(Quartile Vol.; Vol. Aggregation; Range US Bars; Gaps) [Kioseff]Hello!
This indicator is a multifaceted tool that's, hopefully, useful for price action and volume analysis.
(This script makes use of the newly introduced "text_font" parameter)
With this script you'll have access to:
Range US Chart
Volume Aggregation Chart
Gaps Chart
Volume by Quartile
Consequently, you'll have access to:
First Quartile Volume Threshold
Second Quartile Volume Threshold
Third Quartile Volume Threshold
90th Percentile Volume Threshold
Fourth Quartile Volume Threshold
Q2 - Q1 Dispersion
Q3 - Q2 Dispersion
Q4 - Q3 Dispersion
Quartile Deviation
Interquartile Range
Avg. "n" bar return following "high" volume
Avg. "n" bar positive return following "high" volume
Avg. "n" bar negative following "high" volume
# of Positive Returns Following a Gap
# of Negative Returns Following a Gap
# of Gaps
# of Up Gaps
# of Down Gaps
Average # of bars to fill Up Gaps
Average # of bars to dill Down Gaps
Average Gap Up % increase
Average Gap Down % decrease
Cumulative % increase of all Up Gaps
Cumulative % decrease of all Down Gaps
Sort gaps by distance from price
Hide gaps that price substantially deviates from (gaps will reappear when price trades near the gap)
Segment Range US bars by date
Manually configure Range US price thresholds
Identify "congestion" areas with Range US bars
Range US Levels that must be exceeded for a new Range US bar to produce
Manually configure cumulative volume threshold for Volume Aggregation bars
Segment Volume Aggregation bars by date
Largest Volume Aggregation bar increases
Largest Volume Aggregation bar decreases
Calculate log returns after "high" volume sessions
Quartile Volume
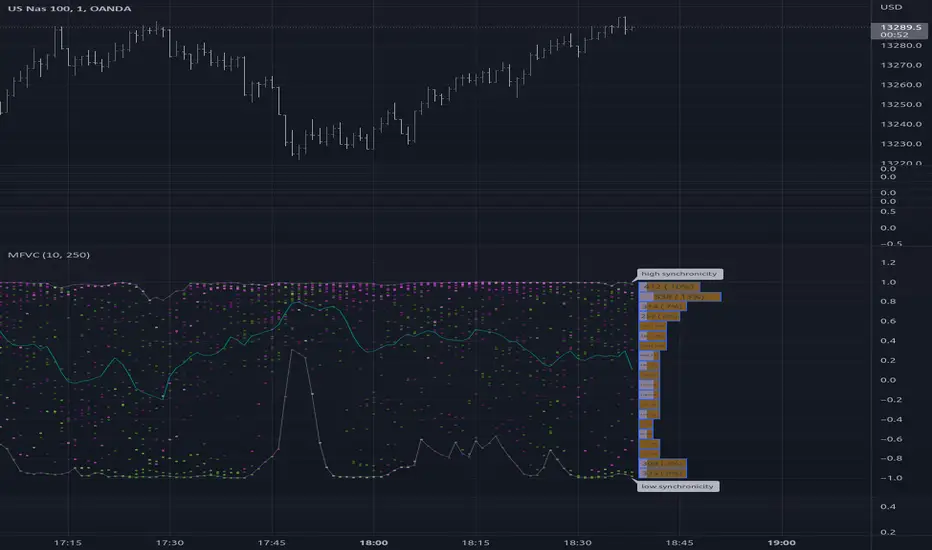
The Quartile Volume portion of the script segments price/volume intervals by quartile.
The image above shows features of the indicator.
For statistics, the following metrics are recorded:
First Quartile
Second Quartile
Third Quartile
90th Percentile
Fourth Quartile
Q2 - Q1 Dispersion
Q3 - Q2 Dispersion
Q4 - Q3 Dispersion
Quartile Deviation
Interquartile Range
Color-coordinated price bars (by volume quartiles)
The percent rank for the volume of the current bar
Avg. "n" bar return following "high" volume
Avg. "n" bar positive return following "high" volume
Avg. "n" bar negative following "high" volume
The script colors bars via gradient.
By default, bars are colored lime when volume for the interval is "high" (exceeds upper quartile thresholds). The greener the bar, the higher the volume for the interval.
Bars are colored red when volume for the interval is "low" (fails to exceed lower quartile thresholds). The redder the bar, the lower the volume for the interval.
Naturally, brownish-colored bars reflect a volume interval that concluded near the median.
The image above exemplifies the process. This feature might be useful to categorize / objectively define high-volume clusters, low-volume clusters, high-volume price moves, low-volume price moves, etc.
For greater precision, you can select to color bars by volume quartile they belong to.
The image above shows color-coordinated price bars. More details shown in the image.
Additionally, you can select to plot the quartile/percentile that a price bar belongs to on the chart.
