Polynomial Regression Channel [ChartPrime]⯁ OVERVIEW
The Polynomial Regression Channel fits price action using advanced polynomial regression, extending beyond simple linear or logarithmic models. By leveraging matrix calculations, it builds a curved regression line that adapts to swings more naturally. The channel includes extrapolated forward projections, helping traders visualize where price may gravitate in the near future. Midline color shifts reflect directional bias, while prediction ranges are marked with dashed extensions, labeled prices, and a live table for clarity.
⯁ KEY FEATURES
Polynomial Regression Core:
Uses matrix algebra to calculate a polynomial fit of customizable degree, adapting to complex, non-linear market structures.
polyreg(source, length, degree, extrapolate) =>
total = length + extrapolate
X_all = matrix.new(total, degree + 1, 0.0)
for i = 0 to total - 1
for j = 0 to degree
matrix.set(X_all, i, j, math.pow(i, j))
// y (length × 1), oldest→newest over the fit window
y = matrix.new(length, 1, 0.0)
for i = 0 to length - 1
matrix.set(y, i, 0, source )
// X_train (first `length` rows of X_all)
X_tr = matrix.new(length, degree + 1, 0.0)
for i = 0 to length - 1
for j = 0 to degree
matrix.set(X_tr, i, j, matrix.get(X_all, i, j))
// OLS via normal equations: (X'X)^(-1)b = X'y ⇒ b = (X'X)^(-1) X'y
Xt = matrix.transpose(X_tr) // X'
XtX = matrix.mult(Xt, X_tr) // (X'X)
Xty = matrix.mult(Xt, y) // X'y
XtX_inv = matrix.inv(XtX) // (X'X)^(-1)
b = matrix.mult(XtX_inv, Xty) // b = (X'X)^(-1) X'y
// Predictions for all rows (fit + extrap)
preds = matrix.mult(X_all, matrix.col(b,0))
preds
Extrapolated Future Projections:
Forward-looking range (dashed lines + circular markers) shows where the fitted polynomial suggests price may move.
Dynamic Midline Coloring:
Regression midline shifts green when slope turns upward and magenta when slope turns downward, giving instant directional context.
Channel Boundaries:
Upper and lower levels expand from the midline using a volatility-based offset, framing potential overbought and oversold conditions.
Top-Right Data Table:
A live table displays Upper, Middle, and Lower Prediction values, updating in real time for quick reference without scanning the chart.
⯁ USAGE
Use the regression midline to gauge underlying market bias; green slopes suggest continuation, magenta slopes caution for weakness.
Watch dashed extrapolated ranges as potential targets or reaction zones during upcoming sessions.
Price labels and table values act as precise reference levels for planning entries, exits, or stop placement.
Increase Degree for more curve-fitting on choppy markets, or keep it low for broader trend approximation.
Adjust Period and Extrapolate length to balance stability vs. responsiveness.
⯁ CONCLUSION
The Polynomial Regression Channel offers a mathematically advanced way to visualize price trends and anticipate future paths. With matrix-driven polynomial fitting, extrapolated projections, and integrated live labels, it combines statistical rigor with practical trading visuals — a robust upgrade over standard regression channels.
Polynomial

Smooth Theil-SenI wanted to build a Theil-Sen estimator that could run on more than one bar and produce smoother output than the standard implementation. Theil-Sen regression is a non-parametric method that calculates the median slope between all pairs of points in your dataset, which makes it extremely robust to outliers. The problem is that median operations produce discrete jumps, especially when you're working with limited sample sizes. Every time the median shifts from one value to another, you get a step change in your regression line, which creates visual choppiness that can be distracting even though the underlying calculations are sound.
The solution I ended up going with was convolving a Gaussian kernel around the center of the sorted lists to get a more continuous median estimate. Instead of just picking the middle value or averaging the two middle values when you have an even sample size, the Gaussian kernel weights the values near the center more heavily and smoothly tapers off as you move away from the median position. This creates a weighted average that behaves like a median in terms of robustness but produces much smoother transitions as new data points arrive and the sorted list shifts.
There are variance tradeoffs with this approach since you're no longer using the pure median, but they're minimal in practice. The kernel weighting stays concentrated enough around the center that you retain most of the outlier resistance that makes Theil-Sen useful in the first place. What you gain is a regression line that updates smoothly instead of jumping discretely, which makes it easier to spot genuine trend changes versus just the statistical noise of median recalculation. The smoothness is particularly noticeable when you're running the estimator over longer lookback periods where the sorted list is large enough that small kernel adjustments have less impact on the overall center of mass.
The Gaussian kernel itself is a bell curve centered on the median position, with a standard deviation you can tune to control how much smoothing you want. Tighter kernels stay closer to the pure median behavior and give you more discrete steps. Wider kernels spread the weighting further from the center and produce smoother output at the cost of slightly reduced outlier resistance. The default settings strike a balance that keeps the estimator robust while removing most of the visual jitter.
Running Theil-Sen on multiple bars means calculating slopes between all pairs of points across your lookback window, sorting those slopes, and then applying the Gaussian kernel to find the weighted center of that sorted distribution. This is computationally more expensive than simple moving averages or even standard linear regression, but Pine Script handles it well enough for reasonable lookback lengths. The benefit is that you get a trend estimate that doesn't get thrown off by individual spikes or anomalies in your price data, which is valuable when working with noisy instruments or during volatile periods where traditional regression lines can swing wildly.
The implementation maintains sorted arrays for both the slope calculations and the final kernel weighting, which keeps everything organized and makes the Gaussian convolution straightforward. The kernel weights are precalculated based on the distance from the center position, then applied as multipliers to the sorted slope values before summing to get the final smoothed median slope. That slope gets combined with an intercept calculation to produce the regression line values you see plotted on the chart.
What this really demonstrates is that you can take classical statistical methods like Theil-Sen and adapt them with signal processing techniques like kernel convolution to get behavior that's more suited to real-time visualization. The pure mathematical definition of a median is discrete by nature, but financial charts benefit from smooth, continuous lines that make it easier to track changes over time. By introducing the Gaussian kernel weighting, you preserve the core robustness of the median-based approach while gaining the visual smoothness of methods that use weighted averages. Whether that smoothness is worth the minor variance tradeoff depends on your use case, but for most charting applications, the improved readability makes it a good compromise.

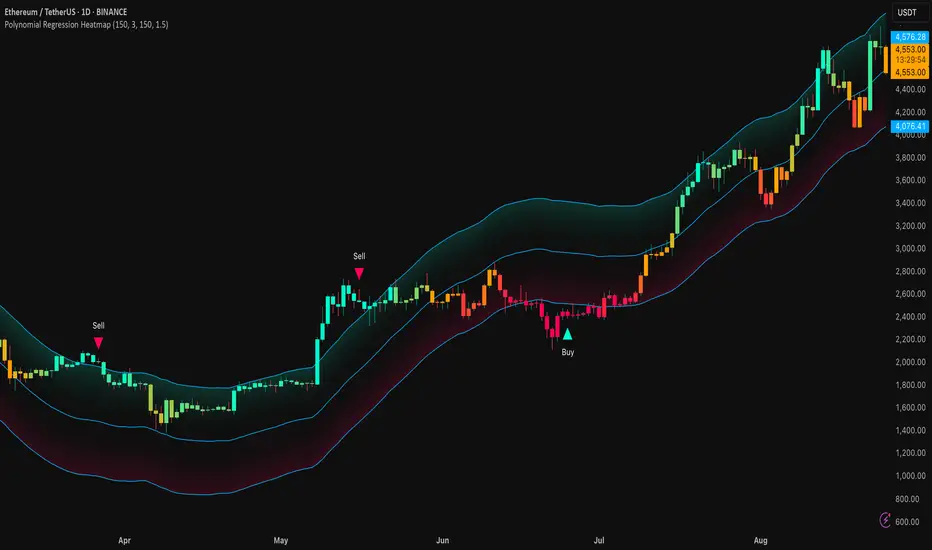
Polynomial Regression HeatmapPolynomial Regression Heatmap – Advanced Trend & Volatility Visualizer
Overview
The Polynomial Regression Heatmap is a sophisticated trading tool designed for traders who require a clear and precise understanding of market trends and volatility. By applying a second-degree polynomial regression to price data, the indicator generates a smooth trend curve, augmented with adaptive volatility bands and a dynamic heatmap. This framework allows users to instantly recognize trend direction, potential reversals, and areas of market strength or weakness, translating complex price action into a visually intuitive map.
