█ OVERVIEW
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:

This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
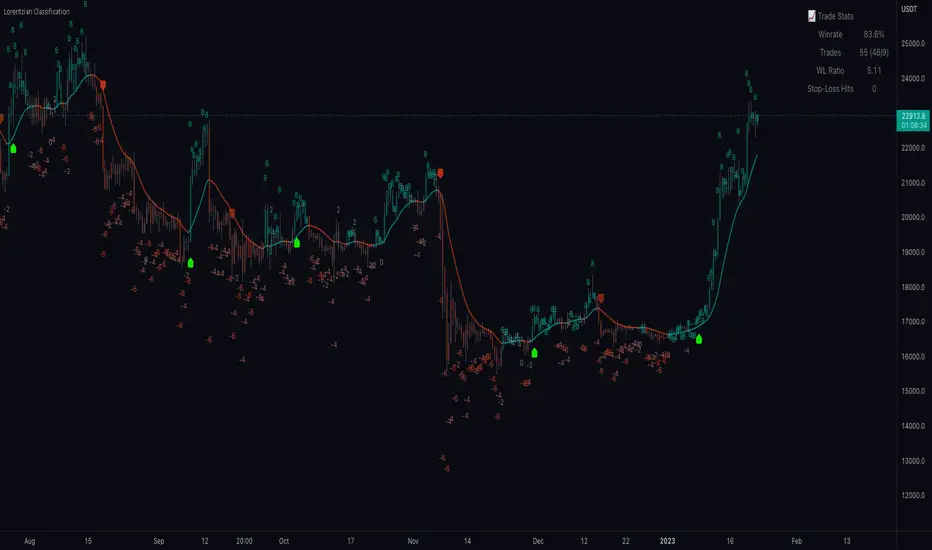
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:

Below is an explanation of the different settings for this indicator:

