PINE LIBRARY
已更新 SPTS_StatsPakLib
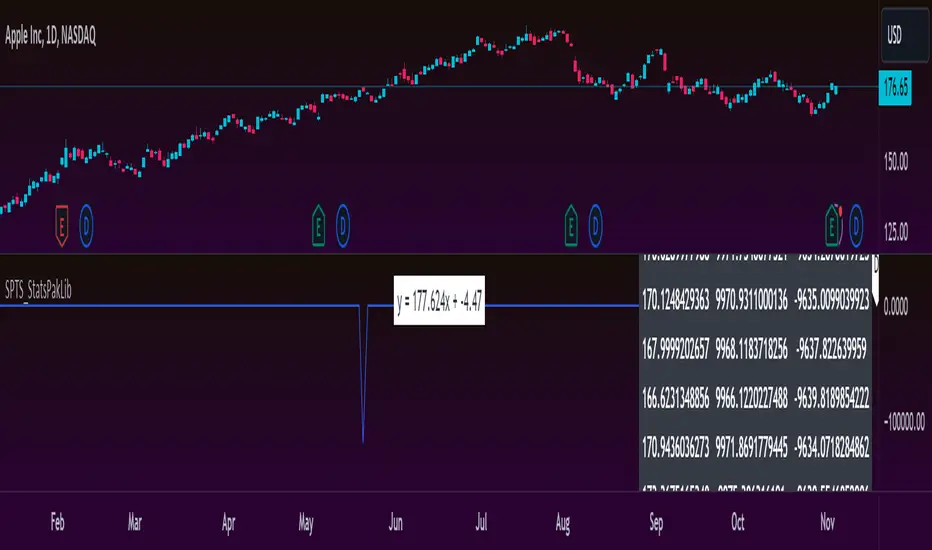
Finally getting around to releasing the library component to the SPTS indicator!
This library is packed with a ton of great statistics functions to supplement SPTS, these functions add to the capabilities of SPTS including a forecast function.
The library includes the following functions
One of the biggest added functionalities of this library is the forecasting function.
This function provides an autoregressive, trainable model that will export forecasted values to 3 arrays, one contains the autoregressed forecasted results, the other two contain the upper confidence forecast and the lower confidence forecast.
Hope you enjoy and find use for this!
Library "SPTS_StatsPakLib"
f_linear_regression(independent, dependent, len, variable)
TODO: creates a simple linear regression model between two variables.
Parameters:
independent (float)
dependent (float)
len (int)
variable (float)
Returns: TODO: returns 6 float variables
result: The result of the regression model
pear_cor: The pearson correlation of the regresion model
rsqrd: the R2 of the regression model
std_err: the error of residuals
slope: the slope of the model (coefficient)
intercept: the intercept of the model (y = mx + b is y = slope x + intercept)
f_multiple_regression(y, x1, x2, input1, input2, len)
TODO: creates a multiple regression model between two independent variables and 1 dependent variable.
Parameters:
y (float)
x1 (float)
x2 (float)
input1 (float)
input2 (float)
len (int)
Returns: TODO: returns 7 float variables
result: The result of the regression model
pear_cor: The pearson correlation of the regresion model
rsqrd: the R2 of the regression model
std_err: the error of residuals
b1 & b2: the slopes of the model (coefficients)
intercept: the intercept of the model (y = mx + b is y = b1 x + b2 x + intercept)
f_stanard_error(result, dependent, length)
x TODO: performs an assessment on the error of residuals, can be used with any variable in which there are residual values (such as moving averages or more comlpex models)
param x TODO: result is the output, for example, if you are calculating the residuals of a 200 EMA, the result would be the 200 EMA
dependent: is the dependent variable. In the above example with the 200 EMA, your dependent would be the source for your 200 EMA
Parameters:
result (float)
dependent (float)
length (int)
Returns: x TODO: the standard error of the residual, which can then be multiplied by standard deviations or used as is.
f_zscore(variable, length)
TODO: Calculates the z-score
Parameters:
variable (float)
length (int)
Returns: TODO: returns float z-score
f_effect_size(array1, array2)
TODO: Calculates the effect size between two arrays of equal scale.