Unlike static trend indicators, the Polynomial Regression Heatmap adapts to changing market conditions. Its visual design—including color-coded candles, regression bands, optional polynomial channels, and breakout markers—ensures that price behavior is easy to interpret. This makes it suitable for scalping, swing trading, and longer-term strategies across multiple asset classes.
How It Works
The core of the indicator relies on fitting a second-degree polynomial to a defined lookback period of price data. This regression curve captures the non-linear nature of market movements, revealing the true trajectory of price beyond the distortions of noise or short-term volatility.
Adaptive upper and lower bands are constructed using ATR-based scaling, surrounding the regression line to reflect periods of high and low volatility. When price moves toward or beyond these bands, it signals areas of potential overextension or support/resistance.
The heatmap colors each candle based on its relative position within the bands. Green shades indicate proximity to the upper band, red shades indicate proximity to the lower band, and neutral tones represent mid-range positioning. This continuous gradient visualization provides immediate feedback on trend strength, market balance, and potential turning points.
Optional polynomial channels can be overlaid around the regression curve. These three-line channels are based on regression residuals and a fixed width multiplier, offering additional reference points for analyzing price deviations, trend continuation, and reversion zones.
Signals and Breakouts
The Polynomial Regression Heatmap includes statistical pivot-based signals to highlight actionable price movements:
Buy Signals – A triangular marker appears below the candle when a pivot low occurs below the lower regression band.
Sell Signals – A triangular marker appears above the candle when a pivot high occurs above the upper regression band.
These markers identify significant deviations from the regression curve while accounting for volatility, providing high-quality visual cues for potential entry points.
The indicator ensures clarity by spacing markers vertically using ATR-based calculations, preventing overlap during periods of high volatility. Users can rely on these signals in combination with heatmap intensity and regression slope for contextual confirmation.
Interpretation
Trend Analysis :
The slope of the polynomial regression line represents trend direction. A rising curve indicates bullish bias, a falling curve indicates bearish bias, and a flat curve indicates consolidation.
Steeper slopes suggest stronger momentum, while gradual slopes indicate more moderate trend conditions.
Volatility Assessment :
Band width provides an instant visual measure of market volatility. Narrow bands correspond to low volatility and potential consolidation, whereas wide bands indicate higher volatility and significant price swings.
Heatmap Coloring :
Candle colors visually represent price position within the bands. This allows traders to quickly identify zones of bullish or bearish pressure without performing complex calculations.
Channel Analysis (Optional) :
The polynomial channel defines zones for evaluating potential overextensions or retracements. Price interacting with these lines may suggest areas where mean-reversion or trend continuation is likely.
Breakout Signals :
Buy and Sell markers highlight pivot points relative to the regression and volatility bands. These are statistical signals, not arbitrary triggers, and should be interpreted in context with trend slope, band width, and heatmap intensity.
Strategy Integration
The Polynomial Regression Heatmap supports multiple trading approaches:
Trend Following – Enter trades in the direction of the regression slope while using the heatmap for momentum confirmation.
Pullback Entries – Use breakouts or deviations from the regression bands as low-risk entry points during trend continuation.
Mean Reversion – Price reaching outer channel boundaries can indicate potential reversal or retracement opportunities.
Multi-Timeframe Alignment – Overlay on higher and lower timeframes to filter noise and improve entry timing.
Stop-loss levels can be set just beyond the opposing regression band, while take-profit targets can be informed by the distance between the bands or the curvature of the polynomial line.
Advanced Techniques
For traders seeking greater precision:
Combine the Polynomial Regression Heatmap with volume, momentum, or volatility indicators to validate signals.
Observe the width and slope of the regression bands over time to anticipate expanding or contracting volatility.
Track sequences of breakout signals in conjunction with heatmap intensity for systematic trade management.
Adjusting regression length allows customization for different assets or timeframes, balancing responsiveness and smoothing. The combination of polynomial curve, adaptive bands, heatmap, and optional channels provides a comprehensive statistical framework for informed decision-making.
Inputs and Customization
Regression Length – Determines the number of bars used for polynomial fitting. Shorter lengths increase responsiveness; longer lengths improve smoothing.
Show Bands – Toggle visibility of the ATR-based regression bands.
Show Channel – Enable or disable the polynomial channel overlay.
Color Settings – Customize bullish, bearish, neutral, and accent colors for clarity and visual preference.
All other internal parameters are fixed to ensure consistent statistical behavior and minimize potential misconfiguration.
Why Use Polynomial Regression Heatmap
The Polynomial Regression Heatmap transforms complex price action into a clear, actionable visual framework. By combining non-linear trend mapping, adaptive volatility bands, heatmap visualization, and breakout signals, it provides a multi-dimensional perspective that is both quantitative and intuitive.
This indicator allows traders to focus on execution, interpret market structure at a glance, and evaluate trend strength, overextensions, and potential reversals in real time. Its design is compatible with scalping, swing trading, and long-term strategies, providing a robust tool for disciplined, data-driven trading.
N-Degree Moment-Based Adaptive Detection🙏🏻 N-Degree Moment-Based Adaptive Detection (NDMBAD) method is a generalization of MBAD since the horizontal line fit passing through the data's mean can be simply treated as zero-degree polynomial regression. We can extend the MBAD logic to higher-degree polynomial regression.
I don't think I need to talk a lot about the thing there; the logic is really the same as in MBAD, just hit the link above and read if you want. The only difference is now we can gather cumulants not only from the horizontal mean fit (degree = 0) but also from higher-order polynomial regression fit, including linear regression (degree = 1).
Why?
Simply because residuals from the 0-degree model don't contain trend information, and while in some cases that's exactly what you need, in other cases, you want to model your trend explicitly. Imagine your underlying process trends in a steady manner, and you want to control the extreme deviations from the process's core. If you're going to use 0-degree, you'll be treating this beautiful steady trend as a residual itself, which "constantly deviates from the process mean." It doesn't make much sense.
How?
First, if you set the length to 0, you will end up with the function incrementally applied to all your data starting from bar_index 0. This can be called the expanding window mode. That's the functionality I include in all my scripts lately (where it makes sense). As I said in the MBAD description, choosing length is a matter of doing business & applied use of my work, but I think I'm open to talk about it.
I don't see much sense in using degree > 1 though (still in research on it). If you have dem curves, you can use Fourier transform -> spectral filtering / harmonic regression (regression with Fourier terms). The job of a degree > 0 is to model the direction in data, and degree 1 gets it done. In mean reversion strategies, it means that you don't wanna put 0-degree polynomial regression (i.e., the mean) on non-stationary trending data in moving window mode because, this way, your residuals will be contaminated with the trend component.
By the way, you can send thanks to @aaron294c , he said like mane MBAD is dope, and it's gonna really complement his work, so I decided to drop NDMBAD now, gonna be more useful since it covers more types of data.
