Gaps and their lifecycle.
Fair Value Gap (FVG) Identification
An FVG, or imbalance, represents a price range where buying or selling pressure was significant enough to cause a rapid price movement, leaving an "inefficiency" in the market. This library identifies FVGs based on three-bar patterns:
Bullish FVG: Forms when the low of the current bar (bar 3) is higher than the high of the bar two periods prior (bar 1). The FVG is the space between the high of bar 1 and the low of bar 3.
Bearish FVG: Forms when the high of the current bar (bar 3) is lower than the low of the bar two periods prior (bar 1). The FVG is the space between the low of bar 1 and the high of bar 3.
The library provides distinct functions for detecting FVGs on the current (Low Timeframe - LTF) and specified higher timeframes (Medium Timeframe - MTF / High Timeframe - HTF).
FVG Mitigation
Mitigation refers to price revisiting an FVG.
Full Mitigation: An FVG is considered fully mitigated when price completely closes the gap. For a bullish FVG, this occurs if the current low price moves below or touches the FVG's bottom. For a bearish FVG, it occurs if the current high price moves above or touches the FVG's top.
Partial Mitigation (Entry/Fill): An FVG is partially mitigated when price enters the FVG's range but does not fully close it. The library tracks the extent of this fill. For a bullish FVG, if the current low price enters the FVG from above, that low becomes the new effective top of the remaining FVG. For a bearish FVG, if the current high price enters the FVG from below, that high becomes the new effective bottom of the remaining FVG.
FVG Interaction
This refers to any instance where the current bar's price range (high to low) touches or crosses into the currently unfilled portion of an active (visible and not fully mitigated) FVG.
Multi-Timeframe Data Acquisition
To detect FVGs on higher timeframes, specific historical bar data (high, low, and time of bars at indices and relative to the higher timeframe's last completed bar) is required. The requestMultiTFBarData function is designed to fetch this data efficiently.
█ CALCULATIONS AND USE
The functions in this library are typically used in a sequence to manage FVGs:
1. Data Retrieval (for MTF/HTF FVGs):
Call requestMultiTFBarData() with the desired higher timeframe string (e.g., "60", "D").
This returns a tuple of htfHigh1, htfLow1, htfTime1, htfHigh3, htfLow3, htfTime3.
2. FVG Detection:
For LTF FVGs: Call detectFvg() on each confirmed bar. It uses high , low, low , and high along with barstate.isconfirmed.
For MTF/HTF FVGs: Call detectMultiTFFvg() using the data obtained from requestMultiTFBarData().
Both detection functions return an fvgObject (defined in FvgTypes) if an FVG is found, otherwise na. They also can classify FVGs as "Large Volume" (LV) if classifyLV is true and the FVG size (top - bottom) relative to the tfAtr (Average True Range of the respective timeframe) meets the lvAtrMultiplier.
3. FVG State Updates (on each new bar for existing FVGs):
First, check for overall price interaction using fvgInteractionCheck(). This function determines if the current bar's high/low has touched or entered the FVG's currentTop or currentBottom.
If interaction occurs and the FVG is not already mitigated:
Call checkMitigation() to determine if the FVG has been fully mitigated by the current bar's currentHigh and currentLow. If true, the FVG's isMitigated status is updated.
If not fully mitigated, call checkPartialMitigation() to see if the price has further entered the FVG. This function returns the newLevel to which the FVG has been filled (e.g., currentLow for a bullish FVG, currentHigh for bearish). This newLevel is then used to update the FVG's currentTop or currentBottom.
The calling script (e.g., fvgMain.c) is responsible for storing and managing the array of fvgObject instances and passing them to these update functions.
█ NOTES
Bar State for LTF Detection: The detectFvg() function relies on barstate.isconfirmed to ensure FVG detection is based on closed bars, preventing FVGs from being detected prematurely on the currently forming bar.
Higher Timeframe Data (lookahead): The requestMultiTFBarData() function uses lookahead = barmerge.lookahead_on. This means it can access historical data from the higher timeframe that corresponds to the current bar on the chart, even if the higher timeframe bar has not officially closed. This is standard for multi-timeframe analysis aiming to plot historical HTF data accurately on a lower timeframe chart.
Parameter Typing: Functions like detectMultiTFFvg and detectFvg infer the type for boolean (classifyLV) and numeric (lvAtrMultiplier) parameters passed from the main script, while explicitly typed series parameters (like htfHigh1, currentAtr) expect series data.
fvgObject Dependency: The FVG detection functions return fvgObject instances, and fvgInteractionCheck takes an fvgObject as a parameter. This UDT is defined in the FvgTypes library, making it a dependency for using FvgCalculations.
ATR for LV Classification: The tfAtr (for MTF/HTF) and currentAtr (for LTF) parameters are expected to be the Average True Range values for the respective timeframes. These are used, if classifyLV is enabled, to determine if an FVG's size qualifies it as a "Large Volume" FVG based on the lvAtrMultiplier.
MTF/HTF FVG Appearance Timing: When displaying FVGs from a higher timeframe (MTF/HTF) on a lower timeframe (LTF) chart, users might observe that the most recent MTF/HTF FVG appears one LTF bar later compared to its appearance on a native MTF/HTF chart. This is an expected behavior due to the detection mechanism in `detectMultiTFFvg`. This function uses historical bar data from the MTF/HTF (specifically, data equivalent to `HTF_bar ` and `HTF_bar `) to identify an FVG. Therefore, all three bars forming the FVG on the MTF/HTF must be fully closed and have shifted into these historical index positions relative to the `request.security` call from the LTF chart before the FVG can be detected and displayed on the LTF. This ensures that the MTF/HTF FVG is identified based on confirmed, closed bars from the higher timeframe.
█ EXPORTED FUNCTIONS
requestMultiTFBarData(timeframe)
Requests historical bar data for specific previous bars from a specified higher timeframe.
It fetches H , L , T (for the bar before last) and H , L , T (for the bar three periods prior)
from the requested timeframe.
This is typically used to identify FVG patterns on MTF/HTF.
Parameters:
timeframe (simple string) : The higher timeframe to request data from (e.g., "60" for 1-hour, "D" for Daily).
Returns: A tuple containing: .
- htfHigh1 (series float): High of the bar at index 1 (one bar before the last completed bar on timeframe).
- htfLow1 (series float): Low of the bar at index 1.
- htfTime1 (series int) : Time of the bar at index 1.
- htfHigh3 (series float): High of the bar at index 3 (three bars before the last completed bar on timeframe).
- htfLow3 (series float): Low of the bar at index 3.
- htfTime3 (series int) : Time of the bar at index 3.
detectMultiTFFvg(htfHigh1, htfLow1, htfTime1, htfHigh3, htfLow3, htfTime3, tfAtr, classifyLV, lvAtrMultiplier, tfType)
Detects a Fair Value Gap (FVG) on a higher timeframe (MTF/HTF) using pre-fetched bar data.