The image above shows price bars numbered by the volume quartile they belong to.
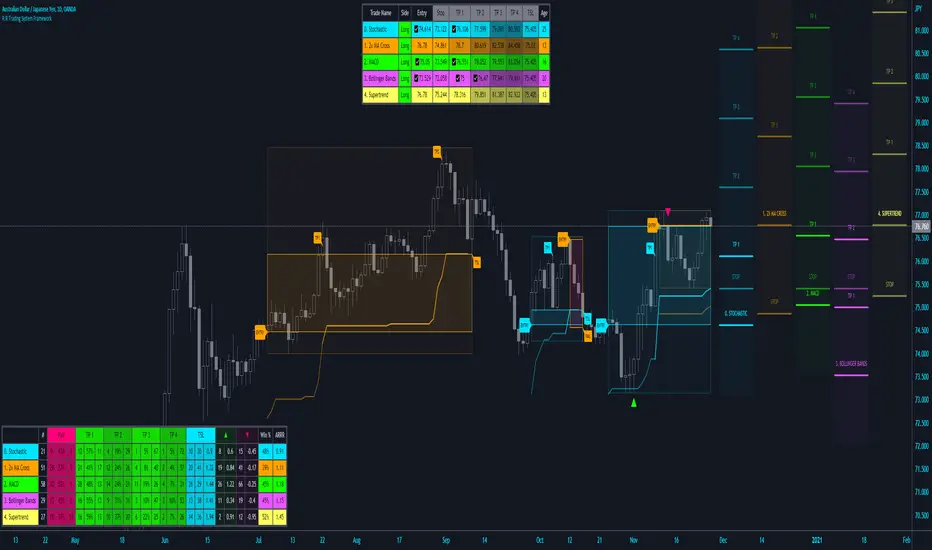
The script will distinguish successive 90th percentile violations, superimpose a linear regression channel atop the data sequence, and record pertinent statistics.
The image above shows the process.
Lastly, the user can plot an anchored VWAP using a built-in time function.
The image above shows the anchored VWAP.
Range US Chart
A Range US chart operates irrespective of time and volume - simply - bars produce after a user-defined price move is achieved/exceeded in either direction. A range us chart produces “trend candles” and “reversal candles”. A reversal candle always moves against the most immediate bar; a trend candle always moves in favor of the most immediate bar. The user defines the dollar amount price must travel up/down for a trend candle to fulfill, and for a reversal candle to fulfill.
Note: if a “down reversal” candle (red) Is produced, it’s impossible for the next candle to also be a down reversal candle - for the downside move to continue the criteria for a down trend candle must be fulfilled. Similarly, if an “up reversal” candle (green) Is produced, it’s impossible for the next candle to also be an up reversal candle - for the upside move to continue, the criteria for an uptrend trend candle must be fulfilled. Consequently, Range US bars frequently trade at the same level for extended periods. This is intentional, as this chart type is theorized to “filter noise” (whether Range US charts fulfill this theory is to your discretion).
Lastly, if an up trend candle (green) is produced, the next candle cannot be up a reversal up candle - only a trend up candle or reversal down candle can produce - vice versa for a trend down candle (the subsequent candle cannot be a reversal down candle). In this sense, an uptrend continues on successive trend up candles; a down trend continues on successive trend down candles.
The image above exemplifies Range US chart functionality.
The lower-right stats table shows the requisite price move for a "Trend" candle to produce and for a "Reversal" candle to produce.
The default settings for this chart time automatically calculate the required "Trend" candle price move and the required "Reversal" candle price move. However, both settings are configurable.
The image above shows manually configured parameters for a trend bar and reversal bar to produce. This feature allows the user to replicate the Range US chart hosted on extrinsic charting platforms.
However, please consider that this script does not use tick data; 1-minute OHLC data is used for calculations.
Consequently, configuring the trend bar and reversal bar requirement too low may return inaccurate data. For instance, if you set trend candles to form after a $1 price move then trend candles will form if price moves up $1 from a green Range US bar or down $1 from a red Range US bar. This is sufficient for lower priced assets; however, if you were trading, for instance, Bitcoin - a $1 price move can happen numerous times in one minute. This script can’t plot bars and record data until a 1-minute bar closes and a new 1-minute bar opens. Further, if Bitcoin moves up $1 twenty times and down $1 twenty times in a 1-minute bar - your Range US chart will record such variations as one price move. This data is inaccurate and likely useless.
To counter this quandary, a warning message will appear if you configure trend bar price moves or reversal bar price moves too low.
The image above shows the concealable warning message.
The image above is a flow diagram (made with shaky hands) illustrating the Range US bar formation process.
A google search will return additional information on the Range US chart type.
Volume Aggregation Bars
TradingView user and member of the TradingView Discord server @ferreirajames informed me of the Volume Aggregation chart type. The user commented in the "Suggestions" channel for the TradingView Discord server asking for the Volume Aggregation chart type. As an interim fix, I tried my hand at recreating the process, which is available in this script.