I wanned to call it N-Order Moment Adaptive Detection because it abbreviates to NOMAD, which sounds cool and suits me well, because when I perform as a fire dancer, nomad style is one of my outfits. Burning Man stuff vibe, you know. But the problem is degree and order really mean two different things in the polynomial context, so gotta stay right & precise—that's the priority.
∞

Advanced Weighted Residual Arbitrage AnalyzerThe Advanced Weighted Residual Arbitrage Analyzer is a sophisticated tool designed for traders aiming to exploit price deviations between various asset pairs. By examining the differences in normalized price relations and their weighted residuals, this indicator provides insights into potential arbitrage opportunities in the market.
Key Features:
Multiple Relation Analysis: Analyze up to five different asset relations simultaneously, offering a comprehensive view of potential arbitrage setups.
Normalization Functions: Choose from a variety of normalization techniques like SMA, EMA, WMA, and HMA to ensure accurate comparisons between different price series.
Dynamic Weighting: Residuals are weighted based on their correlation, ensuring that stronger correlations have a more pronounced impact on the analysis. Weighting can be adjusted using several functions including square, sigmoid, and logistic.
Regression Flexibility: Incorporate linear, polynomial, or robust regression to calculate residuals, tailoring the analysis to different market conditions.
Customizable Display: Decide which plots to display for clarity and focus, including normalized relations, weighted residuals, and the difference between the screen relation and the average weighted residual.
Usage Guidelines:
Configure the asset pairs you wish to analyze using the Symbol Relations group in the settings.
Adjust the normalization, volatility, regression, and weighting functions based on your preference and the specific characteristics of the asset pairs.
Monitor the weighted residuals for deviations from the mean. Larger deviations suggest stronger arbitrage opportunities.
Use the difference plot (between the screen relation and average weighted residual) as a quick visual cue for potential trade setups. When this plot deviates significantly from zero, it indicates a possible arbitrage opportunity.
Regularly update and adjust the parameters to account for changing market conditions and ensure the most accurate analysis.
In the Advanced Weighted Residual Arbitrage Analyzer , the value set in Alert Threshold plays a crucial role in delineating a normalized band. This band serves as a guide to identify significant deviations and potential trading opportunities.
When we observe the plots of the green line and the purple line, the Alert Threshold provides a boundary for these plots. The following points explain the significance:
Breach of the Band: When either the green or purple line crosses above or below the Alert Threshold , it indicates a significant deviation from the mean. This breach can be interpreted as a potential trading signal, suggesting a possible arbitrage opportunity.
Convergence to the Mean: If the green line converges with the purple line , it denotes that the price relation has reverted to its mean. This convergence typically suggests that the arbitrage opportunity has been exhausted, and the market dynamics are returning to equilibrium.
Trade Execution: A trader can consider entering a trade when the lines breach the Alert Threshold . The return of the green line to align closely with the purple line can be seen as a signal to exit the trade, capitalizing on the reversion to the mean.
By monitoring these plots in conjunction with the Alert Threshold , traders can gain insights into market imbalances and exploit potential arbitrage opportunities. The convergence and divergence of these lines, relative to the normalized band, serve as valuable visual cues for trade initiation and termination.
When you're analyzing relations between two symbols (for instance, BINANCE:SANDUSDT/BINANCE:NEARUSDT ), you're essentially looking at the price relationship between the two underlying assets. This relationship provides insights into potential imbalances between the assets, which arbitrage traders can exploit.
Breach of the Lower Band: If the purple line touches or crosses below the lower Alert Threshold , it indicates that the first symbol (in our example, SANDUSDT ) is undervalued relative to the second symbol ( NEARUSDT ). In practical terms:
Action: You would consider buying the first symbol ( SANDUSDT ) and selling the second symbol ( NEARUSDT ).
Rationale: The expectation is that the price of the first symbol will rise, or the price of the second symbol will fall, or both, thereby converging back to their historical mean relationship.
Breach of the Upper Band: Conversely, if the difference plot touches or crosses above the upper Alert Threshold , it suggests that the first symbol is overvalued compared to the second. This implies:
Action: You'd consider selling the first symbol ( SANDUSDT ) and buying the second symbol ( NEARUSDT ).
Rationale: The anticipation here is that the price of the first symbol will decrease, or the price of the second will increase, or both, bringing the relationship back to its historical average.
Convergence to the Mean: As mentioned earlier, when the green line aligns closely with the purple line, it's an indication that the assets have returned to their typical price relationship. This serves as a signal for traders to consider closing out their positions, locking in the gains from the arbitrage opportunity.
It's important to note that when you're trading based on symbol relations, you're essentially betting on the relative performance of the two assets. This strategy, often referred to as "pairs trading," seeks to capitalize on price imbalances between related financial instruments. By taking opposing positions in the two symbols, traders aim to profit from the eventual reversion of the price difference to the mean.

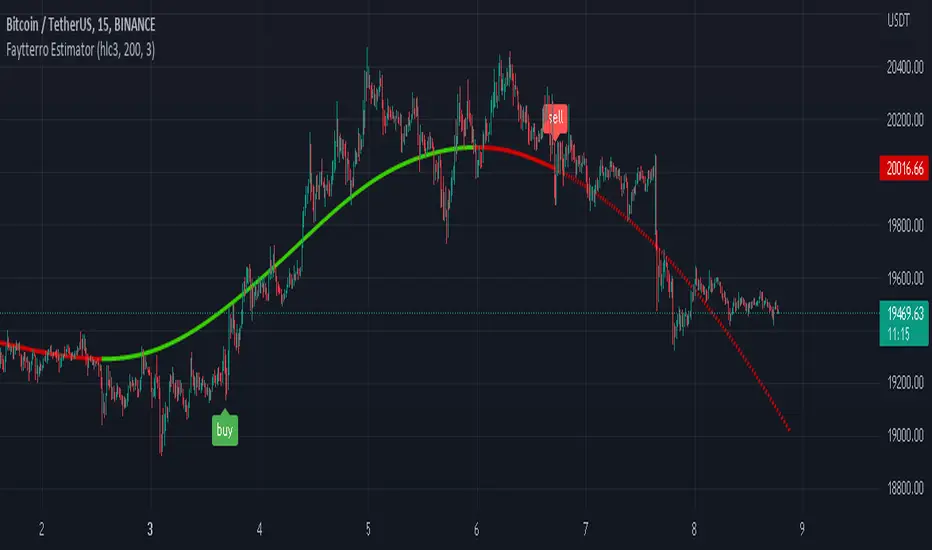
Faytterro EstimatorWhat is Faytterro Estimator?
This indicator is an advanced moving average.
What it does?
This indicator is both a moving average and at the same time, it predicts the future values that the price may take based on the values it has taken before.
How it does it?
takes the weighted average of data of the selected length (reducing the weight from the middle to the ends). then draws a parabola through the last three values, creating a predicted line.
How to use it?
it is simple to use. You can use it both as a regression to review past prices, and to predict the future value of a price. uptrends are in green and downtrends are in red. color change indicates a possible trend change.
Polynomial Regression Derivatives [Loxx]Polynomial Regression Derivatives is an indicator that explores the different derivatives of polynomial position. This indicator also includes a signal line. In a later release, alerts with signal markings will be added.
Polynomial Derivatives are as follows
1rst Derivative - Velocity: Velocity is the directional speed of a object in motion as an indication of its rate of change in position as observed from a particular frame of reference and as measured by a particular standard of time (e.g. 60 km/h northbound). Velocity is a fundamental concept in kinematics, the branch of classical mechanics that describes the motion of bodies.