Parameters:
htfHigh1 (float) : High of the first relevant bar (typically high ) from the higher timeframe.
htfLow1 (float) : Low of the first relevant bar (typically low ) from the higher timeframe.
htfTime1 (int) : Time of the first relevant bar (typically time ) from the higher timeframe.
htfHigh3 (float) : High of the third relevant bar (typically high ) from the higher timeframe.
htfLow3 (float) : Low of the third relevant bar (typically low ) from the higher timeframe.
htfTime3 (int) : Time of the third relevant bar (typically time ) from the higher timeframe.
tfAtr (float) : ATR value for the higher timeframe, used for Large Volume (LV) FVG classification.
classifyLV (bool) : If true, FVGs will be assessed to see if they qualify as Large Volume.
lvAtrMultiplier (float) : The ATR multiplier used to define if an FVG is Large Volume.
tfType (series tfType enum from no1x/FvgTypes/1) : The timeframe type (e.g., types.tfType.MTF, types.tfType.HTF) of the FVG being detected.
Returns: An fvgObject instance if an FVG is detected, otherwise na.
detectFvg(classifyLV, lvAtrMultiplier, currentAtr)
Detects a Fair Value Gap (FVG) on the current (LTF - Low Timeframe) chart.
Parameters:
classifyLV (bool) : If true, FVGs will be assessed to see if they qualify as Large Volume.
lvAtrMultiplier (float) : The ATR multiplier used to define if an FVG is Large Volume.
currentAtr (float) : ATR value for the current timeframe, used for LV FVG classification.
Returns: An fvgObject instance if an FVG is detected, otherwise na.
checkMitigation(isBullish, fvgTop, fvgBottom, currentHigh, currentLow)
Checks if an FVG has been fully mitigated by the current bar's price action.
Parameters:
isBullish (bool) : True if the FVG being checked is bullish, false if bearish.
fvgTop (float) : The top price level of the FVG.
fvgBottom (float) : The bottom price level of the FVG.
currentHigh (float) : The high price of the current bar.
currentLow (float) : The low price of the current bar.
Returns: True if the FVG is considered fully mitigated, false otherwise.
checkPartialMitigation(isBullish, currentBoxTop, currentBoxBottom, currentHigh, currentLow)
Checks for partial mitigation of an FVG by the current bar's price action.
It determines if the price has entered the FVG and returns the new fill level.
Parameters:
isBullish (bool) : True if the FVG being checked is bullish, false if bearish.
currentBoxTop (float) : The current top of the FVG box (this might have been adjusted by previous partial fills).
currentBoxBottom (float) : The current bottom of the FVG box (similarly, might be adjusted).
currentHigh (float) : The high price of the current bar.
currentLow (float) : The low price of the current bar.
Returns: The new price level to which the FVG has been filled (e.g., currentLow for a bullish FVG).
Returns na if no new partial fill occurred on this bar.
fvgInteractionCheck(fvg, highVal, lowVal)
Checks if the current bar's price interacts with the given FVG.
Interaction means the price touches or crosses into the FVG's
current (possibly partially filled) range.
Parameters:
fvg (fvgObject type from no1x/FvgTypes/1) : The FVG object to check.
Its isMitigated, isVisible, isBullish, currentTop, and currentBottom fields are used.
highVal (float) : The high price of the current bar.
lowVal (float) : The low price of the current bar.
Returns: True if price interacts with the FVG, false otherwise.

WeightedVolumeUtilsLibrary "WeightedVolumeUtils"
fun(x)
Returns the input value (placeholder function).
Parameters:
x (float) : A float value.
Returns: The same float value passed as input.
weightedBSEVolume()
Calculates the weighted volume for BSE index based on top constituent stocks.
Returns: Weighted volume value based on fixed weights for BSE SENSEX stocks.
getAdjustedVolume()
Returns the adjusted volume for SENSEX or regular volume otherwise.
Returns: Weighted BSE volume if current symbol is SENSEX, else raw volume.
MathSpecialFunctionsConvolve1DLibrary "MathSpecialFunctionsConvolve1D"
Convolution is one of the most important mathematical operations used in signal processing. This simple mathematical operation pops up in many scientific and industrial applications, from its use in a billion-layer large CNN to simple image denoising.
___
Reference:
www.algorithm-archive.org
numpy.org
lloydrochester.com
www.geeksforgeeks.org
f(signal, filter)
Convolve
Parameters:
signal (array) : List with signal data.
filter (array) : List with weights to apply to the signal data.
Returns: Discrete, linear convolution of `signal` and `filter`.

ErrorFunctionsLibrary "ErrorFunctions"
A collection of functions used to approximate the area beneath a Gaussian curve.
Because an ERF (Error Function) is an integral, there is no closed-form solution to calculating the area beneath the curve. Meaning all ERFs are approximations; precisely wrong, but mostly accurate. How close you need to get to the actual area depends entirely on your use case, with more precision being less efficient.
The internal precision of floats in Pine Script is 1e-16 (16 decimals, aka. double precision). This library adapts well known algorithms designed to efficiently reach double precision. Single precision alternates are also included. All of them were made free to use, modify, and distribute by their original authors.
HASTINGS
Adaptation of a single precision ERF by Cecil Hastings Jr, published through Princeton University in 1955. It was later documented by Abramowitz and Stegun as equation 7.1.26 in their 1972 Handbook of Mathematical Functions. Fast, efficient, and ideal when precision beyond a few decimals is unnecessary.
GILES
Adaptation of a single precision Inverse ERF by Michael Giles, published through the University of Oxford in 2012. It reverses the ERF, estimating an X coordinate from an area. It too is fast, efficient, and ideal when precision beyond a few decimals is unnecessary.
LIBC
Adaptation of the double precision ERF & ERFC in the standard C library (aka. libc). It is also the same ERF & ERFC that SciPy uses. While not quite as efficient as the Hastings approximation, it's still very fast and fully maximizes Pines precision.
BOOST
Adaptation of the double precision Inverse ERF & Inverse ERFC in the Boost Math C++ library. SciPy uses these as well. These reverse the ERF & ERFC, estimating an X coordinate from an area. It too isn't quite as efficient as the Giles approximation, but still fast and fully maximizes Pines precision.
While these algorithms are not exported directly, they are available through their exported counterparts.
- - -
ERROR FUNCTIONS
erf(x, precise)
An Error Function estimates the theoretical error of a measurement.
Parameters:
x (float) : (float) Upper limit of the integration.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between -1 and 1.
erfc(x, precise)
A Complementary Error Function estimates the difference between a theoretical error and infinity.