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: returns the effect size (float)
f_confidence_interval(array1, array2, ci_input)
TODO: Calculates the confidence interval between two arrays
Parameters:
array1 (float[])
array2 (float[])
ci_input (float)
Returns: TODO: returns the upper_bound and lower_bound cofidence interval as float values
paired_sample_t(src1, src2, len)
TODO: Performs a paired sample t-test
Parameters:
src1 (float)
src2 (float)
len (int)
Returns: TODO: Returns the t-statistic and degrees of freedom of a paired sample t-test
two_tail_t_test(array1, array2)
TODO: Perofrms a two tailed t-test
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: Returns the t-statistic and degrees of freedom of a two_tail_t_test sample t-test
t_table_analysis(t_stat, df)
TODO: This is to make a qualitative assessment of your paired and single sample t-test
Parameters:
t_stat (float)
df (float)
Returns: TODO: the function will return 2 string variables and 1 colour variable. The 2 string variables indicate whether the results are significant or not and the colour will
output red for insigificant and green for significant
t_table_p_value(df, t_stat)
TODO: This performs a quantaitive assessment on your t-tests to determine the statistical significance p value
Parameters:
df (float)
t_stat (float)
Returns: TODO: The function will return 1 float variable, the p value of the t-test.
cor_of_array(array1, array2)
TODO: This performs a pearson correlation assessment of two arrays. They need to be of equal size!
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: The function will return the pearson correlation.
quadratic_correlation(src1, src2, len)
TODO: This performs a quadratic (curvlinear) pearson correlation between two values.
Parameters:
src1 (float)
src2 (float)
len (int)
Returns: TODO: The function will return the pearson correlation (quadratic based).
f_r2_array(array1, array2)
TODO: Calculates the r2 of two arrays
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: returns the R2 value
f_rsqrd(src1, src2, len)
TODO: Calculates the r2 of two float variables
Parameters:
src1 (float)
src2 (float)
len (int)
Returns: TODO: returns the R2 value
test_of_normality(array, src)
TODO: tests the normal distribution hypothesis
Parameters:
array (float[])
src (float)
Returns: TODO: returns 4 variables, 2 float and 2 string
Skew: the skewness of the dataset
Kurt: the kurtosis of the dataset
dist = the distribution type (recognizes 7 different distribution types)
implication = a string assessment of the implication of the distribution (qualitative)
f_forecast(output, input, train_len, forecast_length, output_array, upper_array, lower_array)
TODO: This performs a simple forecast function on a single dependent variable. It will autoregress this based on the train time, to the desired length of output,
then it will push the forecasted values to 3 float arrays, one that contains the forecasted result, 1 that contains the Upper Confidence Result and one with the lower confidence
result.
Parameters:
output (float)
input (float)
train_len (int)
forecast_length (int)
output_array (float[])
upper_array (float[])
lower_array (float[])
Returns: TODO: Will return 3 arrays, one with the forecasted results, one with the upper confidence results, and a final with the lower confidence results. Example is given below.
This library is packed with a ton of great statistics functions to supplement SPTS, these functions add to the capabilities of SPTS including a forecast function.
The library includes the following functions
- 1. Linear Regression (single independent and single dependent)
- 2. Multiple Regression (2 independent variables, 1 dependent)
- 3. Standard Error of Residual Assessment
- 4. Z-Score
- 5. Effect Size
- 6. Confidence Interval
- 7. Paired Sample Test
- 8. Two Tailed T-Test
- 9. Qualitative assessment of T-Test
- 10. T-test table and p value assigner
- 11. Correlation of two arrays
- 12. Quadratic correlation (curvlinear)
- 13. R Squared value of 2 arrays
- 14. R Squared value of 2 floats
- 15. Test of normality
- 16. Forecast function which will push the desired forecasted variables into an array.
One of the biggest added functionalities of this library is the forecasting function.
This function provides an autoregressive, trainable model that will export forecasted values to 3 arrays, one contains the autoregressed forecasted results, the other two contain the upper confidence forecast and the lower confidence forecast.
Hope you enjoy and find use for this!
Library "SPTS_StatsPakLib"
f_linear_regression(independent, dependent, len, variable)
TODO: creates a simple linear regression model between two variables.
Parameters:
independent (float)
dependent (float)
len (int)
variable (float)
Returns: TODO: returns 6 float variables
result: The result of the regression model
pear_cor: The pearson correlation of the regresion model
rsqrd: the R2 of the regression model
std_err: the error of residuals
slope: the slope of the model (coefficient)
intercept: the intercept of the model (y = mx + b is y = slope x + intercept)
f_multiple_regression(y, x1, x2, input1, input2, len)
TODO: creates a multiple regression model between two independent variables and 1 dependent variable.