2nd Derivative - Acceleration: In mechanics, acceleration is the rate of change of the velocity of an object with respect to time. Accelerations are vector quantities (in that they have magnitude and direction). The orientation of an object's acceleration is given by the orientation of the net force acting on that object.
3rd Derivative - Jerk: In physics, jerk or jolt is the rate at which an object's acceleration changes with respect to time. It is a vector quantity (having both magnitude and direction). Jerk is most commonly denoted by the symbol j and expressed in m/s3 (SI units) or standard gravities per second (g0/s).
4th Derivative - Snap: Snap, or jounce, is the fourth derivative of the position vector with respect to time, or the rate of change of the jerk with respect to time. Equivalently, it is the second derivative of acceleration or the third derivative of velocity.
5th Derivative - Crackle: The fifth derivative of the position vector with respect to time is sometimes referred to as crackle. It is the rate of change of snap with respect to time.
6nd Derivative - Pop: The sixth derivative of the position vector with respect to time is sometimes referred to as pop. It is the rate of change of crackle with respect to time.
Included:
Loxx's Expanded Source Types
Loxx's Moving Averages

Polynomial-Regression-Fitted RSI [Loxx]Polynomial-Regression-Fitted RSI is an RSI indicator that is calculated using Polynomial Regression Analysis. For this one, we're just smoothing the signal this time. And we're using an odd moving average to do so: the Sine Weighted Moving Average. The Sine Weighted Moving Average assigns the most weight at the middle of the data set. It does this by weighting from the first half of a Sine Wave Cycle and the most weighting is given to the data in the middle of that data set. The Sine WMA closely resembles the TMA (Triangular Moving Average). So we're trying to tease out some cycle information here as well, however, you can change this MA to whatever soothing method you wish. I may come back to this one and remove the point modifier and then add preliminary smoothing, but for now, just the signal gets the smoothing treatment.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression .
Included
Alerts
Signals
Bar coloring
Loxx's Expanded Source Types
Loxx's Moving Averages
Other indicators in this series using Polynomial Regression Analysis.
Poly Cycle
PA-Adaptive Polynomial Regression Fitted Moving Average
Polynomial-Regression-Fitted Oscillator
Polynomial-Regression-Fitted Oscillator [Loxx]Polynomial-Regression-Fitted Oscillator is an oscillator that is calculated using Polynomial Regression Analysis. This is an extremely accurate and processor intensive oscillator.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression .
Things to know
You can select from 33 source types
The source is smoothed before being injected into the Polynomial fitting algorithm, there are 35+ moving averages to choose from for smoothing
This indicator is very processor heavy. so it will take some time load on the chart. Ideally the period input should allow for values from 1 to 200 or more, but due to processing restraints on Trading View, the max value is 80.
Included
Alerts
Signals
Bar coloring
Other indicators in this series using Polynomial Regression Analysis.
Poly Cycle
PA-Adaptive Polynomial Regression Fitted Moving Average

PA-Adaptive Polynomial Regression Fitted Moving Average [Loxx]PA-Adaptive Polynomial Regression Fitted Moving Average is a moving average that is calculated using Polynomial Regression Analysis. The purpose of this indicator is to introduce polynomial fitting that is to be used in future indicators. This indicator also has Phase Accumulation adaptive period inputs. Even though this first indicator is for demonstration purposes only, its still one of the only viable implementations of Polynomial Regression Analysis on TradingView is suitable for trading, and while this same method can be used to project prices forward, I won't be doing that since forecasting is generally worthless and causes unavoidable repainting. This indicator only repaints on the current bar. Once the bar closes, any signal on that bar won't change.
For other similar Polynomial Regression Fitted methodologies, see here
Poly Cycle
What is the Phase Accumulation Cycle?
The phase accumulation method of computing the dominant cycle is perhaps the easiest to comprehend. In this technique, we measure the phase at each sample by taking the arctangent of the ratio of the quadrature component to the in-phase component. A delta phase is generated by taking the difference of the phase between successive samples. At each sample we can then look backwards, adding up the delta phases.When the sum of the delta phases reaches 360 degrees, we must have passed through one full cycle, on average.The process is repeated for each new sample.
The phase accumulation method of cycle measurement always uses one full cycle’s worth of historical data.This is both an advantage and a disadvantage.The advantage is the lag in obtaining the answer scales directly with the cycle period.That is, the measurement of a short cycle period has less lag than the measurement of a longer cycle period. However, the number of samples used in making the measurement means the averaging period is variable with cycle period. longer averaging reduces the noise level compared to the signal.Therefore, shorter cycle periods necessarily have a higher out- put signal-to-noise ratio.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modelled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression.
Things to know
You can select from 33 source types
The source is smoothed before being injected into the Polynomial fitting algorithm, there are 35+ moving averages to choose from for smoothing
The output of the Polynomial fitting algorithm is then smoothed to create the signal, there are 35+ moving averages to choose from for smoothing
Included
Alerts
Signals
Bar coloring
TF Segmented Polynomial Regression [LuxAlgo]This indicator displays polynomial regression channels fitted using data within a user selected time interval.
The model is fitted using the same method described in our previous script:
Settings
Degree: Degree of the fitted polynomial
Width: Multiplicative factor of the model RMSE. Controls the width of the polynomial regression's channels
Timeframe: Fits the polynomial regression using data within the selected timeframe interval
Show fit for new bars: If selected, will fit the regression model for newly generated bars, else the previous fitted value is displayed.
Src: Input source
Usage
Segmented (or piecewise) models yield multiple fits by first partitioning the data into multiple intervals from specific partitioning conditions. In this script this partitioning condition is for a user selected timeframe to change.
Segmented models can be particularly pertinent for market prices, which often describes a series of local trends.
Segmented polynomial regressions can describe the nature of underlying trends in the price from their fit, such as if an underlying trend is more linear (trending) or constant (ranging), and if a trend is monotonic.
The above chart shows a monthly partitioning on SPX 15m, using a polynomial regression of degree 3. Channel extremities allows highlighting local tops/bottoms.
For real time applications users can choose to fit a current model to incoming price data using the Show fit for new bars settings.
Details
The script does not make use of line.new to display the segmented linear regressions, which allows showing a higher number of historical fits. Each channel extremity as well as the model fit is displayed from the plot function, as such user can more easily set alerts on them.
It is important to note that achieving this requires accessing future price data, as such this script is subject to lookahead bias, historical results differ from the results one could have obtained in real-time.

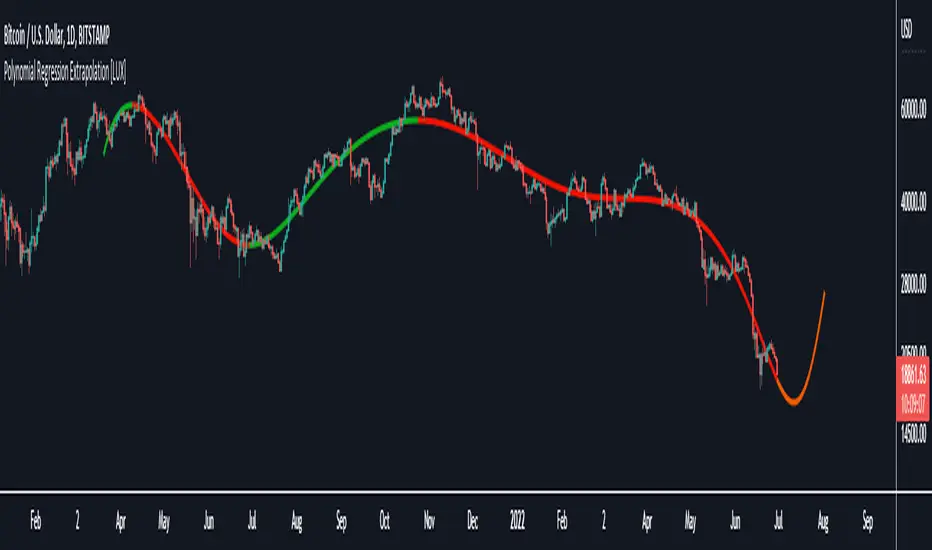
Polynomial Regression Extrapolation [LuxAlgo]This indicator fits a polynomial with a user set degree to the price using least squares and then extrapolates the result.