Parameters:
x (float) : (float) Lower limit of the integration.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 2.
erfinv(x, precise)
An Inverse Error Function reverses the erf() by estimating the original measurement from the theoretical error.
Parameters:
x (float) : (float) Theoretical error.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ± infinity.
erfcinv(x, precise)
An Inverse Complementary Error Function reverses the erfc() by estimating the original measurement from the difference between the theoretical error and infinity.
Parameters:
x (float) : (float) Difference between the theoretical error and infinity.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ± infinity.
- - -
DISTRIBUTION FUNCTIONS
pdf(x, m, s)
A Probability Density Function estimates the probability density . For clarity, density is not a probability .
Parameters:
x (float) : (float) X coordinate for which a density will be estimated.
m (float) : (float) Mean
s (float) : (float) Sigma
Returns: (float) Between 0 and ∞.
cdf(z, precise)
A Cumulative Distribution Function estimates the area under a Gaussian curve between negative infinity and the Z Score.
Parameters:
z (float) : (float) Z Score.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
cdfinv(a, precise)
An Inverse Cumulative Distribution Function reverses the cdf() by estimating the Z Score from an area.
Parameters:
a (float) : (float) Area between 0 and 1.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between -∞ and +∞
cdfab(z1, z2, precise)
A Cumulative Distribution Function from A to B estimates the area under a Gaussian curve between two Z Scores (A and B).
Parameters:
z1 (float) : (float) First Z Score.
z2 (float) : (float) Second Z Score.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
ttt(z, precise)
A Two-Tailed Test estimates the area under a Gaussian curve between symmetrical ± Z scores and ± infinity.
Parameters:
z (float) : (float) One of the symmetrical Z Scores.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
tttinv(a, precise)
An Inverse Two-Tailed Test reverses the ttt() by estimating the absolute Z Score from an area.
Parameters:
a (float) : (float) Area between 0 and 1.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ∞.
ott(z, precise)
A One-Tailed Test estimates the area under a Gaussian curve between an absolute Z Score and infinity.
Parameters:
z (float) : (float) Z Score.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and 1.
ottinv(a, precise)
An Inverse One-Tailed Test Reverses the ott() by estimating the Z Score from a an area.
Parameters:
a (float) : (float) Area between 0 and 1.
precise (bool) : Double precision (true) or single precision (false).
Returns: (float) Between 0 and ∞.

pymath█ OVERVIEW
This library ➕ enhances Pine Script's built-in types (`float`, `int`, `array`, `array`) with mathematical methods, mirroring 🪞 many functions from Python's `math` module. Import this library to overload or add to built-in capabilities, enabling calls like `myFloat.sin()` or `myIntArray.gcd()`.
█ CONCEPTS
This library wraps Pine's built-in `math.*` functions and implements others where necessary, expanding the mathematical toolkit available within Pine Script. It provides a more object-oriented approach to mathematical operations on core data types.
█ HOW TO USE
• Import the library: i mport kaigouthro/pymath/1
• Call methods directly on variables: myFloat.sin() , myIntArray.gcd()
• For raw integer literals, you MUST use parentheses: `(1234).factorial()`.
█ FEATURES
• **Infinity Handling:** Includes `isinf()` and `isfinite()` for robust checks. Uses `POS_INF_PROXY` to represent infinity.
• **Comprehensive Math Functions:** Implements a wide range of methods, including trigonometric, logarithmic, hyperbolic, and array operations.
• **Object-Oriented Approach:** Allows direct method calls on `int`, `float`, and arrays for cleaner code.
• **Improved Accuracy:** Some functions (e.g., `remainder()`) offer improved accuracy compared to default Pine behavior.
• **Helper Functions:** Internal helper functions optimize calculations and handle edge cases.
█ NOTES
This library improves upon Pine Script's built-in `math` functions by adding new ones and refining existing implementations. It handles edge cases such as infinity, NaN, and zero values, enhancing the reliability of your Pine scripts. For Speed, it wraps and uses built-ins, as thy are fastest.
█ EXAMPLES
//@version=6
indicator("My Indicator")
// Import the library
import kaigouthro/pymath/1
// Create some Vars
float myFloat = 3.14159
int myInt = 10
array myIntArray = array.from(1, 2, 3, 4, 5)
// Now you can...
plot( myFloat.sin() ) // Use sin() method on a float, using built in wrapper
plot( (myInt).factorial() ) // Factorial of an integer (note parentheses)
plot( myIntArray.gcd() ) // GCD of an integer array
method isinf(self)
isinf: Checks if this float is positive or negative infinity using a proxy value.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) value to check.
Returns: (bool) `true` if the absolute value of `self` is greater than or equal to the infinity proxy, `false` otherwise.
method isfinite(self)
isfinite: Checks if this float is finite (not NaN and not infinity).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The value to check.
Returns: (bool) `true` if `self` is not `na` and not infinity (as defined by `isinf()`), `false` otherwise.
method fmod(self, divisor)
fmod: Returns the C-library style floating-point remainder of `self / divisor` (result has the sign of `self`).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Dividend `x`.
divisor (float) : (float) Divisor `y`. Cannot be zero or `na`.
Returns: (float) The remainder `x - n*y` where n is `trunc(x/y)`, or `na` if divisor is 0, `na`, or inputs are infinite in a way that prevents calculation.
method factorial(self)
factorial: Calculates the factorial of this non-negative integer.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) The integer `n`. Must be non-negative.
Returns: (float) `n!` as a float, or `na` if `n` is negative or overflow occurs (based on `isinf`).
method isqrt(self)
isqrt: Calculates the integer square root of this non-negative integer (floor of the exact square root).
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) The non-negative integer `n`.
Returns: (int) The greatest integer `a` such that a² <= n, or `na` if `n` is negative.
method comb(self, k)
comb: Calculates the number of ways to choose `k` items from `self` items without repetition and without order (Binomial Coefficient).
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) Total number of items `n`. Must be non-negative.
k (int) : (int) Number of items to choose. Must be non-negative.
Returns: (float) The binomial coefficient nCk, or `na` if inputs are invalid (n<0 or k<0), `k > n`, or overflow occurs.
method perm(self, k)
perm: Calculates the number of ways to choose `k` items from `self` items without repetition and with order (Permutations).
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : (int) Total number of items `n`. Must be non-negative.
k (simple int) : (simple int = na) Number of items to choose. Must be non-negative. Defaults to `n` if `na`.
Returns: (float) The number of permutations nPk, or `na` if inputs are invalid (n<0 or k<0), `k > n`, or overflow occurs.
method log2(self)
log2: Returns the base-2 logarithm of this float. Input must be positive. Wraps `math.log(self) / math.log(2.0)`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be positive.