General Settings:
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
Filters Settings:
Kernel Regression Settings:
Display Settings:
Backtesting Settings:
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." [Online].
█ ACKNOWLEDGEMENTS
veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
meddymarkusvanhala - For helping to beta-test this indicator
dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:
This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:
Below is an explanation of the different settings for this indicator:
General Settings:
- Source - This has a default value of "hlc3" and is used to control the input data source.
- Neighbors Count - This has a default value of 8, a minimum value of 1, a maximum value of 100, and a step of 1. It is used to control the number of neighbors to consider.
- Max Bars Back - This has a default value of 2000.
- Feature Count - This has a default value of 5, a minimum value of 2, and a maximum value of 5. It controls the number of features to use for ML predictions.
- Color Compression - This has a default value of 1, a minimum value of 1, and a maximum value of 10. It is used to control the compression factor for adjusting the intensity of the color scale.
- Show Exits - This has a default value of false. It controls whether to show the exit threshold on the chart.
- Use Dynamic Exits - This has a default value of false. It is used to control whether to attempt to let profits ride by dynamically adjusting the exit threshold based on kernel regression.
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
- Feature 1 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
- Feature 2 - This has a default value of "WT" and options are: "RSI", "WT", "CCI", "ADX".
- Feature 3 - This has a default value of "CCI" and options are: "RSI", "WT", "CCI", "ADX".
- Feature 4 - This has a default value of "ADX" and options are: "RSI", "WT", "CCI", "ADX".
- Feature 5 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Filters Settings:
- Use Volatility Filter - This has a default value of true. It is used to control whether to use the volatility filter.
- Use Regime Filter - This has a default value of true. It is used to control whether to use the trend detection filter.
- Use ADX Filter - This has a default value of false. It is used to control whether to use the ADX filter.
- Regime Threshold - This has a default value of -0.1, a minimum value of -10, a maximum value of 10, and a step of 0.1. It is used to control the Regime Detection filter for detecting Trending/Ranging markets.
- ADX Threshold - This has a default value of 20, a minimum value of 0, a maximum value of 100, and a step of 1. It is used to control the threshold for detecting Trending/Ranging markets.
Kernel Regression Settings:
- Trade with Kernel - This has a default value of true. It is used to control whether to trade with the kernel.
- Show Kernel Estimate - This has a default value of true. It is used to control whether to show the kernel estimate.
- Lookback Window - This has a default value of 8 and a minimum value of 3. It is used to control the number of bars used for the estimation. Recommended range: 3-50
- Relative Weighting - This has a default value of 8 and a step size of 0.25. It is used to control the relative weighting of time frames. Recommended range: 0.25-25
- Start Regression at Bar - This has a default value of 25. It is used to control the bar index on which to start regression. Recommended range: 0-25
Display Settings:
- Show Bar Colors - This has a default value of true. It is used to control whether to show the bar colors.
- Show Bar Prediction Values - This has a default value of true. It controls whether to show the ML model's evaluation of each bar as an integer.
- Use ATR Offset - This has a default value of false. It controls whether to use the ATR offset instead of the bar prediction offset.
- Bar Prediction Offset - This has a default value of 0 and a minimum value of 0. It is used to control the offset of the bar predictions as a percentage from the bar high or close.
Backtesting Settings:
- Show Backtest Results - This has a default value of true. It is used to control whether to display the win rate of the given configuration.
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." [Online].
█ ACKNOWLEDGEMENTS
veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
meddymarkusvanhala - For helping to beta-test this indicator
dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.
版本注释
- Improved code readability and documentation based on user feedback
- Removed unused code
- Implemented improved kernel smoothing option
- Renamed alerts to be more intuitive as requested
- Added new alert for any position closure as requested
- Added new alert for any position opening as requested
- Added new alerts for kernel color changes as requested
版本注释
- Updated the library to the latest version
- Added options to filter by EMA and SMA
- Renamed "Stop-Loss" to "Early Signal Flip" to better reflect the meaning of the metric and to avoid confusion
- Added a "Use Worst Case Estimate" option to accommodate users who want the table to more closely match traditional backtest results
Note on "Use Worst Case Estimate" in the Trade Stats section:
As I've stated several times in the comments and documentation, the purpose of the Trade Stats section is to provide real-time feedback during Feature Engineering, and it is NOT meant to be used as a substitute for proper backtesting. This section was designed around the premise that this indicator is best used as a source of confluence to traditional TA, and thus, the calculations in this section by default attempt to estimate performance based on mid-bar entries (i.e. not necessarily waiting for the close of the bar as confirmation). On large timeframes, well-calculated mid-bar entries can prevent one from missing out on large moves, and thus, the default settings for the trade stats section are designed to reflect this intended use case. Despite this intended usage, there are some users who prefer to try to evaluate the indicator as a standalone strategy and try to use this section as a backtest. Although this is not recommended, the "Use Worst Case Estimate" option has been added to allow these users to more closely match traditional backtest results by waiting for the close of the bar as confirmation before entering/closing a trade. When this option is enabled, it is recommended to also enable additional filters such as EMA and SMA to help reduce the number of trades and thus, reduce the impact of the additional latency introduced by waiting for the close of the bar as confirmation.
Note on backtest accuracy over time:
Some users have observed that the accuracy for the backtest results tend to increase over time. This behavior is to be expected as the indicator will become more accurate as more historical data is added to the training set. More historical points of reference for the ML model means more options when selecting neighbors for the Approximate Nearest Neighbors algorithm. This effect should also be kept in mind when evaluating the backtest results for this indicator.
Note on "repainting":
To be clear, once a bar has closed, this indicator will NOT repaint. This is true for both the ML predictions and the Kernel estimate.
版本注释
- Fixed a problem involving inverted kernel alerts.
版本注释
- Renamed some variables to be less confusing and made various other improvements to the code's documentation
- Fixed a minor issue related to the Dynamic Exits mechanism
开源脚本
秉承TradingView的精神,该脚本的作者将其开源,以便交易者可以查看和验证其功能。向作者致敬!您可以免费使用该脚本,但请记住,重新发布代码须遵守我们的网站规则。
🚀 User Guides: ai-edge.io/
❤️ Premium Indicators: patreon.com/jdehorty
🎥 Tutorials: youtu.be/AdINVvnJfX4
🤖 Discord: discord.com/invite/djXT5sAPfQ
⏩ LinkedIn: linkedin.com/in/justin-dehorty
❤️ Premium Indicators: patreon.com/jdehorty
🎥 Tutorials: youtu.be/AdINVvnJfX4
🤖 Discord: discord.com/invite/djXT5sAPfQ
⏩ LinkedIn: linkedin.com/in/justin-dehorty
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。
开源脚本
秉承TradingView的精神,该脚本的作者将其开源,以便交易者可以查看和验证其功能。向作者致敬!您可以免费使用该脚本,但请记住,重新发布代码须遵守我们的网站规则。
🚀 User Guides: ai-edge.io/
❤️ Premium Indicators: patreon.com/jdehorty
🎥 Tutorials: youtu.be/AdINVvnJfX4
🤖 Discord: discord.com/invite/djXT5sAPfQ
⏩ LinkedIn: linkedin.com/in/justin-dehorty
❤️ Premium Indicators: patreon.com/jdehorty
🎥 Tutorials: youtu.be/AdINVvnJfX4
🤖 Discord: discord.com/invite/djXT5sAPfQ
⏩ LinkedIn: linkedin.com/in/justin-dehorty
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。