Settings
Length: Number of most recent price observations used to fit the model.
Extrapolate: Extrapolation horizon
Degree: Degree of the fitted polynomial
Src: Input source
Lock Fit: By default the fit and extrapolated result will readjust to any new price observation, enabling this setting allow the model to ignore new price observations, and extend the extrapolation to the most recent bar.
Usage
Polynomial regression is commonly used when a relationship between two variables can be described by a polynomial.
In technical analysis polynomial regression is commonly used to estimate underlying trends in the price as well as obtaining support/resistances. One common example being the linear regression which can be described as polynomial regression of degree 1.
Using polynomial regression for extrapolation can be considered when we assume that the underlying trend of a certain asset follows polynomial of a certain degree and that this assumption hold true for time t+1...,t+n . This is rarely the case but it can be of interest to certain users performing longer term analysis of assets such as Bitcoin.
The selection of the polynomial degree can be done considering the underlying trend of the observations we are trying to fit. In practice, it is rare to go over a degree of 3, as higher degree would tend to highlight more noisy variations.
Using a polynomial of degree 1 will return a line, and as such can be considered when the underlying trend is linear, but one could improve the fit by using an higher degree.
The chart above fits a polynomial of degree 2, this can be used to model more parabolic observations. We can see in the chart above that this improves the fit.
In the chart above a polynomial of degree 6 is used, we can see how more variations are highlighted. The extrapolation of higher degree polynomials can eventually highlight future turning points due to the nature of the polynomial, however there are no guarantee that these will reflect exact future reversals.
Details
A polynomial regression model y(t) of degree p is described by:
y(t) = β(0) + β(1)x(t) + β(2)x(t)^2 + ... + β(p)x(t)^p
The vector coefficients β are obtained such that the sum of squared error between the observations and y(t) is minimized. This can be achieved through specific iterative algorithms or directly by solving the system of equations:
β(0) + β(1)x(0) + β(2)x(0)^2 + ... + β(p)x(0)^p = y(0)
β(0) + β(1)x(1) + β(2)x(1)^2 + ... + β(p)x(1)^p = y(1)
...
β(0) + β(1)x(t-1) + β(2)x(t-1)^2 + ... + β(p)x(t-1)^p = y(t-1)
Note that solving this system of equations for higher degrees p with high x values can drastically affect the accuracy of the results. One method to circumvent this can be to subtract x by its mean.
FunctionPolynomialFitLibrary "FunctionPolynomialFit"
Performs Polynomial Regression fit to data.
In statistics, polynomial regression is a form of regression analysis in which
the relationship between the independent variable x and the dependent variable
y is modelled as an nth degree polynomial in x.
reference:
en.wikipedia.org
www.bragitoff.com
gauss_elimination(A, m, n) Perform Gauss-Elimination and returns the Upper triangular matrix and solution of equations.
Parameters:
A : float matrix, data samples.
m : int, defval=na, number of rows.
n : int, defval=na, number of columns.
Returns: float array with coefficients.
polyfit(X, Y, degree) Fits a polynomial of a degree to (x, y) points.
Parameters:
X : float array, data sample x point.
Y : float array, data sample y point.
degree : int, defval=2, degree of the polynomial.
Returns: float array with coefficients.
note:
p(x) = p * x**deg + ... + p
interpolate(coeffs, x) interpolate the y position at the provided x.
Parameters:
coeffs : float array, coefficients of the polynomial.
x : float, position x to estimate y.
Returns: float.
Polynomial Regression Style Examplejust a example on how to edit line style on the output of the polynomial regression library..

FunctionPolynomialRegressionLibrary "FunctionPolynomialRegression"
TODO:
polyreg(sample_x, sample_y) Method to return a polynomial regression channel using (X,Y) sample points.
Parameters:
sample_x : float array, sample data X points.
sample_y : float array, sample data Y points.
Returns: tuple with:
_predictions: Array with adjusted Y values.
_max_dev: Max deviation from the mean.
_min_dev: Min deviation from the mean.
_stdev/_sizeX: Average deviation from the mean.
draw(sample_x, sample_y, extend, mid_color, mid_style, mid_width, std_color, std_style, std_width, max_color, max_style, max_width) Method for drawing the Polynomial Regression into chart.
Parameters:
sample_x : float array, sample point X value.
sample_y : float array, sample point Y value.
extend : string, default=extend.none, extend lines.
mid_color : color, default=color.blue, middle line color.
mid_style : string, default=line.style_solid, middle line style.
mid_width : int, default=2, middle line width.
std_color : color, default=color.aqua, standard deviation line color.
std_style : string, default=line.style_dashed, standard deviation line style.
std_width : int, default=1, standard deviation line width.
max_color : color, default=color.purple, max range line color.
max_style : string, default=line.style_dotted, max line style.
max_width : int, default=1, max line width.
Returns: line array.
Multiple Regression Polynomial ForecastEXPERIMENTAL:
Forecasting using a polynomial regression over the estimates of multiple linear regression forecasts.
note: on low data the estimates are skewd away of initial value, i added the i_min_estimate option in to try curve this issue with limited success "o_o.
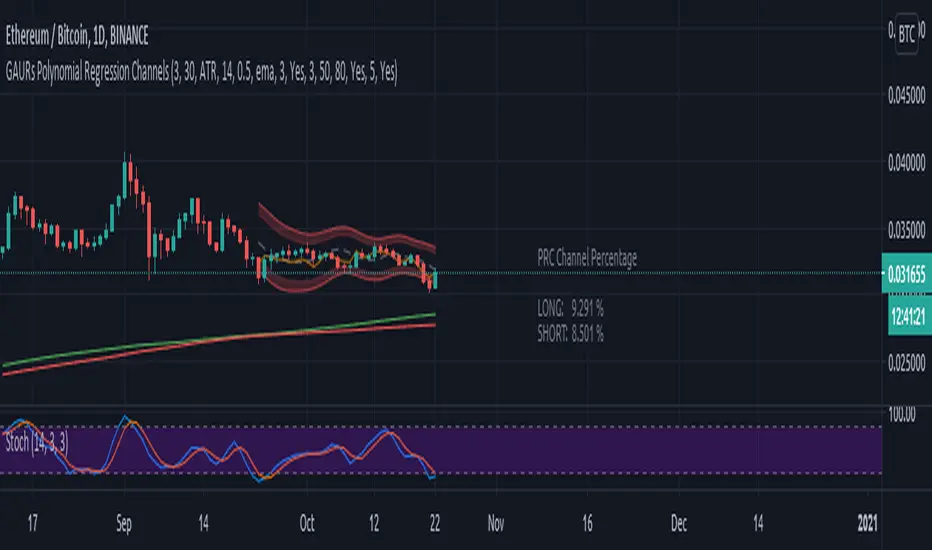
GAURs Polynomial Regression ChannelsThanks to The Sweet Lord , here is the Gaur's Polynomial Regression Channel.
Its a Polynomial Regression Channel but applied a little differently. Wont go into technical details much. Overview of options is as follows-
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Channel Options
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1. Degree of Polynomial: 1/2/3
Default = 3
Defines the degree of polynomials - 1,2,3. Note here, degree 1 will not be a straight line since its applied differently.