Returns: (float) The base-2 logarithm, or `na` if input <= 0.
method trunc(self)
trunc: Returns this float with the fractional part removed (truncates towards zero).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The integer part, or `na` if input is `na` or infinite.
method abs(self)
abs: Returns the absolute value of this float. Wraps `math.abs()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The absolute value, or `na` if input is `na`.
method acos(self)
acos: Returns the arccosine of this float, in radians. Wraps `math.acos()`. Input must be between -1 and 1.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be between -1 and 1.
Returns: (float) Angle in radians , or `na` if input is outside or `na`.
method asin(self)
asin: Returns the arcsine of this float, in radians. Wraps `math.asin()`. Input must be between -1 and 1.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be between -1 and 1.
Returns: (float) Angle in radians , or `na` if input is outside or `na`.
method atan(self)
atan: Returns the arctangent of this float, in radians. Wraps `math.atan()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) Angle in radians , or `na` if input is `na`.
method ceil(self)
ceil: Returns the ceiling of this float (smallest integer >= self). Wraps `math.ceil()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The ceiling value, or `na` if input is `na` or infinite.
method cos(self)
cos: Returns the cosine of this float (angle in radians). Wraps `math.cos()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The cosine, or `na` if input is `na`.
method degrees(self)
degrees: Converts this float from radians to degrees. Wraps `math.todegrees()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The angle in degrees, or `na` if input is `na`.
method exp(self)
exp: Returns e raised to the power of this float. Wraps `math.exp()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The exponent.
Returns: (float) `e**self`, or `na` if input is `na`.
method floor(self)
floor: Returns the floor of this float (largest integer <= self). Wraps `math.floor()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The floor value, or `na` if input is `na` or infinite.
method log(self)
log: Returns the natural logarithm (base e) of this float. Wraps `math.log()`. Input must be positive.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be positive.
Returns: (float) The natural logarithm, or `na` if input <= 0 or `na`.
method log10(self)
log10: Returns the base-10 logarithm of this float. Wraps `math.log10()`. Input must be positive.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be positive.
Returns: (float) The base-10 logarithm, or `na` if input <= 0 or `na`.
method pow(self, exponent)
pow: Returns this float raised to the power of `exponent`. Wraps `math.pow()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The base.
exponent (float) : (float) The exponent.
Returns: (float) `self**exponent`, or `na` if inputs are `na` or lead to undefined results.
method radians(self)
radians: Converts this float from degrees to radians. Wraps `math.toradians()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in degrees.
Returns: (float) The angle in radians, or `na` if input is `na`.
method round(self)
round: Returns the nearest integer to this float. Wraps `math.round()`. Ties are rounded away from zero.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) The rounded integer, or `na` if input is `na` or infinite.
method sign(self)
sign: Returns the sign of this float (-1, 0, or 1). Wraps `math.sign()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (int) -1 if negative, 0 if zero, 1 if positive, `na` if input is `na`.
method sin(self)
sin: Returns the sine of this float (angle in radians). Wraps `math.sin()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The sine, or `na` if input is `na`.
method sqrt(self)
sqrt: Returns the square root of this float. Wraps `math.sqrt()`. Input must be non-negative.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be non-negative.
Returns: (float) The square root, or `na` if input < 0 or `na`.
method tan(self)
tan: Returns the tangent of this float (angle in radians). Wraps `math.tan()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The angle in radians.
Returns: (float) The tangent, or `na` if input is `na`.
method acosh(self)
acosh: Returns the inverse hyperbolic cosine of this float. Input must be >= 1.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be >= 1.
Returns: (float) The inverse hyperbolic cosine, or `na` if input < 1 or `na`.
method asinh(self)
asinh: Returns the inverse hyperbolic sine of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The inverse hyperbolic sine, or `na` if input is `na`.
method atanh(self)
atanh: Returns the inverse hyperbolic tangent of this float. Input must be between -1 and 1 (exclusive).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number. Must be between -1 and 1 (exclusive).
Returns: (float) The inverse hyperbolic tangent, or `na` if input is outside (-1, 1) or `na`.
method cosh(self)
cosh: Returns the hyperbolic cosine of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The hyperbolic cosine, or `na` if input is `na`.
method sinh(self)
sinh: Returns the hyperbolic sine of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The hyperbolic sine, or `na` if input is `na`.
method tanh(self)
tanh: Returns the hyperbolic tangent of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The input number.
Returns: (float) The hyperbolic tangent, or `na` if input is `na`.
method atan2(self, dx)
atan2: Returns the angle in radians between the positive x-axis and the point (dx, self). Wraps `math.atan2()`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The y-coordinate `y`.
dx (float) : (float) The x-coordinate `x`.
Returns: (float) The angle in radians , result of `math.atan2(self, dx)`. Returns `na` if inputs are `na`. Note: `math.atan2(0, 0)` returns 0 in Pine.
Optimization: Use built-in math.atan2()
method cbrt(self)
cbrt: Returns the cube root of this float.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The value to find the cube root of.
Returns: (float) The real cube root. Handles negative inputs correctly, or `na` if input is `na`.
method exp2(self)
exp2: Returns 2 raised to the power of this float. Calculated as `2.0.pow(self)`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The exponent.
Returns: (float) `2**self`, or `na` if input is `na` or results in non-finite value.
method expm1(self)
expm1: Returns `e**self - 1`. Calculated as `self.exp() - 1.0`. May offer better precision for small `self` in some environments, but Pine provides no guarantee over `self.exp() - 1.0`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The exponent.
Returns: (float) `e**self - 1`, or `na` if input is `na` or `self.exp()` is `na`.
method log1p(self)
log1p: Returns the natural logarithm of (1 + self). Calculated as `(1.0 + self).log()`. Pine provides no specific precision guarantee for self near zero.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Value to add to 1. `1 + self` must be positive.
Returns: (float) Natural log of `1 + self`, or `na` if input is `na` or `1 + self <= 0`.
method modf(self)
modf: Returns the fractional and integer parts of this float as a tuple ` `. Both parts have the sign of `self`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The number `x` to split.
Returns: ( ) A tuple containing ` `, or ` ` if `x` is `na` or non-finite.
method remainder(self, divisor)
remainder: Returns the IEEE 754 style remainder of `self` with respect to `divisor`. Result `r` satisfies `abs(r) <= 0.5 * abs(divisor)`. Uses round-half-to-even.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Dividend `x`.
divisor (float) : (float) Divisor `y`. Cannot be zero or `na`.
Returns: (float) The IEEE 754 remainder, or `na` if divisor is 0, `na`, or inputs are non-finite in a way that prevents calculation.
method copysign(self, signSource)
copysign: Returns a float with the magnitude (absolute value) of `self` but the sign of `signSource`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Value providing the magnitude `x`.
signSource (float) : (float) Value providing the sign `y`.
