EMA + RSI Autotrade Webhook - VarunOverview
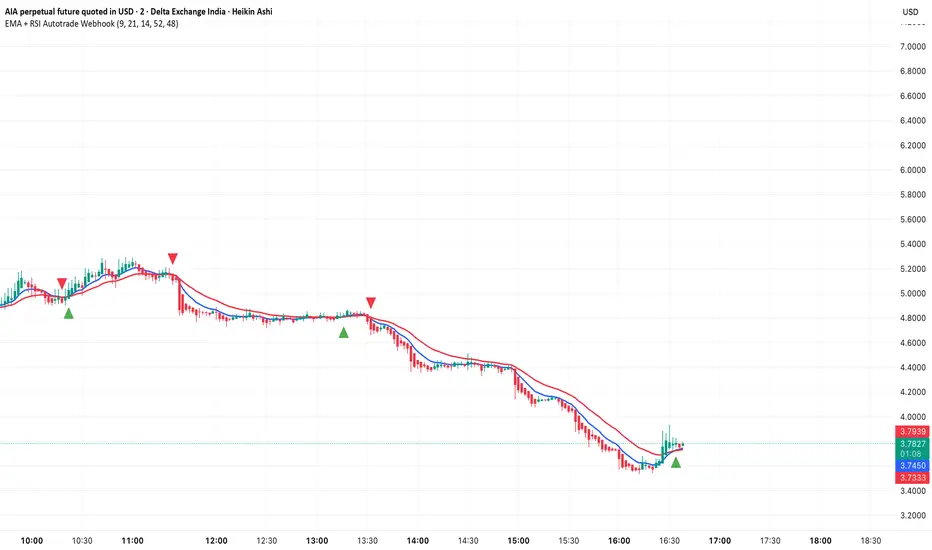
The EMA + RSI Autotrade Webhook is a powerful trend-following indicator designed for automated crypto futures trading. This indicator combines the reliability of Exponential Moving Average (EMA) crossovers with RSI momentum filtering to generate high-probability buy and sell signals optimized for webhook integration with crypto exchanges like Delta Exchange, Binance Futures, and Bybit.Key Features
Simple & Effective: Uses proven EMA 9/21 crossover strategy
RSI Momentum Filter: Eliminates low-probability trades in ranging markets
Webhook Ready: Two clean alerts (LONG Entry, SHORT Entry) for seamless automation
Exchange Compatible: Works with Delta Exchange, 3Commas, Alertatron, and other webhook platforms
Zero Lag Signals: Real-time alerts on crossover confirmation
Visual Clarity: Clean chart markers for easy signal identification
How It Works
Entry Signals:
LONG Entry: Triggers when EMA 9 crosses above EMA 21 AND RSI is above 52 (bullish momentum confirmed)
SHORT Entry: Triggers when EMA 9 crosses under EMA 21 AND RSI is below 48 (bearish momentum confirmed)
Technical Components:
Fast EMA: 9-period (tracks short-term price action)
Slow EMA: 21-period (identifies primary trend)
RSI: 14-period (confirms momentum strength)
RSI Long Threshold: 52 (filters weak bullish signals)
RSI Short Threshold: 48 (filters weak bearish signals)
Best Use Cases
Crypto Futures Trading: Bitcoin, Ethereum, Altcoin perpetual contracts
Automated Trading Bots: Integration with Delta Exchange webhooks, TradingView alerts
Timeframes: Optimized for 15-minute charts (works on 5min-1H)
Markets: Trending crypto markets with clear directional moves
Risk Management: Best used with 1-2% stop loss per trade (managed externally)
Webhook Automation Setup
Add indicator to your TradingView chart
Create alerts for "LONG Entry" and "SHORT Entry"
Configure webhook URL from your exchange (Delta Exchange, Binance, etc.)
Use alert message: Entry LONG {{ticker}} @ {{close}} or Entry SHORT {{ticker}} @ {{close}}
Exchange automatically reverses positions on opposite signals
Advantages
✅ No manual trading required - fully automated
✅ Eliminates emotional trading decisions
✅ Catches trending moves early with EMA crossovers
✅ RSI filter reduces whipsaws in choppy markets
✅ Works 24/7 without monitoring
✅ Simple two-alert system (easy to manage)
✅ Compatible with multiple exchanges via webhooksStrategy Philosophy
This indicator follows a trend-following with momentum confirmation approach. By waiting for both EMA crossover AND RSI confirmation, it ensures you're entering trades with genuine momentum behind them, not just random price noise. The tight RSI thresholds (52/48) keep you aligned with the prevailing trend.Recommended Settings
Timeframe: 15-minute (primary), 5-minute (scalping), 1-hour (swing)
Markets: BTC/USDT, ETH/USDT, high-liquidity altcoin perpetuals
Position Sizing: 100% capital per signal (exchange manages reversals)
Stop Loss: 2% (managed via exchange or external bot)
Leverage: 1-2x for conservative approach, up to 5x for aggressive
Important Notes
⚠️ This indicator generates entry signals only - position reversals are handled automatically by your exchange
⚠️ Always backtest on historical data before live trading
⚠️ Use proper risk management and position sizing
⚠️ Best performance in trending markets; may generate false signals in tight ranges
⚠️ Requires TradingView Premium or higher for webhook functionalityTags
cryptocurrency futures automated-trading ema-crossover rsi webhook delta-exchange tradingview-alerts trend-following momentum bitcoin ethereum crypto-bot algo-trading 15-minute-strategy
Pine Script®指标