Try different degrees for different fits and market conditions.
2. Channel Length:
Default 30 (candles)
You can go beyond 100 or 200 candle lengths but smaller is the usual preference of Poly-Reg-channel traders. It all depends on market conditions and your style of trading. Do your research. I am usually comfortable with a range of 20-50 (in crypto markets).
3. Basis of Channel height/boundries: ATR/Manual
Default: ATR
ATR provides a dynamically adjusted entry/exit bounds of the channels. As ATR changes, the channel bounds also changes its height. It can also be fixed manually. Manual heights wont change automatically.
4. Basis of Y-Value: open/close/ sma / ema / wma /hilow
Default: close
Y- value is the y value of the (x,y) coordinates used while calculating the regression coefficients. Dont worry about it, its nothing serious.
5. Apply channel smoothning using sma?: Yes/No
Default: Yes
Without smoothning, the channel does not "look" good.
6. Shaded Area Height Percentage:
Its the extra margin for the channel. Its in percentage of the total height (defined 3 above) of channels. The shaded area provides an extra allowance for your entries or exits beyond the ATR or manual heights.
7. Plot RSI?: Yes/No
Default: Yes
Plots RSI (orange line in between the channel - its different from the dotted center line) considering the downbound of channels as 0 (oversold) and upbound of channels as 100 (overbought)
8. Plot 200 sma?: Yes/No
Default: Yes
It plots a 200 period fast (green) and 225 period slow (red) sma . I usually use two MAs. Its visually very easy to understand.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Sample Strategy
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
You can develop your own strategy with the channels. But following is just one of the ways you can trade.
Best Application: Ranging markets. But can be happily used in volatile conditions, with a little experience.
1. SMA: -- (this condition is optional really)
If green (200) is above red (225) go only long. If red is above green go only short. Defines long term trend of the market.
2. Channel slope: -- (this stuff needs practice/experience)
Depending on the channel slope, like if its tending to go up or down, you can choose to take only short or long trades. It defines short term momentum of the market.
3. ATR based heights:
Since its ATR based, the channel height are our natural entry and exit points.
Long:
When price touches lower shaded area, consider possible long entry. Exit on price entering the upper shaded area.
Short:
Enter on upper bound shaded area, exit on lower.
4. RSI:
For additional conformations. Again note, the RSI considers the lower bound of channel as 0 and upper as 100. But since, the channel moves up and down, the RSI will also move not only as RSI but also with the channel. Meaning, say if the RSI is valued at 50, then it will be near the center of the channel but since the center changes as time and price changes, the RSI valued at 50 at different times will not be at the same horizontal level respect to the graph, although it will be at the same level (center) respect to the channel.
5. PRC Channel Percentage label:
This label is at the lower side a bit ahead of the current candle. Provides you info on what is the channel percentage. This is especially helpful in crypto markets to gauge your possible percentage profit where profits can be much higher than forex or other instruments. It can also helps you select a suitable market/instrument if the channels are based on ATR.
6. Extra indicators:
I usually use stochastic along with this setup for extra conformations.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Donate
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Use freely and donate generously if you find value. Your help will really help.
I had earlier provided BTC addresses for donations but it seems to violate TV House rules.
Hope they make TV coins redeemable in future.
- Pranav Joshi
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Extra Info
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
// © cpranavjoshi
// special thanks to the "Trading View" people for providing this great platform for free
// ------------------------
// MATH
// ------------------------
// special thanks to an article on the web that provided layman friendly explanation of the maths
// unfortunately i wont be able to provide the link to that article owing to TV restrictions, though i sincerely would have liked to credit the author.
// Google search this phrase, and you should be able to get it in one of the first results - "polynomialregression Mathematics of Polynomial Regression"
// my regression math calculation is a further resolution upon the generalized matrix formula given in the that article.
// the generalized matrix looks scary but in fact its much simpler than one may assume
// the summation sign things are just float numbers that can be easily found out
// so we get a matrix with number of equations equal to the number of unknowns.
// e.g. if its a 3rd degree poly, it has 4 unknowns (c0,c1,c2,c3) with 4 equations as in the generalized matrix
// it can be resolved by simple algebra
// Note: the results have been verified with excel using same input data points.
// pine was difficult for me so i coded it in python first to verify
// ------------------------
// WHY
// ------------------------
// this script was coded because Pranav badly needed Polynomial channels (had used them in mt4 earlier)
// and at the time of this coding, i could not find any readily available script in the trading view public library ( tnx public)
// the complex math was probably the hurdle
// i m not good in maths, but by the Will of the Lord, i could resolve the issue with simple algebra and logic
// ------------------------
// PINE
// ------------------------
// i am just an average (even poor probably) programmer and pine script is not my language
// this is a humble attempt to write my first pine with whatever i could do quickly
// experts - feel free to develop if needed. have used some workarounds in drawings/plottings. rectify them if possible
//
//
// - Pranav Joshi
Example: Polynomial Regression for Spread AnalysisExample of applying polynomial regression channel to spreads or hedges between 2 assets.
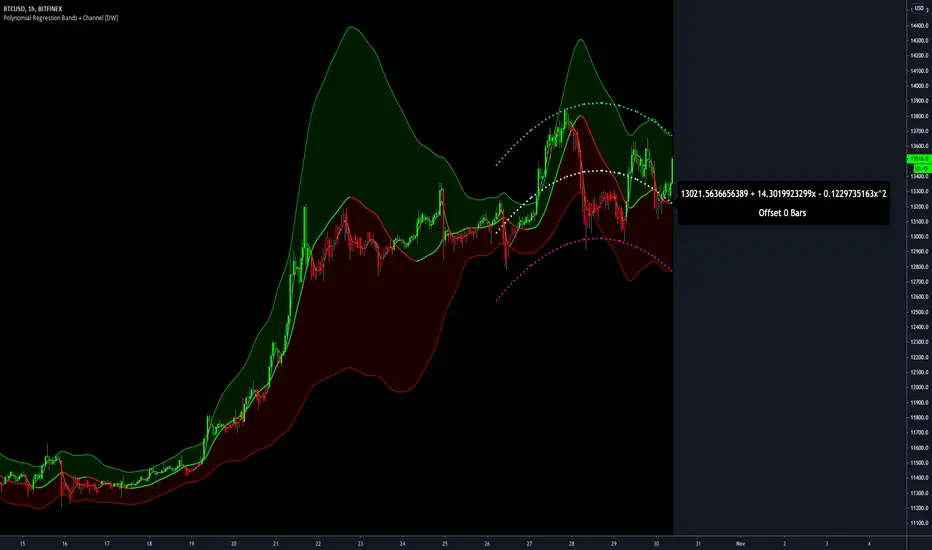
Polynomial Regression Bands + Channel [DW]This is an experimental study designed to calculate polynomial regression for any order polynomial that TV is able to support.
This study aims to educate users on polynomial curve fitting, and the derivation process of Least Squares Moving Averages (LSMAs).
I also designed this study with the intent of showcasing some of the capabilities and potential applications of TV's fantastic new array functions.
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as a polynomial of nth degree (order).
For clarification, linear regression can also be described as a first order polynomial regression. The process of deriving linear, quadratic, cubic, and higher order polynomial relationships is all the same.
In addition, although deriving a polynomial regression equation results in a nonlinear output, the process of solving for polynomials by least squares is actually a special case of multiple linear regression.
So, just like in multiple linear regression, polynomial regression can be solved in essentially the same way through a system of linear equations.
In this study, you are first given the option to smooth the input data using the 2 pole Super Smoother Filter from John Ehlers.