Returns: (float) `abs(x)` with the sign of `y`, or `na` if either input is `na`.
method frexp(self)
frexp: Returns the mantissa (m) and exponent (e) of this float `x` as ` `, such that `x = m * 2^e` and `0.5 <= abs(m) < 1` (unless `x` is 0).
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) The number `x` to decompose.
Returns: ( ) A tuple ` `, or ` ` if `x` is 0, or ` ` if `x` is non-finite or `na`.
method isclose(self, other, rel_tol, abs_tol)
isclose: Checks if this float `a` and `other` float `b` are close within relative and absolute tolerances.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) First value `a`.
other (float) : (float) Second value `b`.
rel_tol (simple float) : (simple float = 1e-9) Relative tolerance. Must be non-negative and less than 1.0.
abs_tol (simple float) : (simple float = 0.0) Absolute tolerance. Must be non-negative.
Returns: (bool) `true` if `abs(a - b) <= max(rel_tol * max(abs(a), abs(b)), abs_tol)`. Handles `na`/`inf` appropriately. Returns `na` if tolerances are invalid.
method ldexp(self, exponent)
ldexp: Returns `self * (2**exponent)`. Inverse of `frexp`.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : (float) Mantissa part `x`.
exponent (int) : (int) Exponent part `i`.
Returns: (float) The result of `x * pow(2, i)`, or `na` if inputs are `na` or result is non-finite.
method gcd(self)
gcd: Calculates the Greatest Common Divisor (GCD) of all integers in this array.
Namespace types: array
Parameters:
self (array) : (array) An array of integers.
Returns: (int) The largest positive integer that divides all non-zero elements, 0 if all elements are 0 or array is empty. Returns `na` if any element is `na`.
method lcm(self)
lcm: Calculates the Least Common Multiple (LCM) of all integers in this array.
Namespace types: array
Parameters:
self (array) : (array) An array of integers.
Returns: (int) The smallest positive integer that is a multiple of all non-zero elements, 0 if any element is 0, 1 if array is empty. Returns `na` on potential overflow or if any element is `na`.
method dist(self, other)
dist: Returns the Euclidean distance between this point `p` and another point `q` (given as arrays of coordinates).
Namespace types: array
Parameters:
self (array) : (array) Coordinates of the first point `p`.
other (array) : (array) Coordinates of the second point `q`. Must have the same size as `p`.
Returns: (float) The Euclidean distance, or `na` if arrays have different sizes, are empty, or contain `na`/non-finite values.
method fsum(self)
fsum: Returns an accurate floating-point sum of values in this array. Uses built-in `array.sum()`. Note: Pine Script does not guarantee the same level of precision tracking as Python's `math.fsum`.
Namespace types: array
Parameters:
self (array) : (array) The array of floats to sum.
Returns: (float) The sum of the array elements. Returns 0.0 for an empty array. Returns `na` if any element is `na`.
method hypot(self)
hypot: Returns the Euclidean norm (distance from origin) for this point given by coordinates in the array. `sqrt(sum(x*x for x in coordinates))`.
Namespace types: array
Parameters:
self (array) : (array) Array of coordinates defining the point.
Returns: (float) The Euclidean norm, or 0.0 if the array is empty. Returns `na` if any element is `na` or non-finite.
method prod(self, start)
prod: Calculates the product of all elements in this array.
Namespace types: array
Parameters:
self (array) : (array) The array of values to multiply.
start (simple float) : (simple float = 1.0) The starting value for the product (returned if the array is empty).
Returns: (float) The product of array elements * start. Returns `na` if any element is `na`.
method sumprod(self, other)
sumprod: Returns the sum of products of values from this array `p` and another array `q` (dot product).
Namespace types: array
Parameters:
self (array) : (array) First array of values `p`.
other (array) : (array) Second array of values `q`. Must have the same size as `p`.
Returns: (float) The sum of `p * q ` for all i, or `na` if arrays have different sizes or contain `na`/non-finite values. Returns 0.0 for empty arrays.

SMCFunctionsLibrary "SMCFunctions"
findSwingPoints(high, low, swing_size)
Parameters:
high (float)
low (float)
swing_size (int)
detectBOS(close, high, low, prevHigh, prevLow, highActive, lowActive, bos_conf_type)
Parameters:
close (float)
high (float)
low (float)
prevHigh (float)
prevLow (float)
highActive (bool)
lowActive (bool)
bos_conf_type (string)
getBOSDetails(highBroken, lowBroken, prevHigh, prevLow, prevSwing, prevHighIndex, prevLowIndex, input_show_choch)
Parameters:
highBroken (bool)
lowBroken (bool)
prevHigh (float)
prevLow (float)
prevSwing (int)
prevHighIndex (int)
prevLowIndex (int)
input_show_choch (bool)
calculateRetracementLevels(start_price, end_price)
Parameters:
start_price (float)
end_price (float)

MLExtensions_CoreLibrary "MLExtensions_Core"
A set of extension methods for a novel implementation of a Approximate Nearest Neighbors (ANN) algorithm in Lorentzian space, focused on computation.
normalizeDeriv(src, quadraticMeanLength)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src (float) : The input series (i.e., the first-order derivative for price).
quadraticMeanLength (int) : The length of the quadratic mean (RMS).
Returns: nDeriv The normalized derivative of the input series.
normalize(src, min, max)
Rescales a source value with an unbounded range to a target range.
Parameters:
src (float) : The input series
min (float) : The minimum value of the unbounded range
max (float) : The maximum value of the unbounded range
Returns: The normalized series
rescale(src, oldMin, oldMax, newMin, newMax)
Rescales a source value with a bounded range to anther bounded range
Parameters:
src (float) : The input series
oldMin (float) : The minimum value of the range to rescale from
oldMax (float) : The maximum value of the range to rescale from
newMin (float) : The minimum value of the range to rescale to
newMax (float) : The maximum value of the range to rescale to
Returns: The rescaled series
getColorShades(color)
Creates an array of colors with varying shades of the input color
Parameters:
color (color) : The color to create shades of
Returns: An array of colors with varying shades of the input color
getPredictionColor(prediction, neighborsCount, shadesArr)
Determines the color shade based on prediction percentile
Parameters:
prediction (float) : Value of the prediction
neighborsCount (int) : The number of neighbors used in a nearest neighbors classification
shadesArr (array) : An array of colors with varying shades of the input color
Returns: shade Color shade based on prediction percentile
color_green(prediction)
Assigns varying shades of the color green based on the KNN classification
Parameters:
prediction (float) : Value (int|float) of the prediction
Returns: color
color_red(prediction)
Assigns varying shades of the color red based on the KNN classification
Parameters:
prediction (float) : Value of the prediction
Returns: color
tanh(src)
Returns the the hyperbolic tangent of the input series. The sigmoid-like hyperbolic tangent function is used to compress the input to a value between -1 and 1.