Parameters:
y (float)
x1 (float)
x2 (float)
input1 (float)
input2 (float)
len (int)
Returns: TODO: returns 7 float variables
result: The result of the regression model
pear_cor: The pearson correlation of the regresion model
rsqrd: the R2 of the regression model
std_err: the error of residuals
b1 & b2: the slopes of the model (coefficients)
intercept: the intercept of the model (y = mx + b is y = b1 x + b2 x + intercept)
f_stanard_error(result, dependent, length)
x TODO: performs an assessment on the error of residuals, can be used with any variable in which there are residual values (such as moving averages or more comlpex models)
param x TODO: result is the output, for example, if you are calculating the residuals of a 200 EMA, the result would be the 200 EMA
dependent: is the dependent variable. In the above example with the 200 EMA, your dependent would be the source for your 200 EMA
Parameters:
result (float)
dependent (float)
length (int)
Returns: x TODO: the standard error of the residual, which can then be multiplied by standard deviations or used as is.
f_zscore(variable, length)
TODO: Calculates the z-score
Parameters:
variable (float)
length (int)
Returns: TODO: returns float z-score
f_effect_size(array1, array2)
TODO: Calculates the effect size between two arrays of equal scale.
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: returns the effect size (float)
f_confidence_interval(array1, array2, ci_input)
TODO: Calculates the confidence interval between two arrays
Parameters:
array1 (float[])
array2 (float[])
ci_input (float)
Returns: TODO: returns the upper_bound and lower_bound cofidence interval as float values
paired_sample_t(src1, src2, len)
TODO: Performs a paired sample t-test
Parameters:
src1 (float)
src2 (float)
len (int)
Returns: TODO: Returns the t-statistic and degrees of freedom of a paired sample t-test
two_tail_t_test(array1, array2)
TODO: Perofrms a two tailed t-test
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: Returns the t-statistic and degrees of freedom of a two_tail_t_test sample t-test
t_table_analysis(t_stat, df)
TODO: This is to make a qualitative assessment of your paired and single sample t-test
Parameters:
t_stat (float)
df (float)
Returns: TODO: the function will return 2 string variables and 1 colour variable. The 2 string variables indicate whether the results are significant or not and the colour will
output red for insigificant and green for significant
t_table_p_value(df, t_stat)
TODO: This performs a quantaitive assessment on your t-tests to determine the statistical significance p value
Parameters:
df (float)
t_stat (float)
Returns: TODO: The function will return 1 float variable, the p value of the t-test.
cor_of_array(array1, array2)
TODO: This performs a pearson correlation assessment of two arrays. They need to be of equal size!
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: The function will return the pearson correlation.
quadratic_correlation(src1, src2, len)
TODO: This performs a quadratic (curvlinear) pearson correlation between two values.
Parameters:
src1 (float)
src2 (float)
len (int)
Returns: TODO: The function will return the pearson correlation (quadratic based).
f_r2_array(array1, array2)
TODO: Calculates the r2 of two arrays
Parameters:
array1 (float[])
array2 (float[])
Returns: TODO: returns the R2 value
f_rsqrd(src1, src2, len)
TODO: Calculates the r2 of two float variables
Parameters:
src1 (float)
src2 (float)
len (int)
Returns: TODO: returns the R2 value
test_of_normality(array, src)
TODO: tests the normal distribution hypothesis
Parameters:
array (float[])
src (float)
Returns: TODO: returns 4 variables, 2 float and 2 string
Skew: the skewness of the dataset
Kurt: the kurtosis of the dataset
dist = the distribution type (recognizes 7 different distribution types)
implication = a string assessment of the implication of the distribution (qualitative)
f_forecast(output, input, train_len, forecast_length, output_array, upper_array, lower_array)
TODO: This performs a simple forecast function on a single dependent variable. It will autoregress this based on the train time, to the desired length of output,
then it will push the forecasted values to 3 float arrays, one that contains the forecasted result, 1 that contains the Upper Confidence Result and one with the lower confidence
result.
Parameters:
output (float)
input (float)
train_len (int)
forecast_length (int)
output_array (float[])
upper_array (float[])
lower_array (float[])
Returns: TODO: Will return 3 arrays, one with the forecasted results, one with the upper confidence results, and a final with the lower confidence results. Example is given below.