I chose this specific filter because I find it provides superior smoothing with low lag and fairly clean cutoff. You can, of course, implement your own filter functions to see how they compare if you feel like experimenting.
Filtering noise prior to regression calculation can be useful for providing a more stable estimation since least squares regression can be rather sensitive to noise.
This is especially true on lower sampling lengths and higher degree polynomials since the regression output becomes more "overfit" to the sample data.
Next, data arrays are populated for the x-axis and y-axis values. These are the main datasets utilized in the rest of the calculations.
To keep the calculations more numerically stable for higher periods and orders, the x array is filled with integers 1 through the sampling period rather than using current bar numbers.
This process can be thought of as shifting the origin of the x-axis as new data emerges.
This keeps the axis values significantly lower than the 10k+ bar values, thus maintaining more numerical stability at higher orders and sample lengths.
The data arrays are then used to create a pseudo 2D matrix of x power sums, and a vector of x power*y sums.
These matrices are a representation the system of equations that need to be solved in order to find the regression coefficients.
Below, you'll see some examples of the pattern of equations used to solve for our coefficients represented in augmented matrix form.
For example, the augmented matrix for the system equations required to solve a second order (quadratic) polynomial regression by least squares is formed like this:
(∑x^0 ∑x^1 ∑x^2 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 | ∑(x^2)y)
The augmented matrix for the third order (cubic) system is formed like this:
(∑x^0 ∑x^1 ∑x^2 ∑x^3 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 ∑x^4 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 ∑x^5 | ∑(x^2)y)
(∑x^3 ∑x^4 ∑x^5 ∑x^6 | ∑(x^3)y)
This pattern continues for any n ordered polynomial regression, in which the coefficient matrix is a n + 1 wide square matrix with the last term being ∑x^2n, and the last term of the result vector being ∑(x^n)y.
Thanks to this pattern, it's rather convenient to solve the for our regression coefficients of any nth degree polynomial by a number of different methods.
In this script, I utilize a process known as LU Decomposition to solve for the regression coefficients.
Lower-upper (LU) Decomposition is a neat form of matrix manipulation that expresses a 2D matrix as the product of lower and upper triangular matrices.
This decomposition method is incredibly handy for solving systems of equations, calculating determinants, and inverting matrices.
For a linear system Ax=b, where A is our coefficient matrix, x is our vector of unknowns, and b is our vector of results, LU Decomposition turns our system into LUx=b.
We can then factor this into two separate matrix equations and solve the system using these two simple steps:
1. Solve Ly=b for y, where y is a new vector of unknowns that satisfies the equation, using forward substitution.
2. Solve Ux=y for x using backward substitution. This gives us the values of our original unknowns - in this case, the coefficients for our regression equation.
After solving for the regression coefficients, the values are then plugged into our regression equation:
Y = a0 + a1*x + a1*x^2 + ... + an*x^n, where a() is the ()th coefficient in ascending order and n is the polynomial degree.
From here, an array of curve values for the period based on the current equation is populated, and standard deviation is added to and subtracted from the equation to calculate the channel high and low levels.
The calculated curve values can also be shifted to the left or right using the "Regression Offset" input
Changing the offset parameter will move the curve left for negative values, and right for positive values.
This offset parameter shifts the curve points within our window while using the same equation, allowing you to use offset datapoints on the regression curve to calculate the LSMA and bands.
The curve and channel's appearance is optionally approximated using Pine's v4 line tools to draw segments.
Since there is a limitation on how many lines can be displayed per script, each curve consists of 10 segments with lengths determined by a user defined step size. In total, there are 30 lines displayed at once when active.
By default, the step size is 10, meaning each segment is 10 bars long. This is because the default sampling period is 100, so this step size will show the approximate curve for the entire period.
When adjusting your sampling period, be sure to adjust your step size accordingly when curve drawing is active if you want to see the full approximate curve for the period.
Note that when you have a larger step size, you will see more seemingly "sharp" turning points on the polynomial curve, especially on higher degree polynomials.
The polynomial functions that are calculated are continuous and differentiable across all points. The perceived sharpness is simply due to our limitation on available lines to draw them.
The approximate channel drawings also come equipped with style inputs, so you can control the type, color, and width of the regression, channel high, and channel low curves.
I also included an input to determine if the curves are updated continuously, or only upon the closing of a bar for reduced runtime demands. More about why this is important in the notes below.
For additional reference, I also included the option to display the current regression equation.
This allows you to easily track the polynomial function you're using, and to confirm that the polynomial is properly supported within Pine.
There are some cases that aren't supported properly due to Pine's limitations. More about this in the notes on the bottom.
In addition, I included a line of text beneath the equation to indicate how many bars left or right the calculated curve data is currently shifted.
The display label comes equipped with style editing inputs, so you can control the size, background color, and text color of the equation display.
The Polynomial LSMA, high band, and low band in this script are generated by tracking the current endpoints of the regression, channel high, and channel low curves respectively.
The output of these bands is similar in nature to Bollinger Bands, but with an obviously different derivation process.
By displaying the LSMA and bands in tandem with the polynomial channel, it's easy to visualize how LSMAs are derived, and how the process that goes into them is drastically different from a typical moving average.
The main difference between LSMA and other MAs is that LSMA is showing the value of the regression curve on the current bar, which is the result of a modelled relationship between x and the expected value of y.
With other MA / filter types, they are typically just averaging or frequency filtering the samples. This is an important distinction in interpretation. However, both can be applied similarly when trading.
An important distinction with the LSMA in this script is that since we can model higher degree polynomial relationships, the LSMA here is not limited to only linear as it is in TV's built in LSMA.
Bar colors are also included in this script. The color scheme is based on disparity between source and the LSMA.
This script is a great study for educating yourself on the process that goes into polynomial regression, as well as one of the many processes computers utilize to solve systems of equations.
Also, the Polynomial LSMA and bands are great components to try implementing into your own analysis setup.
I hope you all enjoy it!
--------------------------------------------------------
NOTES:
- Even though the algorithm used in this script can be implemented to find any order polynomial relationship, TV has a limit on the significant figures for its floating point outputs.
This means that as you increase your sampling period and / or polynomial order, some higher order coefficients will be output as 0 due to floating point round-off.
There is currently no viable workaround for this issue since there isn't a way to calculate more significant figures than the limit.
However, in my humble opinion, fitting a polynomial higher than cubic to most time series data is "overkill" due to bias-variance tradeoff.
Although, this tradeoff is also dependent on the sampling period. Keep that in mind. A good rule of thumb is to aim for a nice "middle ground" between bias and variance.
If TV ever chooses to expand its significant figure limits, then it will be possible to accurately calculate even higher order polynomials and periods if you feel the desire to do so.
To test if your polynomial is properly supported within Pine's constraints, check the equation label.
If you see a coefficient value of 0 in front of any of the x values, reduce your period and / or polynomial order.
- Although this algorithm has less computational complexity than most other linear system solving methods, this script itself can still be rather demanding on runtime resources - especially when drawing the curves.
In the event you find your current configuration is throwing back an error saying that the calculation takes too long, there are a few things you can try:
-> Refresh your chart or hide and unhide the indicator.
The runtime environment on TV is very dynamic and the allocation of available memory varies with collective server usage.
By refreshing, you can often get it to process since you're basically just waiting for your allotment to increase. This method works well in a lot of cases.
-> Change the curve update frequency to "Close Only".
If you've tried refreshing multiple times and still have the error, your configuration may simply be too demanding of resources.
v4 drawing objects, most notably lines, can be highly taxing on the servers. That's why Pine has a limit on how many can be displayed in the first place.