Parameters:
src (float) : The input series (i.e., the normalized derivative).
Returns: tanh The hyperbolic tangent of the input series.
dualPoleFilter(src, lookback)
Returns the smoothed hyperbolic tangent of the input series.
Parameters:
src (float) : The input series (i.e., the hyperbolic tangent).
lookback (int) : The lookback window for the smoothing.
Returns: filter The smoothed hyperbolic tangent of the input series.
tanhTransform(src, smoothingFrequency, quadraticMeanLength)
Returns the tanh transform of the input series.
Parameters:
src (float) : The input series (i.e., the result of the tanh calculation).
smoothingFrequency (int)
quadraticMeanLength (int)
Returns: signal The smoothed hyperbolic tangent transform of the input series.
n_rsi(src, n1, n2)
Returns the normalized RSI ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the RSI calculation).
n1 (simple int) : The length of the RSI.
n2 (simple int) : The smoothing length of the RSI.
Returns: signal The normalized RSI.
n_cci(src, n1, n2)
Returns the normalized CCI ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the CCI calculation).
n1 (simple int) : The length of the CCI.
n2 (simple int) : The smoothing length of the CCI.
Returns: signal The normalized CCI.
n_wt(src, n1, n2)
Returns the normalized WaveTrend Classic series ideal for use in ML algorithms.
Parameters:
src (float) : The input series (i.e., the result of the WaveTrend Classic calculation).
n1 (simple int)
n2 (simple int)
Returns: signal The normalized WaveTrend Classic series.
n_adx(highSrc, lowSrc, closeSrc, n1)
Returns the normalized ADX ideal for use in ML algorithms.
Parameters:
highSrc (float) : The input series for the high price.
lowSrc (float) : The input series for the low price.
closeSrc (float) : The input series for the close price.
n1 (simple int) : The length of the ADX.
regime_filter(src, threshold, useRegimeFilter)
Parameters:
src (float)
threshold (float)
useRegimeFilter (bool)
filter_adx(src, length, adxThreshold, useAdxFilter)
filter_adx
Parameters:
src (float) : The source series.
length (simple int) : The length of the ADX.
adxThreshold (int) : The ADX threshold.
useAdxFilter (bool) : Whether to use the ADX filter.
Returns: The ADX.
filter_volatility(minLength, maxLength, sensitivityMultiplier, useVolatilityFilter)
filter_volatility
Parameters:
minLength (simple int) : The minimum length of the ATR.
maxLength (simple int) : The maximum length of the ATR.
sensitivityMultiplier (float) : Multiplier for the historical ATR to control sensitivity.
useVolatilityFilter (bool) : Whether to use the volatility filter.
Returns: Boolean indicating whether or not to let the signal pass through the filter.

TUF_LOGICTUF_LOGIC: Three-Value Logic for Pine Script v6
The TUF_LOGIC library implements a robust three-valued logic system (trilean logic) for Pine Script v6, providing a formal framework for reasoning about uncertain or incomplete information in financial markets. By extending beyond binary True/False states to include an explicit "Uncertain" state, this library enables more nuanced algorithmic decision-making, particularly valuable in environments characterized by imperfect information.
Core Architecture
TUF_LOGIC offers two complementary interfaces for working with trilean values:
Enum-Based API (Recommended): Leverages Pine Script v6's enum capabilities with Trilean.True , Trilean.Uncertain , and Trilean.False for improved type safety and performance.
Integer-Based API (Legacy Support): Maintains compatibility with existing code using integer values 1 (True), 0 (Uncertain), and -1 (False).
Fundamental Operations
The library provides type conversion methods for seamless interaction between integer representation and enum types ( to_trilean() , to_int() ), along with validation functions to maintain trilean invariants.
Logical Operators
TUF_LOGIC extends traditional boolean operators to the trilean domain with NOT , AND , OR , XOR , and EQUALITY functions that properly handle the Uncertain state according to the principles of three-valued logic.
The library implements three different implication operators providing flexibility for different logical requirements: IMP_K (Kleene's approach), IMP_L (Łukasiewicz's approach), and IMP_RM3 (Relevant implication under RM3 logic).
Inspired by Tarski-Łukasiewicz's modal logic formulations, TUF_LOGIC includes modal operators: MA (Modal Assertion) evaluates whether a state is possibly true; LA (Logical Assertion) determines if a state is necessarily true; and IA (Indeterminacy Assertion) identifies explicitly uncertain states.
The UNANIMOUS operator evaluates trilean values for complete agreement, returning the consensus value if one exists or Uncertain otherwise. This function is available for both pairs of values and arrays of trilean values.
Practical Applications
TUF_LOGIC excels in financial market scenarios where decision-making must account for uncertainty. It enables technical indicator consensus by combining signals with different confidence levels, supports multi-timeframe analysis by reconciling potentially contradictory signals, enhances risk management by explicitly modeling uncertainty, and handles partial information systems where some data sources may be unreliable.
By providing a mathematically sound framework for reasoning about uncertainty, TUF_LOGIC elevates trading system design beyond simplistic binary logic, allowing for more sophisticated decision-making that better reflects real-world market complexity.
Library "TUF_LOGIC"
Three-Value Logic (TUF: True, Uncertain, False) implementation for Pine Script.
This library provides a comprehensive set of logical operations supporting trilean logic systems,
including Kleene, Łukasiewicz, and RM3 implications. Compatible with Pine v6 enums.
method validate(self)
Ensures a valid trilean integer value by clamping to the appropriate range .
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The integer value to validate.
Returns: An integer value guaranteed to be within the valid trilean range.
method to_trilean(self)
Converts an integer value to a Trilean enum value.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The integer to convert (typically -1, 0, or 1).
Returns: A Trilean enum value: True (1), Uncertain (0), or False (-1).
method to_int(self)
Converts a Trilean enum value to its corresponding integer representation.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The Trilean enum value to convert.
Returns: Integer value: 1 (True), 0 (Uncertain), or -1 (False).
method NOT(self)
Negates a trilean integer value (NOT operation).
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The integer value to negate.
Returns: Negated integer value: 1 -> -1, 0 -> 0, -1 -> 1.
method NOT(self)
Negates a Trilean enum value (NOT operation).
Namespace types: series Trilean
Parameters:
self (series Trilean) : The Trilean enum value to negate.
Returns: Negated Trilean: True -> False, Uncertain -> Uncertain, False -> True.
method AND(self, comparator)
Logical AND operation for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The first integer value.
comparator (int) : The second integer value to compare with.
Returns: Integer result of the AND operation (minimum value).
method AND(self, comparator)
Logical AND operation for Trilean enum values following three-valued logic.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The first Trilean enum value.
comparator (series Trilean) : The second Trilean enum value to compare with.