版本注释
v2Updated with a simplified test of normality that accepts float variables instead of arrays and will just output the distribution type.
Also added a quadratic forecast function.
Added:
simplified_test_of_normality(len, src)
TODO: tests the normal distribution hypothesis as above but only does not require the use of arrays.
Parameters:
len (int)
src (float)
Returns: TODO: returns only 1 variable, the distribution type (normal, platykurtic, etc.)
f_quadratic_forecast(output, input, train_len, forecast_length, result_array, ucl_array, lcl_array)
TODO: Like above, This performs a simple forecast function on a single dependent variable with a strong quadratic relationship to its independent variable.
It will autoregress this based on the train time, to the desired length of output,then it will push the forecasted values to 3 float arrays,
one that contains the forecasted result, 1 that contains the Upper Confidence Result and one with the lower confidence result.
Parameters:
output (float)
input (float)
train_len (int)
forecast_length (int)
result_array (float[])
ucl_array (float[])
lcl_array (float[])
Returns: TODO: Will return 3 arrays, one with the forecasted results, one with the upper confidence results, and a final with the lower confidence results. Example is given below.
版本注释
v3Added:
f_linear_regression_array(independent, dependent)
TODO: Performs linear regression on two, equal sized arrays
Parameters:
independent (float[])
dependent (float[])
Returns: TODO: Returns 5 floats, R2, Correlation, standard error, slope and intercept
f_dickey_fuller_test(change_x, lagged_x, len)
: Performs a basic Dickey Fuller Test
Parameters:
change_x (float)
lagged_x (float)
len (int)
Returns: : returns t-statistic as float and significance and bool (true or false)
Removed:
f_quadratic_forecast(output, input, train_len, forecast_length, result_array, ucl_array, lcl_array)
TODO: Like above, This performs a simple forecast function on a single dependent variable with a strong quadratic relationship to its independent variable.
It will autoregress this based on the train time, to the desired length of output,then it will push the forecasted values to 3 float arrays,
one that contains the forecasted result, 1 that contains the Upper Confidence Result and one with the lower confidence result.
版本注释
v4Added:
f_triple_regression(y, x1, x2, x3, len)
performs a multiple regression with up to 3 independent variables and 1 dependent variable
Parameters:
y (float)
x1 (float)
x2 (float)
x3 (float)
len (int)
Returns: result, error, p value, r2, coefficients for b1, b2, b3 and intercept (b0)
knn_regression(y, x, len, last_instance_or_cluster_or_avg, clusters, tolerance)
performs up to 3 types of KNN based regression assessments
Parameters:
y (float)
x (float): the independent variable (x), dependent (y), the assessment type in string ("Last Instance" vs "Cluster" vs "Avg"),
# of clusters and tolerance level for looking at clusters within a specified range.
len (int)
last_instance_or_cluster_or_avg (string)
clusters (int)
tolerance (float)
Returns: result, error of estimates, correlation and basic R2
ANOVA(group1, group2, group3, len)
performs a 3 way ANOVA analysis of 3 independent variables. Returns the F Statistic and the significance (P value)
Parameters:
group1 (float)
group2 (float)
group3 (float)
len (int)
Returns: F Statistic and P value
Updated:
f_linear_regression(dependent, independent, len)
creates a simple linear regression model between two variables.
Parameters:
dependent (float)
independent (float)
len (int)
Returns: returns 6 float variables
result: The result of the regression model
pear_cor: The pearson correlation of the regresion model
rsqrd: the R2 of the regression model
std_err: the error of residuals
slope: the slope of the model (coefficient)
intercept: the intercept of the model (y = mx + b is y = slope x + intercept)
Pine脚本库
秉承TradingView的精神,作者已将此Pine代码作为开源库发布,以便我们社区的其他Pine程序员可以重用它。向作者致敬!您可以私下或在其他开源出版物中使用此库,但在出版物中重用此代码须遵守网站规则。
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。
Pine脚本库
秉承TradingView的精神,作者已将此Pine代码作为开源库发布,以便我们社区的其他Pine程序员可以重用它。向作者致敬!您可以私下或在其他开源出版物中使用此库,但在出版物中重用此代码须遵守网站规则。
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
免责声明
这些信息和出版物并非旨在提供,也不构成TradingView提供或认可的任何形式的财务、投资、交易或其他类型的建议或推荐。请阅读使用条款了解更多信息。