By limiting the curve updates to only bar closes, this will significantly reduce the runtime needs of the lines since they will only be calculated once per bar.
Note that doing this will only limit the visual output of the curve segments. It has no impact on regression calculation, equation display, or LSMA and band displays.
-> Uncheck the display boxes for the drawing objects.
If you still have troubles after trying the above options, then simply stop displaying the curve - unless it's important to you.
As I mentioned, v4 drawing objects can be rather resource intensive. So a simple fix that often works when other things fail is to just stop them from being displayed.
-> Reduce sampling period, polynomial order, or curve drawing step size.
If you're having runtime errors and don't want to sacrifice the curve drawings, then you'll need to reduce the calculation complexity.
If you're using a large sampling period, or high order polynomial, the operational complexity becomes significantly higher than lower periods and orders.
When you have larger step sizes, more historical referencing is used for x-axis locations, which does have an impact as well.
By reducing these parameters, the runtime issue will often be solved.
Another important detail to note with this is that you may have configurations that work just fine in real time, but struggle to load properly in replay mode.
This is because the replay framework also requires its own allotment of runtime, so that must be taken into consideration as well.
- Please note that the line and label objects are reprinted as new data emerges. That's simply the nature of drawing objects vs standard plots.
I do not recommend or endorse basing your trading decisions based on the drawn curve. That component is merely to serve as a visual reference of the current polynomial relationship.
No repainting occurs with the Polynomial LSMA and bands though. Once the bar is closed, that bar's calculated values are set.
So when using the LSMA and bands for trading purposes, you can rest easy knowing that history won't change on you when you come back to view them.
- For those who intend on utilizing or modifying the functions and calculations in this script for their own scripts, I included debug dialogues in the script for all of the arrays to make the process easier.
To use the debugs, see the "Debugs" section at the bottom. All dialogues are commented out by default.
The debugs are displayed using label objects. By default, I have them all located to the right of current price.
If you wish to display multiple debugs at once, it will be up to you to decide on display locations at your leisure.
When using the debugs, I recommend commenting out the other drawing objects (or even all plots) in the script to prevent runtime issues and overlapping displays.
Function Polynomial RegressionDescription:
A function that returns a polynomial regression and deviation information for a data set.
Inputs:
_X: Array containing x data points.
_Y: Array containing y data points.
Outputs:
_predictions: Array with adjusted _Y values.
_max_dev: Max deviation from the mean.
_min_dev: Min deviation from the mean.
_stdev/_sizeX: Average deviation from the mean.
Resources:
en.wikipedia.org
rosettacode.org

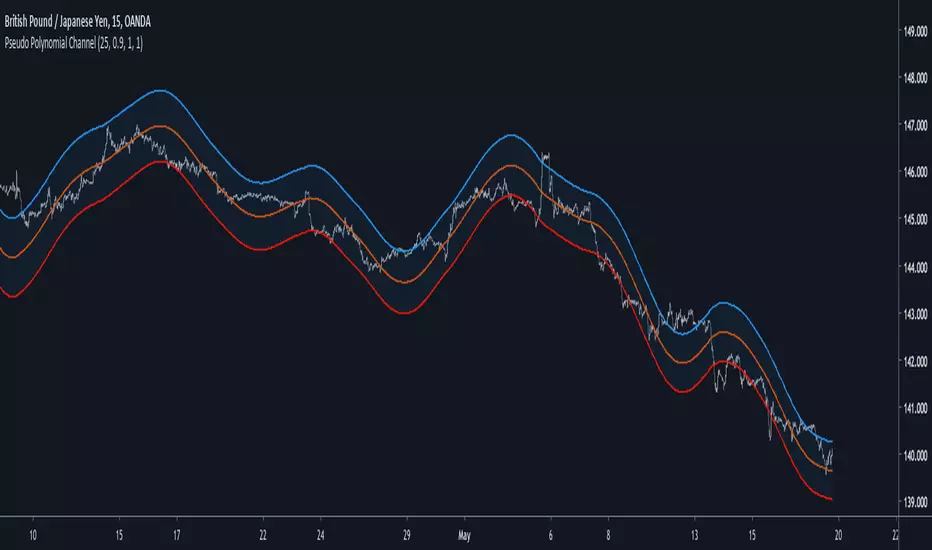
Pseudo Polynomial ChannelIntroduction
Back when i started using pine i made a script called periodic channel who aimed to rescale an average correlated sine wave to the price...don't worked very well. So i tried to fix problems induced by the indicator without much success, i had to redo it from scratch while abandoning the idea of rescaling correlated smooth functions to the price, at that time i also received requests regarding polynomial channel, some plateformes included this indicator, this led me to the idea to estimate it in order to both respond to the periodic channel problems and the requests i received, i have tried many many things and recently i tweaked a linear extrapolation to have an approximation.
Linear Extrapolation To Pseudo Polynomial Regression
I could be wrong but a polynomial regression must use constant parameters in order to provide a really smooth output, at least constant for a set of time. The moving averages forms (Savitzky-Golay moving average) who smooth polynomials across a window to the data don't have such smoothness, so how to estimate a polynomial regression while having a parameter providing control over the smoothness, a response to this is by using a recursive linear extrapolation. I posted a linear extrapolation indicator long ago, i used the same formula while adding a function to morph the output and the input in the form of :
morph * output + (1-morph) * input
How can this provide an estimate of a polynomial regression ? Well i'm not even sure myself but if you use the output as input (morph = 1) for the linear extrapolation function you should get a rough estimate of a line, this is what i thought at first and it proved to be right
Based on this observation i thought that it would be possible to get polynomial results by lowering morph, and as expected it worked well but showed a periodic pattern, this is why i smooth k in line 10.
0.9 for morph work well, higher values create sometimes smoother results but damage heavily the estimation.
Parameters
Morph have been introduced earlier, it control the amount of output and input the linear extrapolation should process, lower values create rougher but more stables results, if you see that the estimation is going nuts lower morph or change length, also lower length if you increase morph .
High overshoot, morph to 0.8 can help have a better estimation at the cost of less smoothness.
Length control the indicator smoothing, this parameter differ heavily from other filters, therefore low values can create mid/long term smoothing, it can also depend on which market instrument you are applying it, so there are no fixed optimal length.
Mult control how spread the bands are, to do so mult multiply the cumulative mean error, you can change this error measurement by anything you want like standard deviation/atr/range but take into account that you may create a separate parameter to control the error instead of length . Mult can be a float and like length can have different optimal values depending on the market the indicator is applied to.
Flatten do exactly what is name imply, it flatten the overall output to have a better estimation, can be a float. The result is less smooth.
Flatten = 2
More Exemples
BTCUSD length = 25 and mult = 4
XPDUSD length = 25 and mult = 1
ALPHABET length = 6 and morph = 0.99
Conclusion
I tried to estimate a polynomial channel by using recursion in the linear extrapolation function. This build is way more stable than the periodic channel but its still a bit inaccurate in my opinion. I hope this code can still help someone build something really nice, if so share your results :)
I apologize for those expecting a legit polynomial channel build but i really don't know how to do that, as i said parameters for the regression must be constants, i hope it still fine :)
Thanks for reading !
Generalized Average Polynomial Envelope mcbw_This is a moving average with a customizable polynomial kernel. You can shape your kernel by selecting your parameters in the settings window. This is not something that is immediately ready to mess with by just applying it on the chart, it is very useful for people who are researching indicators and developing new tools. To see the shape of your kernel you can plug it into google or wolfram. This indicator and the related ones are rather technical in nature, so feel free to comment any questions you may have and to see if anyone has asked your question.
Read more here:
Happy studying and enjoy your life!
2019 will be absolutely insane!