Returns: Trilean result of the AND operation.
method OR(self, comparator)
Logical OR operation for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The first integer value.
comparator (int) : The second integer value to compare with.
Returns: Integer result of the OR operation (maximum value).
method OR(self, comparator)
Logical OR operation for Trilean enum values following three-valued logic.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The first Trilean enum value.
comparator (series Trilean) : The second Trilean enum value to compare with.
Returns: Trilean result of the OR operation.
method EQUALITY(self, comparator)
Logical EQUALITY operation for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The first integer value.
comparator (int) : The second integer value to compare with.
Returns: Integer representation (1/-1) indicating if values are equal.
method EQUALITY(self, comparator)
Logical EQUALITY operation for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The first Trilean enum value.
comparator (series Trilean) : The second Trilean enum value to compare with.
Returns: Trilean.True if both values are equal, Trilean.False otherwise.
method XOR(self, comparator)
Logical XOR (Exclusive OR) operation for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The first integer value.
comparator (int) : The second integer value to compare with.
Returns: Integer result of the XOR operation.
method XOR(self, comparator)
Logical XOR (Exclusive OR) operation for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The first Trilean enum value.
comparator (series Trilean) : The second Trilean enum value to compare with.
Returns: Trilean result of the XOR operation.
method IMP_K(self, comparator)
Material implication using Kleene's logic for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The antecedent integer value.
comparator (int) : The consequent integer value.
Returns: Integer result of Kleene's implication operation.
method IMP_K(self, comparator)
Material implication using Kleene's logic for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The antecedent Trilean enum value.
comparator (series Trilean) : The consequent Trilean enum value.
Returns: Trilean result of Kleene's implication operation.
method IMP_L(self, comparator)
Logical implication using Łukasiewicz's logic for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The antecedent integer value.
comparator (int) : The consequent integer value.
Returns: Integer result of Łukasiewicz's implication operation.
method IMP_L(self, comparator)
Logical implication using Łukasiewicz's logic for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The antecedent Trilean enum value.
comparator (series Trilean) : The consequent Trilean enum value.
Returns: Trilean result of Łukasiewicz's implication operation.
method IMP_RM3(self, comparator)
Logical implication using RM3 logic for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The antecedent integer value.
comparator (int) : The consequent integer value.
Returns: Integer result of the RM3 implication operation.
method IMP_RM3(self, comparator)
Logical implication using RM3 logic for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The antecedent Trilean enum value.
comparator (series Trilean) : The consequent Trilean enum value.
Returns: Trilean result of the RM3 implication operation.
method MA(self)
Modal Assertion (MA) operation for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The integer value to evaluate.
Returns: 1 if the value is 1 or 0, -1 if the value is -1.
method MA(self)
Modal Assertion (MA) operation for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The Trilean enum value to evaluate.
Returns: Trilean.True if value is True or Uncertain, Trilean.False if value is False.
method LA(self)
Logical Assertion (LA) operation for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The integer value to evaluate.
Returns: 1 if the value is 1, -1 otherwise.
method LA(self)
Logical Assertion (LA) operation for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The Trilean enum value to evaluate.
Returns: Trilean.True if value is True, Trilean.False otherwise.
method IA(self)
Indeterminacy Assertion (IA) operation for trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The integer value to evaluate.
Returns: 1 if the value is 0, -1 otherwise.
method IA(self)
Indeterminacy Assertion (IA) operation for Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The Trilean enum value to evaluate.
Returns: Trilean.True if value is Uncertain, Trilean.False otherwise.
method UNANIMOUS(self, comparator)
Evaluates the unanimity between two trilean integer values.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The first integer value.
comparator (int) : The second integer value.
Returns: Integer value of self if both values are equal, 0 (Uncertain) otherwise.
method UNANIMOUS(self, comparator)
Evaluates the unanimity between two Trilean enum values.
Namespace types: series Trilean
Parameters:
self (series Trilean) : The first Trilean enum value.
comparator (series Trilean) : The second Trilean enum value.
Returns: Value of self if both values are equal, Trilean.Uncertain otherwise.
method UNANIMOUS(self)
Evaluates the unanimity among an array of trilean integer values.
Namespace types: array
Parameters:
self (array) : The array of integer values.
Returns: First value if all values are identical, 0 (Uncertain) otherwise.
method UNANIMOUS(self)
Evaluates the unanimity among an array of Trilean enum values.
Namespace types: array
Parameters:
self (array) : The array of Trilean enum values.
Returns: First value if all values are identical, Trilean.Uncertain otherwise.
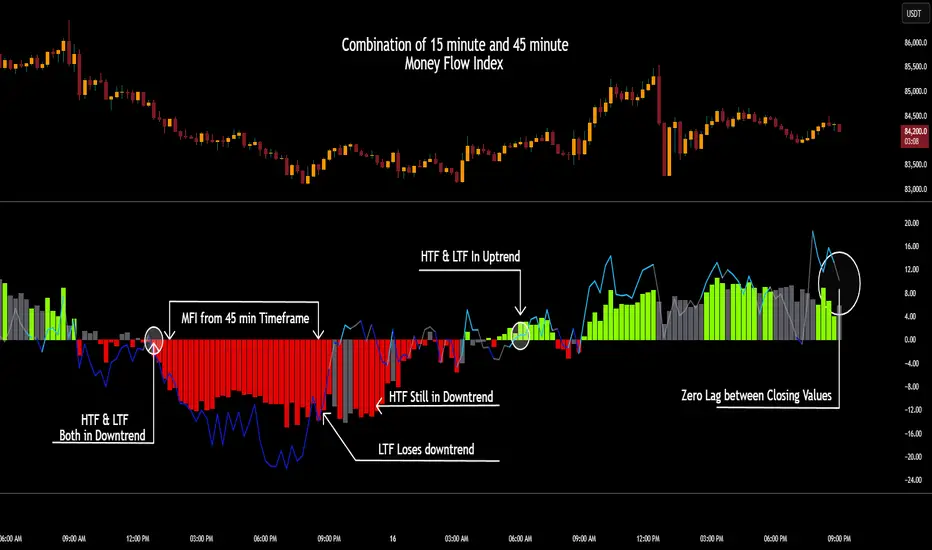
CSCMultiTimeframeToolsLibrary "CSCMultiTimeframeTools"
Calculates instant higher timeframe values for higher timeframe analysis with zero lag.
getAdjustedLookback(current_tf_minutes, higher_tf_minutes, length)
Calculate adjusted lookback period for higher timeframe conversion.
Parameters:
current_tf_minutes (int) : Current chart timeframe in minutes (e.g., 5 for 5m).
higher_tf_minutes (int) : Target higher timeframe in minutes (e.g., 15 for 15m).
length (int) : Base length value (e.g., 14 for RSI/MFI).
Returns: Adjusted lookback period (length × multiplier).