Similar to the Range US chart type, Volume Aggregation bars aren’t bound to a time-axis; the bars form after a user-defined, cumulative amount of volume is achieved or exceeded. Consequently, once the cumulative amount of volume is achieved or exceeded - a bar is produced at the corresponding price level.
Underlying theory: The chat type is conducive to identifying price levels where traders are “trapped”. Whether the process adequately distinguishes this circumstance is to your discretion.
The image above exemplifies the Volume Aggregation chart type.
Regardless of the current price, Volume Aggregation bars for after a requisite amount of volume is achieved/exceeded. Tick data isn't used; therefore, remainder values are carry over.
By default, the script automatically calculates a proportional cumulative volume total to dictate the formation of Volume Aggregation bars. However, the cumulative threshold is configurable.
The image above shows Volume Aggregation bars forming subsequent a user-defined cumulative volume total being exceeded.
Note: This chart type uses OHLC data from the timeframe of your chart. Therefore, for instance, setting the volume threshold too low will produce inaccurate, useless data.
A warning message will appear for such occurrence.
Gaps
The indicator incorporates a "Gaps" chart type.
The image above shows accompanying features.
A list of all unfilled gaps is accessible - gaps for this list are sorted by distance from current price.
Partially filled gaps are displayed in the corresponding gap box - the percentage amount the gap was filled is also displayed.
Gap statistics show:
# of Gaps
# of Up Gaps
# of Down Gaps
Average # of bars to fill Up Gaps
Average # of bars to dill Down Gaps
Average Gap Up % increase
Average Gap Down % decrease
Cumulative % increase of all Up Gaps
Cumulative % decrease of all Down Gaps
Naturally, there may be gaps formed thousands of bars ago that aren't close to price. Showing these gaps on the chart will "scrunch" the y-axis and make prices indistinguishable.
I've added a setting that allows the user to hide gaps that are "n" % away from the current price. The gap, if unfilled, will reappear when price trades within the user-defined percentage.
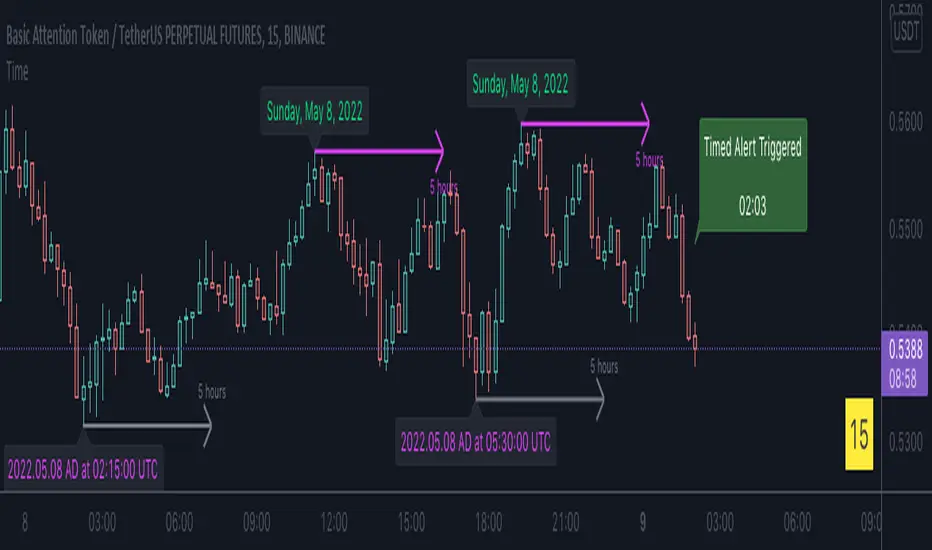
The image above shows an example. There's an unfilled down gap that's "hidden" because the current price is a further % away from price than what I've specified in the settings (1%). When prices trade back within 1% of the gap - it will reappear.
The image above shows the process in action. Prices moved back within 1% (can be any %) of the gap; therefore, it reappeared on the chart.
You can also set the % distance a gap must achieve for it to be considered a gap, recorded and plotted. Additionally, you can select to "visualize" gaps. Similar to the Range US chart and the Volume Aggregation chart, this setting will bars reflecting the most recent sequence of gaps - date and percentage distance of the gap are superimposed atop the bar.
Let me know if there's anything else you'd like included!
Note: The initial compilation time for this script is.... high. However, once the script's compiled, calculation load times are quick and you can sift through assets and timeframes relatively quick.
There's also a setting to "Improve Load Times" in the user-inputs table. This setting only improves the load times for post-compilation calculations and plots. The initial compilation load time is unchanged. Simply, once the indicator has "first loaded", all subsequent loads are quick.
Thank you! (:
Pine Script®指标