Purpose and Benefits of the TimeframeTools Library
This library is designed to solve a critical pain point for traders who rely on higher timeframe (HTF) indicator values while analyzing lower timeframe (LTF) charts. Traditional methods require waiting for multiple candles to close—for example, to see a 1-hour RSI on a 5-minute chart, you’d need 12 closed candles (5m × 12 = 60m) before the value updates. This lag means missed opportunities, delayed signals, and inefficient decision-making.
Why Traders Need This
Whether you’re scalping (5M/15M) or swing trading (1H/4H), this library bridges the gap between timeframes, giving you HTF context in real time—so you can act faster, with confidence.
How This Library Eliminates the Waiting Game
By dynamically calculating the adjusted lookback period, the library allows:
Real-time HTF values on LTF charts – No waiting for candle closes.
Accurate conversions – A 14-period RSI on a 1-hour chart translates to 168 periods (14 × 12) on a 5-minute chart, ensuring mathematical precision.
Flexible application – Works with common indicators like RSI, MFI, CCI, and moving averages (though confirmations should be done before publishing under your own secondary use).
Key Advantages Over Manual Methods
Speed: Instantly reflects HTF values without waiting for candle resolutions.
Adaptability: Adjusts automatically if the user changes timeframes or lengths.
Consistency: Removes human error in manual period calculations.
Limitations to Note
Not a magic bullet – While it solves the lag issue, traders should still:
Validate signals with price action or additional confirmations.
Be mindful of extreme lookback lengths (e.g., a 200-period daily SMA on a 1-minute chart requires 28,800 periods, which may strain performance).
FunctionSurvivalEstimationLibrary "FunctionSurvivalEstimation"
The Survival Estimation function, also known as Kaplan-Meier estimation or product-limit method, is a statistical technique used to estimate the survival probability of an individual over time. It's commonly used in medical research and epidemiology to analyze the survival rates of patients with different treatments, diseases, or risk factors.
What does it do?
The Survival Estimation function takes into account censored observations (i.e., individuals who are still alive at a certain point) and calculates the probability that an individual will survive beyond a specific time period. It's particularly useful when dealing with right-censoring, where some subjects are lost to follow-up or have not experienced the event of interest by the end of the study.
Interpretation
The Survival Estimation function provides a plot of the estimated survival probability over time, which can be used to:
1. Compare survival rates between different groups (e.g., treatment arms)
2. Identify patterns in the data that may indicate differences in mortality or disease progression
3. Make predictions about future outcomes based on historical data
4. In a trading context it may be used to ascertain the survival ratios of trading under specific conditions.
Reference:
www.global-developments.org
"Beyond GDP" ~ www.aeaweb.org
en.wikipedia.org
www.kdnuggets.com
survival_probability(alive_at_age, initial_alive)
Kaplan-Meier Survival Estimator.
Parameters:
alive_at_age (int) : The number of subjects still alive at a age.
initial_alive (int) : The Total number of initial subjects.
Returns: The probability that a subject lives longer than a certain age.
utility(c, l)
Captures the utility value from consumption and leisure.
Parameters:
c (float) : Consumption.
l (float) : Leisure.
Returns: Utility value from consumption and leisure.
welfare_utility(age, b, u, s)
Calculate the welfare utility value based age, basic needs and social interaction.
Parameters:
age (int) : Age of the subject.
b (float) : Value representing basic needs (food, shelter..).
u (float) : Value representing overall well-being and happiness.
s (float) : Value representing social interaction and connection with others.
Returns: Welfare utility value.
expected_lifetime_welfare(beta, consumption, leisure, alive_data, expectation)
Calculates the expected lifetime welfare of an individual based on their consumption, leisure, and survival probability over time.
Parameters:
beta (float) : Discount factor.
consumption (array) : List of consumption values at each step of the subjects life.
leisure (array) : List of leisure values at each step of the subjects life.
alive_data (array) : List of subjects alive at each age, the first element is the total or initial number of subjects.
expectation (float) : Optional, `defaut=1.0`. Expectation or weight given to this calculation.
Returns: Expected lifetime welfare value.

PineVersatilitiesBundleLibrary "PineVersatilitiesBundle"
Versatilities (aka, Versatile Utilities) Pack includes:
- Eighteen Price Variants bundled in a Map,
- Nine Smoothing Variants bundled in a Map,
- Visualisations that indicate on both - pane and chart.
price_variants(lb)
Computes Several different averages using current and previous OHLC values
Parameters:
lb (int) : - lookback distance for combining OHLC values from the past with the present
Returns: Map of Eighteen Uncommon Combinations of single and two-bar OHLC averages (rounded-to-mintick)
dynamic_MA(masrc, malen, lsmaoff, almasgm, almaoff, almaflr)
Dynamically computes Eight different MAs and returns a Map containing Nine MAs
Parameters:
masrc (float) : source series to compute MA
malen (simple int) : lookback distance for MA
lsmaoff (simple int) : optional LSMA offset - default is 0
almasgm (simple float) : optional ALMA sigma - default is 5
almaoff (simple float) : optional ALMA offset - default is 0.5
almaflr (simple bool) : optional ALMA floor flag - default is false
Returns: Map of MAs - 'ALMA', 'EMA', 'HMA', 'LSMA', 'RMA', 'SMA', 'SWMA', 'WMA', 'ALL' (rounded-to-mintick)

NR_VersatilitiesLibrary "NR_Versatilities"
Versatilities (aka, Versatile Utilities) includes:
- Seventeen Price Variants returned as a tuple,
- Eight Smoothing functions rolled into one,
- Pick any Past Value from any series with offset,
- Or just the previous value from any series.
pastVal(src, len)
Fetches past value from src that came len distance ago
Parameters:
src (float) : source series
len (int) : lookback distance - (optional) default is 1
Returns: latest src if len <= 0, else src
previous(src)
Fetches past value from src that came len distance ago
Parameters:
src (float) : source series
Returns: previous value in the series if found, else current value
price_variants()
Computes Several different averages using current and previous OHLC values
Returns: Seventeen Uncommon Average Price Combinations
dynamic_MA(matyp, masrc, malen, lsmaoff, almasgm, almaoff, almaflr)
Dynamically computes Eight different MAs on-demand individually, or an average of all taken together
Parameters:
matyp (string) : pick one of these MAs - ALMA, EMA, HMA, LSMA, RMA, SMA, SWMA, WMA, ALL
masrc (float) : source series to compute MA
malen (simple int) : lookback distance for MA
lsmaoff (simple int) : optional LSMA offset - default is 0
almasgm (simple float) : optional ALMA sigma - default is 5
almaoff (simple float) : optional ALMA offset - default is 0.5
almaflr (simple bool) : optional ALMA floor flag - default is false
Returns: MA series for chosen type or, an average of all of them, if chosen so
